
Pendant la navigation sur internet, de nombreux sites ne permettent pas de directement sauvegarder des données pour un usage personnel. La solution la plus simple dans ce cas de figure est simplement de copier-coller manuellement les données, ce qui peut vite devenir fastidieux et chronophage. C’est la raison pour laquelle on a souvent recours aux techniques de Web Scraping pour extraire des données de sites web.
Le Web Scraping est l’automatisation du processus d’extraction quasi-automatique des données des sites Web. Cette opération se fait à l’aide d’outils de scraping souvent connus sous le nom de web scrapers. Ces derniers permettent alors de charger et d’extraire des données spécifiques des sites Web en fonction des besoins des utilisateurs. Ils sont le plus souvent conçus sur mesure pour un seul site et configurés ensuite pour fonctionner avec d’autres sites Web ayant la même structure.
Avec le langage de programmation Python, les outils les plus utilisés dans le domaine du Web Scraping sont BeautifulSoup et Scrapy Crawler. Dans cet article, nous allons présenter quelques différences entre ces deux outils et nous concentrer sur Scrapy par la suite.
Web Scraping vs Web Crawling
Avant de rentrer dans le vif du sujet il est assez intéressant de comprendre la différence entre les techniques de Web Scraping et Web Crawling :
- Le Web Scraping
Le Web Scraping utilise des robots pour analyser de manière programmatique une page web afin d’en extraire du contenu. Avec le Web Scraping il est donc nécessaire de chercher les données de manière précise.
Exemple d’extraction de données sur le Web : Extraction des prix de divers produits spécifiques sur le site Amazon ou tout autre site d’e-commerce.
- Le Web Crawling
Le terme crawling est utilisé comme une analogie avec la façon dont une araignée rampe (c’est aussi la raison pour laquelle les « web crawlers » sont souvent appelés des spiders). Les outils de Web Crawling vont également utiliser des robots (bots appelés crawlers) pour parcourir systématiquement le World Wide Web, généralement dans le but de l’indexer. Il s’agit de regarder une page dans son intégralité et de référencer tous les éléments s’y trouvant, y compris la dernière lettre et le dernier point de la page. Les bots utilisés vont alors, pendant leur navigation à travers des tas de données et d’informations, localiser et récupérer les informations qui se trouvent dans les couches les plus profondes.
Comme exemple d’outils de Web Crawling on peut citer tous les moteurs de recherche tels que Google, Yahoo ou Bing. Ces derniers explorent les pages web et utilisent les informations extraites pour indexer ces dernières.
BeautifulSoup vs Scrapy
Poursuivons avec une rapide comparaison entre BeautifulSoup et Scrapy, les deux bibliothèques de Web Scraping les plus utilisées.
- BeautifulSoup
BeautifulSoup est une librairie Python très populaire qui permet d’analyser les documents HTML ou XML de manière à les décrire en utilisant une structure arborescente ou sous forme de dictionnaire. Cette dernière permet alors de retrouver et d’extraire facilement des données spécifiques des pages Web. BeautifulSoup est assez facile à prendre en main et dispose d’une bonne documentation complète qui permet d’apprendre facilement.
Les avantages de BeautifulSoup :
- Très bonne documentation (très utile lorsqu’on débute).
- Grande communauté d’utilisateurs.
- Facile à apprendre et à maîtriser pour les débutants.
Inconvénients :
- Dépendance d’autres librairies Python externes.
- Scrapy
Scrapy est un framework complet open-source et est parmi les bibliothèques les plus puissantes utilisées pour l’extraction de données sur internet. Scrapy intègre de manière native des fonctions pour extraire des données de sources HTML ou XML en utilisant des expressions CSS et XPath.
Quelques avantages de Scrapy :
- Efficace en termes de mémoire et de CPU.
- Fonctions intégrées pour l’extraction de données.
- Facilement extensible pour des projets de grande envergure.
- Assez performant et rapide par rapport aux autres bibliothèques.
Comme inconvénients, on peut citer la faible documentation qui peut décourager les débutants.
