Bienvenue dans le troisième épisode dans notre dossier d’introduction à la programmation sur Python. Vous avez vu dans l’épisode précédent les différents opérateurs sur Python ainsi que le fonctionnement des boucles et différentes fonctions utiles sur Python. Dans cette partie vous allez découvrir deux étapes indispensables à tout projet de machine learning: le data cleaning et le data processing
Import des données:
Préalablement aux opérations liées aux données en Python, telles que le nettoyage, la transformation et la visualisation, il est nécessaire de les importer.
Pour cela, nous utilisons le module Pandas. Développé pour apporter à Python les outils nécessaires pour manipuler de gros volumes de données. Ce module a pour objectif de devenir le meilleur outil de manipulation de données : à la fois performant, facile d’utilisation et flexible. Pandas est aujourd’hui le module le plus utilisé pour gérer des bases de données aux formats : CSV, Excel, …
Fichier csv :
L’un des types de données les plus courants est le format CSV, qui est un acronyme pour comma separated value (valeurs séparées par des virgules).
La structure générale des fichiers CSV utilise des lignes comme observations et des colonnes comme attributs.
Voici la procédure à suivre pour lire des fichiers CSV :
Il est également possible d’ajouter d’autres arguments à la fonction pd.read_csv :
– L’argument sep dans la fonction permettant de préciser le type de séparation pour la lecture de nos données (ex : , / ; / – …).
– L’argument header détermine le numéro de la ligne qui contient les noms des variables ; par défaut, header = 0.
– L’argument index_col permet de définir une colonne du DataFrame comme index.
Fichier Excel :
Les données Excel sont avec les fichiers CSV les plus couramment utilisés.
Voici la procédure à suivre avec la fonction pd.ExcelFile():
Si nous ne spécifions pas de nom de feuille, c’est la première qui est affichée par défaut. Si nous voulons afficher une feuille en particulier nous pouvons le faire en utilisant la dernière ligne de code ci-dessus en précisant le nom de la feuille.
Avant de procéder à la modélisation des données il est nécessaire de passer par un nombre d’étapes préliminaires qui sont essentielles à un projet de machine Learning. Bien que fastidieuses, il ne faut surtout pas les mettre de côté car elles sont garantes de la qualité de notre modélisation. On parle souvent de « garbage in – garbage out ». Un modèle dont la qualité des données n’est pas optimale, ne pourra pas réaliser de bonnes prédictions.
Les étapes préliminaires, aussi appelées étapes de data pre-processing, recouvrent ainsi les étapes de vérification de l’état, du nettoyage – data cleaning – et de la préparation de données.
Vérification:
Avant toute chose il est important d’avoir une vision d’ensemble sur les données. Par exemple, la préparation de nos données va dépendre du type de variables. En présence de données numériques il est intéressant de connaître l’intervalle des valeurs, leur moyenne, leur écart-type et autre statistique de base. Cette étape de vérification comprend également la vérification de l’existence de duplicatas.
Data Cleaning
Traitement des données manquantes
Les bases de données auxquelles nous sommes confrontés au quotidien comprennent très souvent des données manquantes. Nombreuses sont les raisons derrière cette problématique : des erreurs de typographie qui ont donné lieu à des retraits de données, une absence initiale de données etc.
La suppression de données sera la méthode utilisée en dernier recours car elle engendre une perte importante d’informations. Plus on possèdera d’informations, meilleure sera la qualité de prédiction de notre modèle.
Néanmoins dans certains cas, on optera tout de même pour cette stratégie. En règle générale, on fera le choix de supprimer une ligne de données lorsque celle-ci est truffée de données manquantes, en particulier si les variables les plus importantes sont manquantes, la target par exemple. On pourra décider de supprimer une variable en entier, si la grande majorité des données sont absentes et que cette variable a peu de poids sur la variable prédite.
On préfèrera à la suppression de ces données, l’imputation de valeur. Cette [cm_tooltip_parse] méthode [/cm_tooltip_parse] permet de réduire la perte d’information. Plusieurs méthodes s’offrent à nous. On pourra par exemple imputer pour les variables numériques la valeur médiane ou moyenne de cette variable (on fera attention aux valeurs extrêmes si l’on impute la moyenne). Si l’on a à faire à une variable catégorielle, on pourra imputer la valeur majoritaire au sein de la variable, en utilisant le mode.
Une méthode d’imputation plus fine sera d’imputer en tenant compte des valeurs au sein des autres variables. On pourra ainsi calculer la moyenne, la médiane, le mode par groupes d’individus au sein du DataFrame pour affiner la valeur à imputer.
Valeurs aberrantes /Outliers
Un outlier ou valeur aberrante correspond à une valeur éloignée de la distribution de la variable. Cela pourra être dû à une erreur de typographie ou à une erreur de mesure mais cela pourra également être une valeur extrême. On parle couramment de valeur extrême, pour désigner une valeur non erronée qui s’éloigne néanmoins fortement du reste des valeurs de la variable.
