
L’utilisation des modèles de Deep Learning devient de plus en plus nécessaire pour les entreprises. Cependant, son implémentation représente un défi en termes de création d’un modèle qui s’adapte bien aux besoins tout en restant efficace et économique en ressources. D’où le besoin de doter l’IA d'une compréhension plus profonde et d’une autonomie accrue.
Cet article vous explique tout sur la révolution émergente permettant de libérer les développeurs des tâches fastidieuses du design et de l’optimisation manuelle. L’article met en évidence les défis, le fonctionnement et les applications potentielles dans divers domaines laissant entrevoir un avenir fascinant pour l’IA auto-apprenante.
D'où provient le LLM ?
La recherche automatique d’architecture neuronale (NAS, de l’anglais Neural Architecture Search) est née du besoin d’optimiser la création et le paramétrage des modèles de Machine Learning. La NAS essaye de répondre à la question : est-ce possible de créer un algorithme capable de créer des réseaux de neurones mieux performants que ceux créés et paramétrés à la main ? Les premiers articles portant ce sujet datent de 2016. Dans un premier temps Barret Zoph et Quoc V dans leur article Neural Architecture Search with Reinforcement Learning. Et peu après, Bozen Baken, Otkrist Gupta, Nikhil Naik et Ramesh Raskar dans leur article Designing Neural Network Architectures using Reinforcement Learning.
En effet, les réseaux de neurones sont souvent difficiles à créer lorsque les problèmes à résoudre deviennent plus complexes: la création ne prend pas seulement beaucoup de temps mais aussi de l’effort, de la maîtrise sur le sujet et beaucoup d’ajustements des paramètres. Donc, pour mieux optimiser ces ressources, les NAS automatisent la création des réseaux de neurones.
Comprendre la recherche automatique d’architecture neuronale
Dès sa conception, la recherche automatique d’architecture neuronale constitue un sous-domaine de l’AutoML ou Machine Learning automatisé; domaine chargé d’automatiser les tâches fastidieuses et itératives du développement de modèles de Machine Learning. De sa part, l’optimisation des hyperparamètres est un sous-domaine des NAS.

Une question se pose naturellement après avoir défini le rôle des NAS : où participent-elles exactement dans le processus du développement des modèles ? Et bien, la recherche automatique d’architecture neuronale a lieu dans la partie train du flux de travail : comme son nom le dit bien, l’on cherche l’architecture optimale du réseau de neurones.
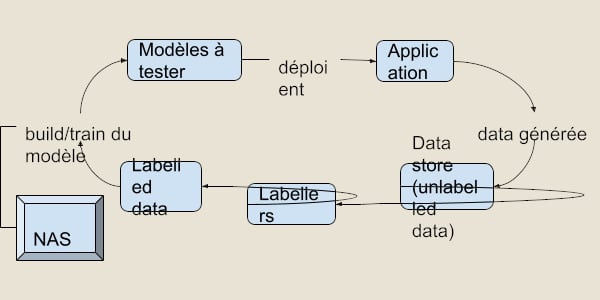
L’IA qui crée de la IA
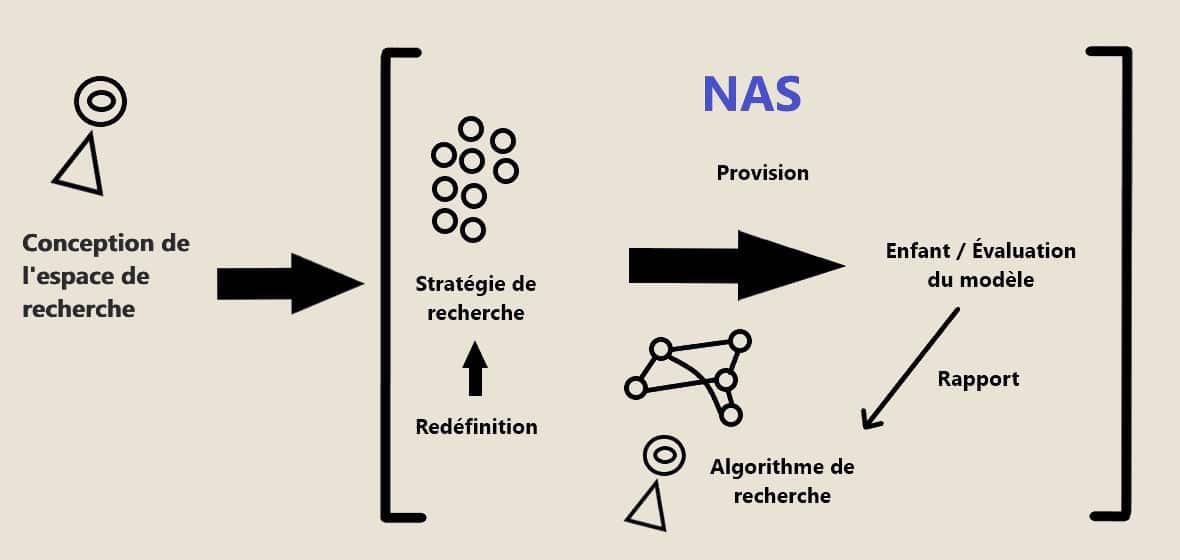
La recherche automatique d’architecture neuronale a quatre axes principaux ou blocs de construction dont elle se sert lors de la création d’un réseau de neurones :