Pour résumer tous les points évoqués ci-dessus :
| Scrapy | BeautifulSoup |
|---|---|
|
|

Architecture de Scrapy
À la création d’un projet, différents fichiers vont permettre d’interagir avec les principaux composants de Scrapy. On peut voir ci-dessous l’architecture de Scrapy telle que décrite dans la documentation officielle :
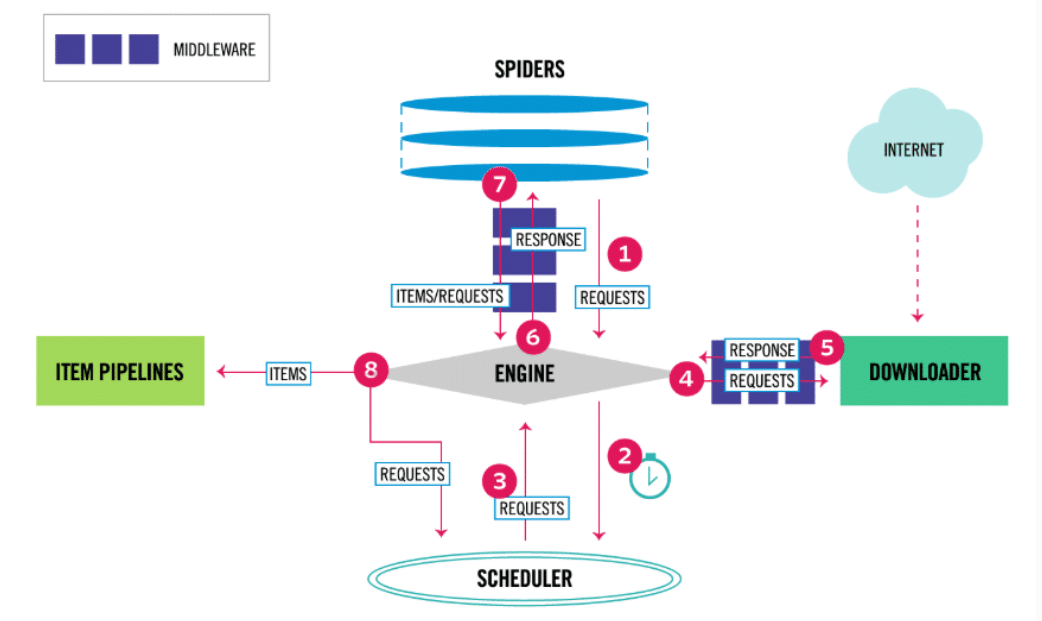
En analysant le diagramme de l’architecture de Scrapy, nous voyons que son élément central, l’engine ou moteur, qui contrôle quatre composants exécutifs :
- Les Spiders
- Les Item Pipelines
- Le Downloader
- Le Scheduler
Au début du processus, la communication s’effectue à travers les Spiders qui vont permettre de transmettre des requêtes (contenant les URL à scrapper et les informations à extraire) à l’engine. C’est ce dernier qui va transmettre la requête au planificateur (Scheduler) pour l’enregistrer dans la file d’attente (si plusieurs URLs sont transmises). Le moteur (Engine) va également recevoir des requêtes du Scheduler qui a ordonné les tâches précédemment pour les transmettre au module Downloader, qui télécharge le code HTML de la page et le transforme en un objet Response. L’objet response est ensuite transmis au Spider, puis au module ItemPipeline. Le processus va ainsi se répéter pour les différents liens URL des pages web.
On peut donc désormais mieux définir les rôles des composantes:
- Spiders : Les classes définissant les différentes méthodes de scrapping par les utilisateurs. Les méthodes sont alors invoquées par Scrapy lorsque cela est nécessaire
- Scrapy Engine : Permet de contrôler le flux de données et déclencher tous les événements
- Scheduler : communique avec l’Engine sur l’ordre des tâches à réaliser
- Downloader : Reçoit les demandes de l’Engine pour télécharger le contenu des pages web
- ItemPipeline : Successions d’étapes de transformations (pour le nettoyage, la validation de données ou l’insertion en base de données) appliquées à la donnée brute extraite
Installation de Scrapy
Scrapy est assez simple d’installation. Il suffit d’exécuter la commande ci-dessous dans un terminal Ubuntu. Vous pourrez trouver assez facilement les équivalents de ces commandes pour les autre systèmes d’exploitation :
# création d’un environnement virtuel (OPTIONNEL)
virtualenv scrapy_env
# Activation de l’environnement (OPTIONNEL)
source scrapy_env/bin/active
# installation de Scrapy
pip install scrapy
# test de vérification de l’installation
scrapy
# Effectuez un test d'évaluation rapide pour voir comment Scrappy fonctionne sur votre matériel.
scrapy bench
L’invite de commande Scrapy
En phase d’expérimentation, c’est-à-dire lorsque l’on recherche la syntaxe du code à exécuter pour extraire des informations des pages internet, Scrapy possède un invite de commandes dédié permettant d’interagir avec l’Engine de manière interactive : le Shell Scrapy.
Le Shell Scrapy est construit sur python, nous pouvons donc importer n’importe quel module dont nous avons besoin.
Pour accéder à cet invite de commande (une fois Scrapy installé), il suffit d’exécuter la commande ci-dessous :
# Ouvrir le shell scrapy
scrapy shell "URL-de-la-page-internet"
# exemple: scrapy shell "https://www.ville-ideale.fr/abries_5001"
Une fois lancé, c’est dans le Shell qu’on va pouvoir exécuter les commandes qui vont concrètement extraire les informations sur la page spécifiée. On pourra alors de manière interactive tester différentes commandes et approches d’extraction.