Une façon assez simple de détecter ces valeurs est de réaliser un box-plot pour chacune des variables. Un box plot est un graphique sous forme de rectangle où sont décrites les statistiques de la variables (les quartiles (Q1, médiane, Q3). Les bornes du graphique délimitent les valeurs selon la distribution de la variable. Au-delà de ces extrémités, ces valeurs sont considérées comme des valeurs aberrantes.
Dans le cadre d’un projet de Machine Learning on fera souvent le choix de supprimer une valeur aberrante. En effet, pour obtenir une meilleure qualité de prédiction il est nécessaire de traiter ces données car un modèle pourra être très sensible aux données extrêmes ce qui va biaiser les prédictions.
Data processing
Encodage binaire
Lorsque l’on est en présence de données catégorielles textuelles, il est nécessaire d’encoder nos variables. On parle d’encodage binaire lorsque l’on encode une variable en deux catégories, en général en 0, 1. Par exemple, une variable décrivant le sexe d’une personne pourra être encodé en 0, 1. Une variable catégorielle (avec plus que deux catégories) pourra également être encodé, selon le nombre de catégories qui la compose.
La stratégie habituellement adoptée est néanmoins celle de la création de dummies. A partir d’une variable, pour les n-catégories qui la compose, on créera n-1 colonnes encodées de façon binaire (0-1) correspondant, chacune correspondant à une des catégories comprises dans la variable. On retire une colonne car cette colonne peut être déduite des autres. Il est important que les variables ne soient pas corrélées pour la qualité de la prédiction.
Feature Scaling : Normalisation et standardisation
Les variables qui composent un DataFrame ne sont pas toujours à la même échelle. L’âge et la taille par exemple n’ont pas la même mesure. Ainsi, pour équilibrer le poids de chacune des variables au sein du DataFrame, il conviendra de « scaler » les variables autrement dit les mettre à la même échelle. Cette étape est très importante notamment dans les modèles qui utilisent des mesures de distance linéaire et qui seront fortement impactées par ce genre de déséquilibre.
Deux cas de figure se présentent à nous : lorsque la distribution d’une variable suit une loi normale et lorsqu’elle ne suit pas une loi normale.
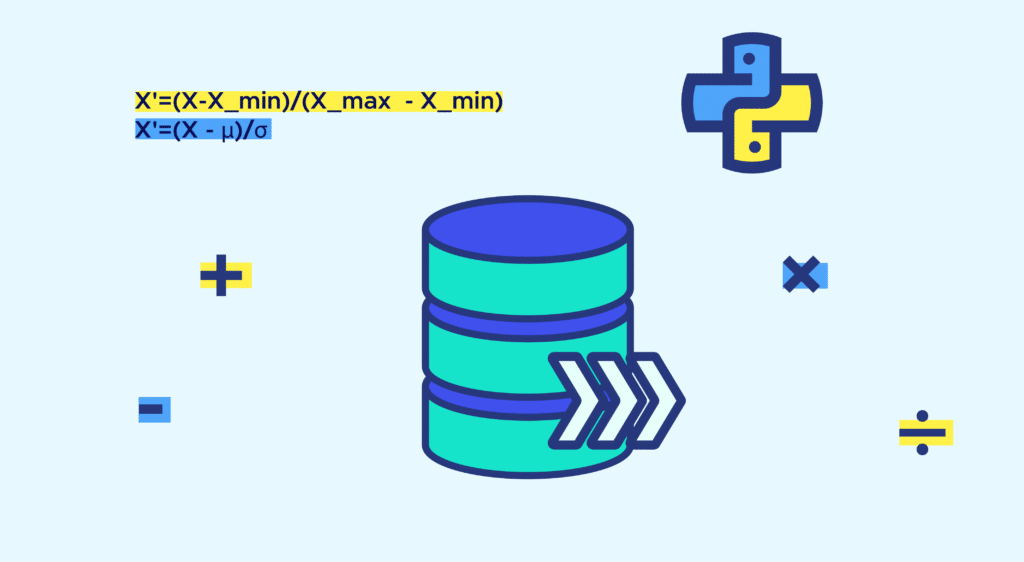
Si elle ne suit pas une loi normale il convient d’appliquer un « min-max scaling », ses valeurs seront dans un intervalle [0,1].
X’=(X-X_min)/(X_max – X_min)
Si la variable suit une distribution normale, on parlera de standardisation. Pour ce faire on soustrait la moyenne et on divise par l’écart type.
X’=(X – μ)/σ
Où µ ou σ sont la moyenne et l’écart type de la distribution.
Conclusion:
Voici donc les jalons principaux de l’étape de data pre-processing. Il existe évidemment d’autres procédures que vous pourrez appliquer à vos bases de données de façon plus spécifique ! Plus les variables de notre DataFrame sont bien traitées et plus faciles seront les étapes de création de variables et de modélisation.