À l’issue des différentes expérimentations les lignes de code d’extraction seront regroupées au sein d’une classe Spider pour automatisation.
Les sélecteurs CSS et XPATH
Lors de la création d’une classe Spider, l’étape la plus importante consiste à créer le code responsable de l’extraction des données (code déterminé à l’étape précédente depuis le Shell Scrapy).
Pour indiquer quelles données du site doivent être téléchargées par Scrapy, nous pouvons utiliser :
- Les sélecteurs XPath:
Les sélecteurs XPath sont très souvent utilisés en Web Scraping en raison de leurs vastes possibilités. Par exemple :
- Indiquer l’élément exact à extraire de la page.
- Obtenir le texte associé à un élément l’élément.
- Télécharger l’élément Parent ou enfant.
- Télécharger les éléments adjacents.
- Télécharger les éléments qui commencent/finissent par des mots clés.
- Obtenir les éléments dont les attributs satisfont une condition mathématique
- Les sélecteurs CSS:
Les sélecteurs CSS constituent une alternative plus facile pour les débutants, en particulier ceux qui sont familiers avec les commandes CSS. Les sélecteurs CSS ont un peu moins de capacités que XPath, mais dans le cas de Scrapy, ils ont été étendus avec une syntaxe supplémentaire qui permet de récupérer un attribut d’élément spécifique.
- Bibliothèque BeautifulSoup:
Scrapy étant écrit en Python, il est tout à fait possible si besoin d’importer d’autres librairies pour la réalisation de certaines tâches. C’est le cas avec la librairie BeautifulSoup qui peut être utilisée (et donc importée) lors de la définition des classes d’extraction de données (les Spiders).
Exemple d’extraction de données avec Scrapy
Histoire de vous donner un aperçu concret des possibilités de Scrapy, nous allons extraire quelques données au sujet de DataScientest depuis le site https://fr.trustpilot.com/review/datascientest.com.
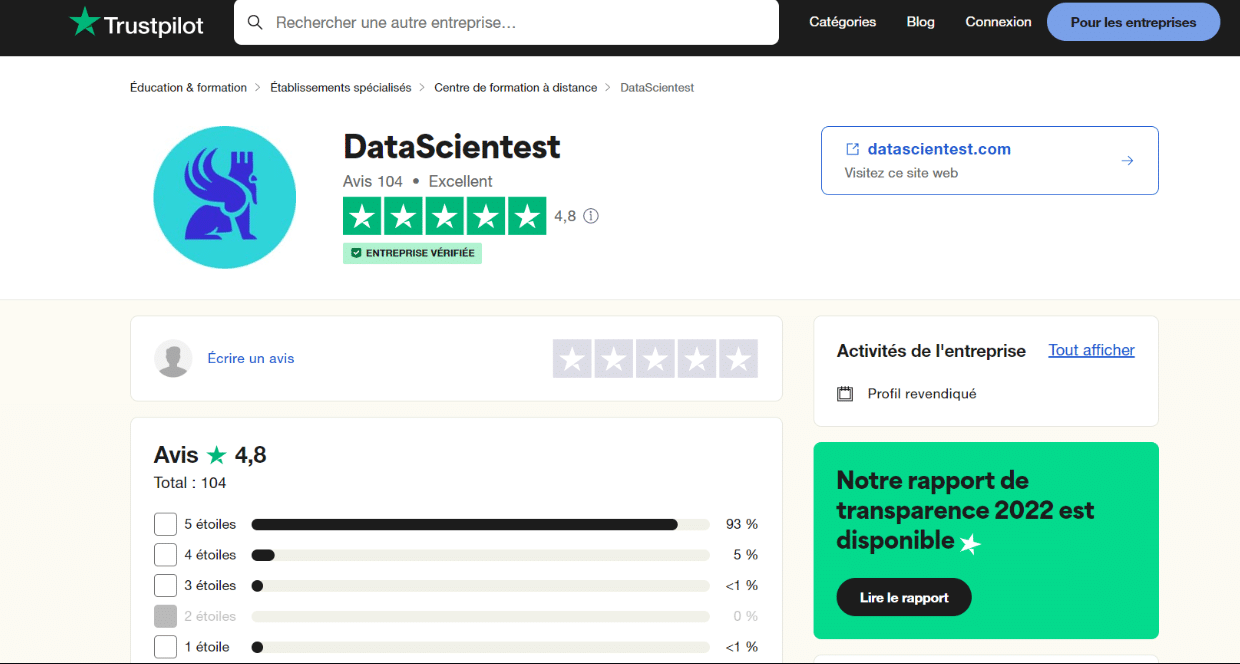
L’idée est de rassembler dans un seul fichier CSV tous les commentaires et les notes des apprenants disponibles sur trustpilot. On va se limiter aux avis donnés en Français par souci de simplicité.
La méthodologie recommandée en matière de Web Scraping avec Scrapy :
- Analyser et localiser sur la page internet les différentes informations à extraire
- Prototyper dans le Shell Scrapy les différentes commandes pour extraire chacun des éléments à extraire identifiés à l’étape précédente
- Créer un projet Scrapy et créer le Spider (pour définir comment extraire les informations de toutes les pages)
- Tester le Spider sur une page
- Appliquer le Spider à toutes les pages pour la récupération de toutes les informations.
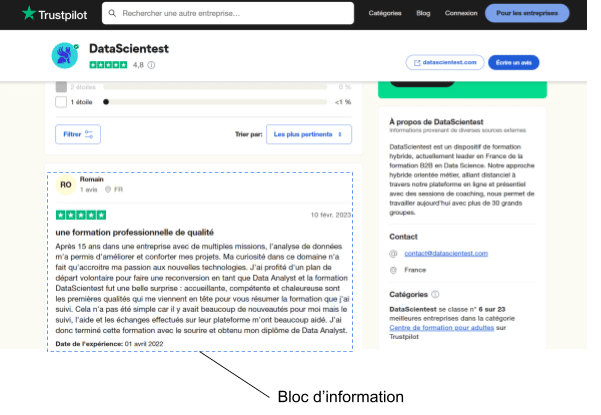
Step 1 : Analyse et localisation des informations à extraire
L’objectif de cette étape assez manuelle est simplement de repérer les informations utiles et d’identifier les balises HTML associées. Si l’on se focalise sur un avis (ci-dessous) :

On va s’intéresser aux informations ci-dessous:
- Le commentaire
- La date du commentaire
- La date de formation
- Le titre du commentaire
- La note
Pour accéder au code HTML de la page il suffit (dans le navigateur Edge ou Firefox) de faire un clic droit sur la page et de cliquer sur l’option inspecter. On pourra voir apparaître sur la droite les différentes balises associées aux différents éléments de la page.
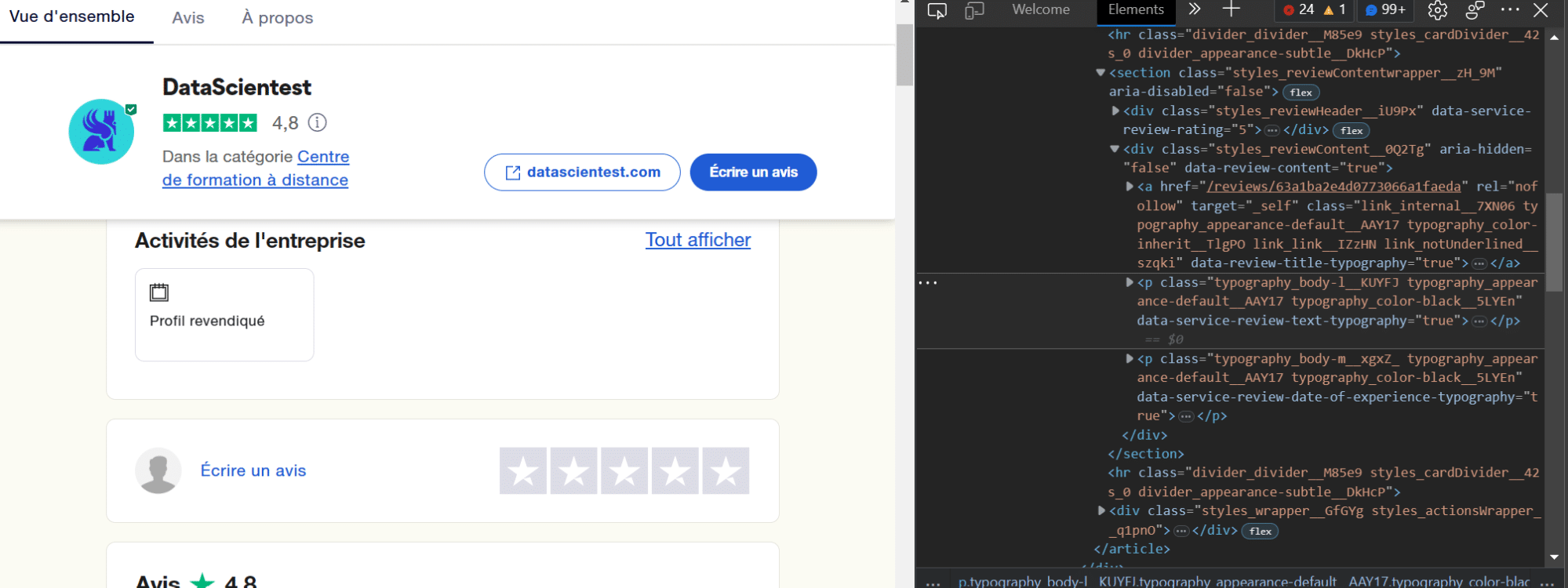
Pour accéder directement à la balise associée à un élément spécifique, il suffit de sélectionner ce dernier et de refaire la manipulation précédente (clic droit + inspecter).
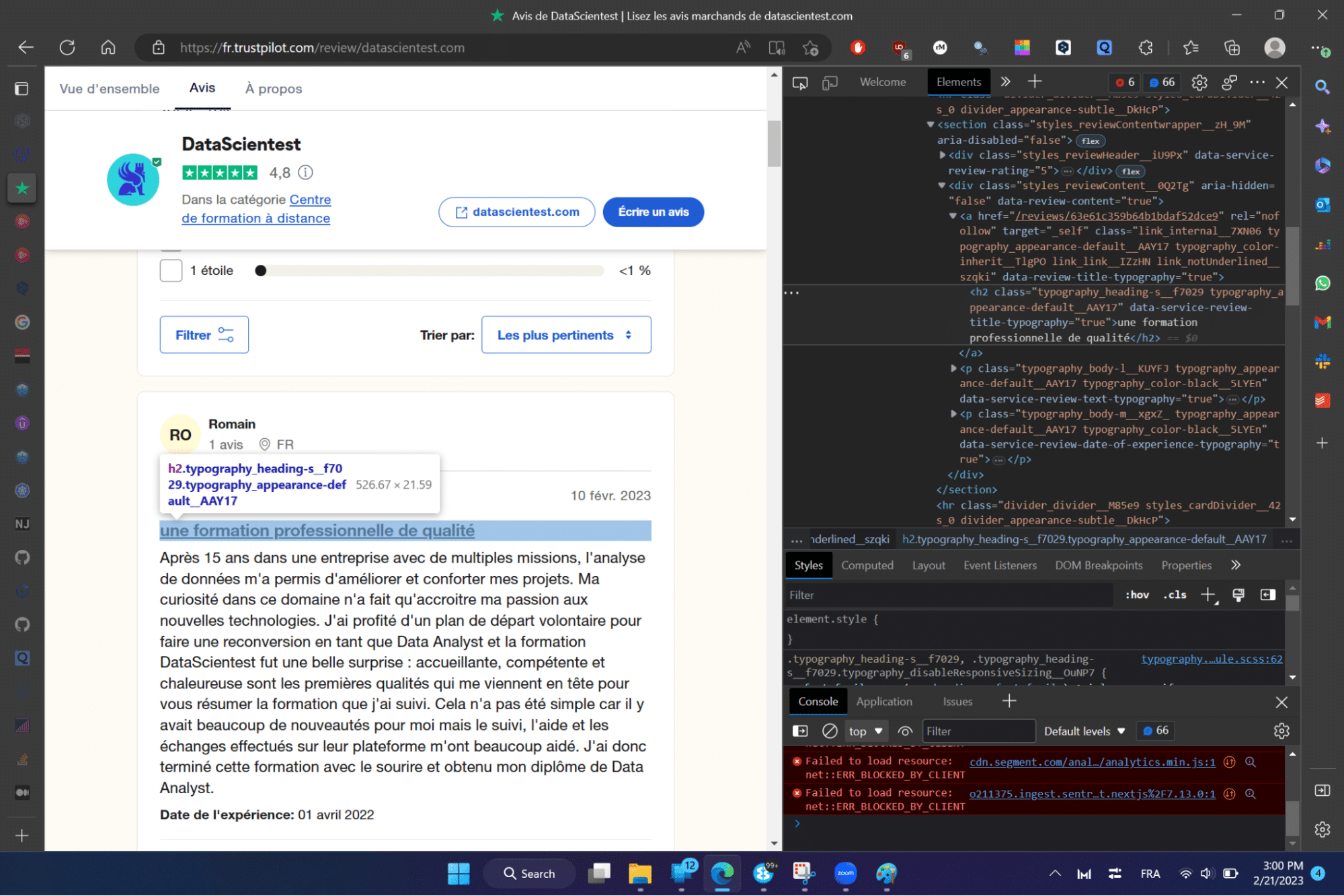
Par exemple, pour obtenir la balise associée au titre et après la manipulation, on peut lire la balise principale associée au titre du commentaire ci-contre: .typography_heading-s__f7029. Il s’agit d’une balise CSS (on parle aussi de sélecteur CSS) à partir de laquelle on peut extraire uniquement le texte.
Cette opération sera répétée pour tous les éléments que l’on souhaite extraire de manière à associer à chacun de ces derniers les balises CSS correspondantes.
Step 2 : Expérimentation avec le Scrapy Shell
Une fois les balises clairement identifiées, on peut entrer dans l’invite de commande Scrapy pour définir complètement les commandes d’extraction.
Pour entrer dans le Scrapy Shell on va entrer la commande suivante (après avoir activé l’environnement virtuel) :
# Ouverture du Scrapy shell sur le site trustpilot
scrapy shell "https://fr.trustpilot.com/review/datascientest.com"
La commande ci-dessus permet de::
- Récupérer l’ensemble des éléments de la page spécifiée à l’aide de l’API de Scrapy. Ces éléments seront stockés dans une variable « response »
- Ouvrir le Scrapy Shell
C’est sur la variable « response » que l’on va pouvoir, à l’aide des sélecteurs CSS identifiés à l’étape précédente, extraire avec précision les informations que l’on cherche.
Pour extraire les informations de manière simple et itérative (et s’assurer de récupérer simplement les informations associées à chaque commentaire), le premier élément que l’on va extraire est la liste de tous les sélecteurs de blocs d’information sur une page.
Le sélecteur CSS associé à un bloc est le suivant : .styles_reviewContentwrapper__zH_9M’
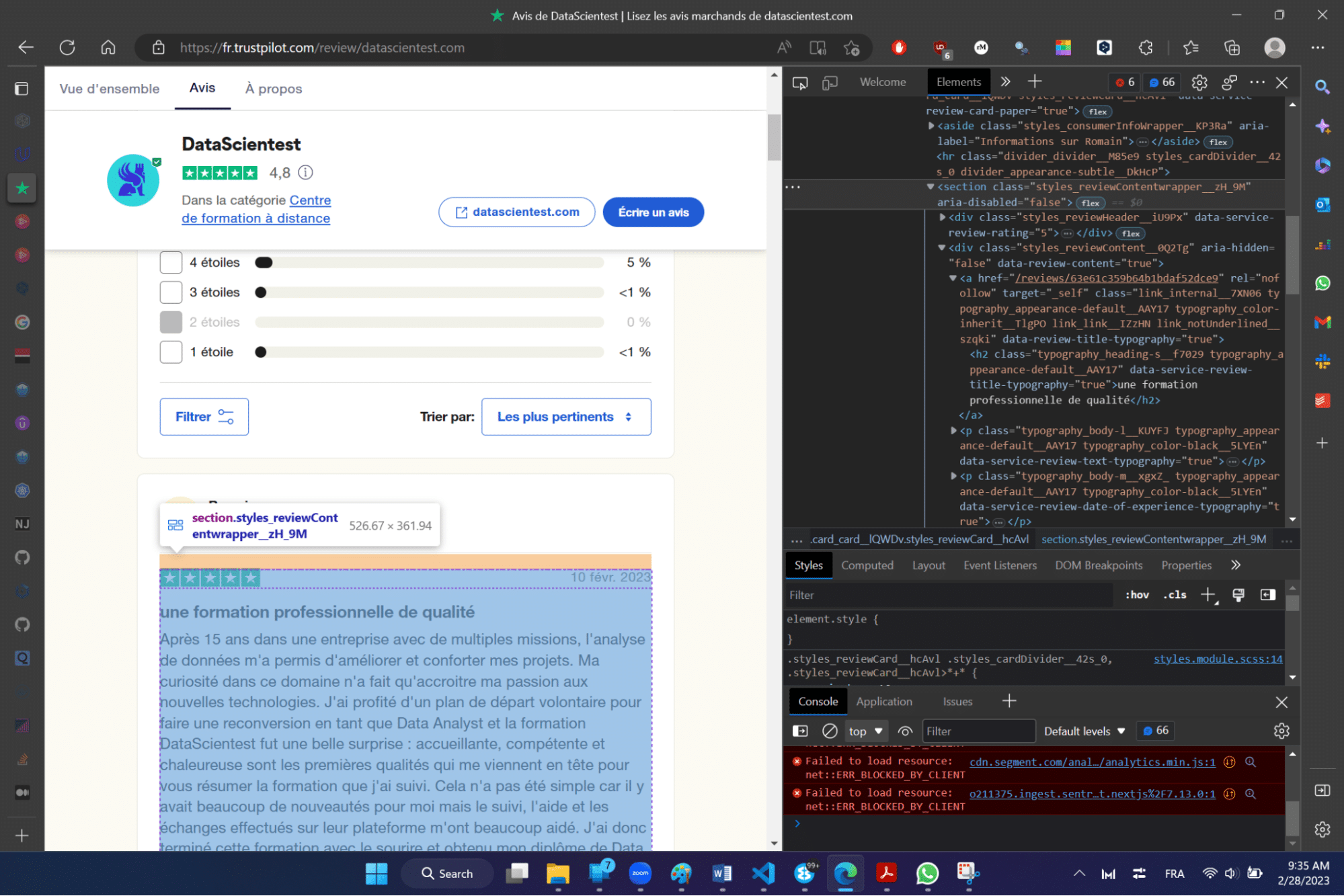
On peut alors exécuter la commande suivante dans le shell Scrapy pour extraire la liste de tous les blocs.
# Extraction de tous blocs
response.css('.styles_reviewContentwrapper__zH_9M')
On obtient en sortie le résultat ci-dessous :
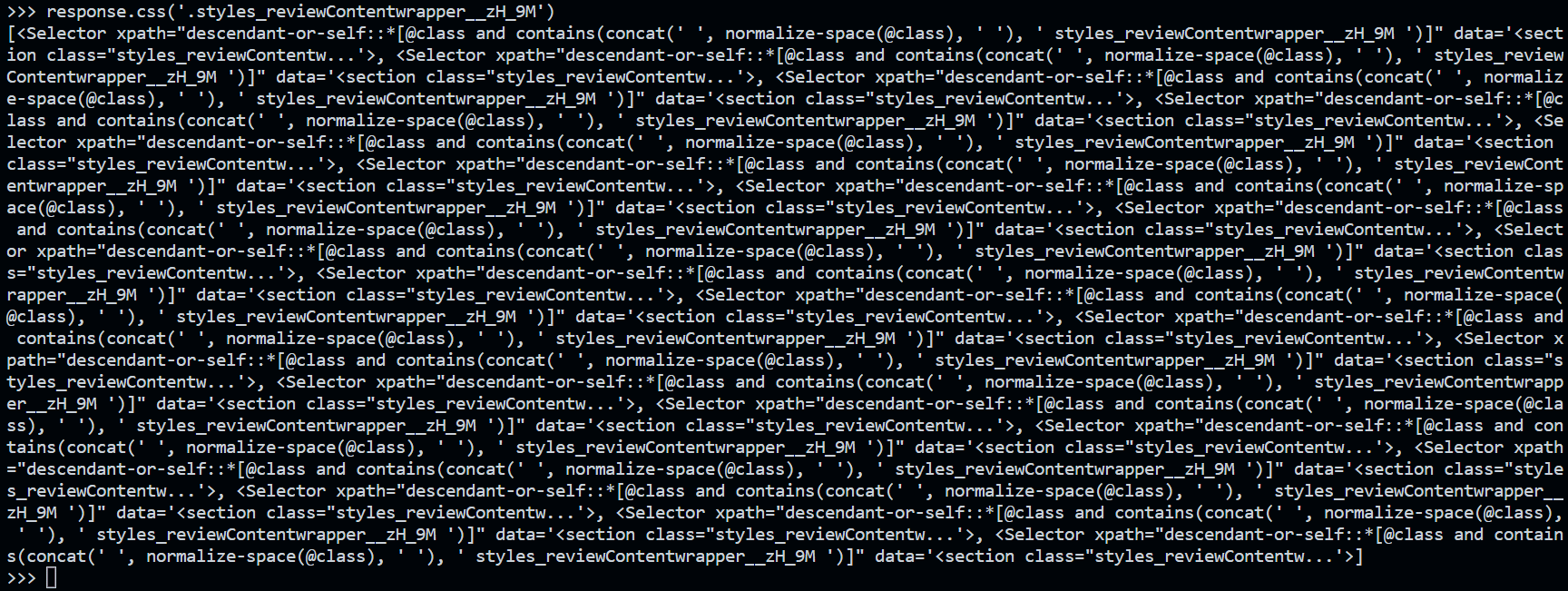
Il s’agit d’une liste de sélecteurs permettant la récupération des données contenues dans chaque bloc à l’aide de chacun des éléments de la liste. On va alors pouvoir extraire tout ce dont on a besoin avec les lignes code suivantes (chaque ligne doit être exécutée séparément dans le shell Scrapy) :
# récupération de tous les groupes d'information
selectors = response.css('.styles_reviewContentwrapper__zH_9M')
# extraction de la note sur un élément
selectors[0].css('img::attr(alt)').extract()
# extraction du titre sur un élément
selectors[0].css('.typography_heading-s__f7029::text').extract()
# commentaire et date sur un élément
elt = selectors[0].css('.typography_color-black__5LYEn::text').extract()
exp_date = elt[-1]
comment = ''.join([word for word in elt[:-1]])
# extraction de la date du commentaire (un jour de décalage avec ce qui est affiché)
selectors[0].css('div.typography_body-m__xgxZ_.typography_appearance-subtle__8_H2l.styles_datesWrapper__RCEKH > time::text').extract()
Step 3 : Création d’un projet Scrapy
Une fois le prototypage des lignes de code Scrapy terminé, on peut aisément créer une classe Spider qui ne sera que la réunion de toutes les lignes de code ci-dessus au sein d’un seul et même fichier Python.
Scrapy offre de manière native des fonctions permettant d’initialiser un projet Scrapy (et donc d’initialiser les fichiers de classes Spider). Pour créer un projet Scrapy, il suffit d’exécuter dans le Shell la commande ci-dessous :
# Création d’un projet (exemple projet trustdst)
scrapy startproject trustdst
Après exécution, vous verrez alors apparaître :

La commande que nous venons d’exécuter a permis de créer un dossier avec des fichiers Python initialisés. On peut alors voir l’architecture ci-dessous :
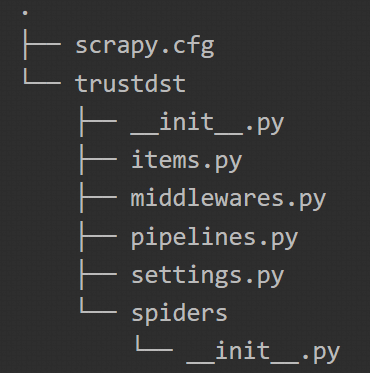
Step 4 : Création du Spider
On va s’appuyer sur l’architecture créée à l’étape précédente pour créer le fichier de class Python qui va permettre d’extraire toutes les informations d’une page en une seule fois. Encore ici, Scrapy va nous permettre d’initialiser le fichier en question avec la commande ci-dessous :
# création de la classe Spider de scraping
scrapy genspider trustpilotspider fr.trustpilot.com/review/datascientest.com
Cette commande va permettre de créer le fichier trustpilotspider.py que nous allons modifier et utiliser pour le scraping de données.
On peut alors modifier le fichier de manière suivante :
# import de scrapy
import scrapy
# définition du sipder
class TrustpilotspiderSpider(scrapy.Spider):
"""
name: a class attribute that gives a name to the spider.
We will use this when running our spider later scrapy crawl
<spider_name>.
allowed_domains: a class attribute that tells Scrapy that it
should only ever scrape pages of the chocolate.co.uk domain.
This prevents the spider going
star_urls: a class attribute that tells Scrapy the first url
it should scrape. We will be changing this in a bit.
parse: the parse function is called after a response has been
recieved from the target website.
"""
name = "trustpilotspider"
allowed_domains = ["fr.trustpilot.com"]
start_urls = ["https://fr.trustpilot.com/review/datascientest.com"] # Maj de l'URL
def parse(self, response):
"""
Module permettant d'extraire les informations
"""
# Boucle sur tous les blocs d'information
selectors = response.css('.styles_reviewContentwrapper__zH_9M')
# Extraction itérative des informations
for selector in selectors:
# Les informations à retourner
yield{
'notes' : selector.css('img::attr(alt)').extract(),
'titre' : selector.css('.typography_heading-s__f7029::text').get(), # .extract()[0]
'exp_date' : selector.css('.typography_color-black__5LYEn::text').extract()[-1],
'comments' : ''.join([text for text in selector.css('.typography_color-black__5LYEn::text').extract()[:-1]]),
'comment_date' : selector.css('div.typography_body-m__xgxZ_.typography_appearance-subtle__8_H2l.styles_datesWrapper__RCEKH > time::text').get()
}
Pour exécuter le fichier, il suffit d’exécuter la commande ci-dessous :
scrapy crawl trustpilotspider ou scrapy crawl trustpilotspider -O myonepagescrapeddata.json
(si l’on souhaite sauvegarder le résultat dans un fichier JSON)
Conclusion
Les données font partie des actifs les plus précieux qu’une entreprise puisse posséder. Elles sont au cœur de la Science des données et de l’analyse des données. Les entreprises qui collectent activement des données peuvent développer un avantage concurrentiel sur celles qui ne le font pas. Avec suffisamment de données, les organisations peuvent mieux déterminer la cause des problèmes et prendre des décisions éclairées.
Il existe des scénarios dans lesquels une organisation peut ne pas disposer de suffisamment de données pour en tirer les enseignements nécessaires. C’est le cas par exemple de certaines start-up qui commencent presque toujours sans données. Une solution dans ce cas de figure consiste à employer une technique d’acquisition de données telle que le Web Scraping.
Scrapy est un framework open-source qui permet d’extraire des données sur le web de manière efficace et qui bénéficie d’une large communauté. Il est donc totalement adapté aux projets de Web Scraping de grande envergure, car il donne une structure claire et des instruments pour traiter les informations récupérées.
Cet article n’avait pour vocation que d’introduire Scrapy avec quelques-unes de ses fonctionnalités de base utilisées par des Data Engineers, Data Scientists ou Data Analysts pour l’extraction d’information.
Si vous souhaitez aller plus loin avec Scrapy n’hésitez pas à consulter la documentation officielle : Scrapy Tutorial — Scrapy 2.8.0 documentation. Pour en apprendre davantage sur les technologies et les méthodologies d’acquisition de l’information, n’hésitez pas à consulter les formations de DataScientest.