- L’espace de recherche : il s’agit de l’ensemble des architectures candidates parmi lesquelles on peut choisir, ainsi que les opérateurs qui les composent.
- La stratégie de recherche : elle guide la façon dont la recherche s’effectue. Elle fait un échantillonnage parmi les architectures proposées sans construire ou entraîner le modèle de sorte qu’on puisse avoir une estimation de la performance théorique du modèle.
- L’algorithme de recherche : il reçoit les performances estimées et optimise les paramètres pour avoir des candidats qui sont plus performants.
- L’évaluation : les modèles sont créés par la NAS et ils sont évalués et comparés.
Pour mieux comprendre l’interaction entre ces axes, on peut observer le diagramme suivant.
Les différents types d’approches
Apprentissage par renforcement
Les toutes premières approches ont fait appel à l’apprentissage par renforcement. Dans ce type d’approche l’espace de recherche est considéré comme un environnement dans lequel on peut évoluer et où l’on attribue une récompense qui est calculée selon la méthode d’évaluation des performances de l’architecture créée. Cependant, cette méthode présente quelques désavantages : notamment les ressources nécessaires pour obtenir une architecture suffisamment performante, des milliers d’heures-GPU sont nécessaires pour ce faire.
Descente de gradient
Une autre façon d’effectuer une recherche d’architecture neuronale différentiable est d’optimiser un certain nombre de paramètres via une descente de gradient stochastique. Dans ce cas les paramètres, aussi appelés poids (des variables continues dénotés par 𝛼), représentent les opérations effectuées par l’architecture candidate. Une fois la recherche achevée, le modèle final est construit en échantillonnant les opérations constituant l’architecture prenant en compte les poids 𝛼. Les méthodes d’échantillonnage peuvent varier, comme par exemple transformer 𝛼 en une distribution de probabilités à l’aide d’une fonction softmax.
Additionnellement, les ressources de calcul et temps peuvent être davantage économisées à travers l’implémentation de mécanismes de partage des paramètres de sorte que l’espace de recherche devient partitionné en plusieurs cellules qui représentent des composantes élémentaires et à partir desquelles l’on peut construire une architecture neuronale complète. L’avantage de ce mécanisme provient du fait qu’il n’est plus nécessaire de chercher l’intégralité de l’architecture sinon quelques parties seulement. En conséquence, les méthodes différentiables prennent seulement quelques dizaines d’heures-GPU.
Algorithmes génétiques
Dans ce cas, on applique le principe darwiniste des algorithmes génétiques. Ici l’on considère les architectures candidates comme l’ensemble d’individus qui peuvent se reproduire entre eux en mélangeant leurs opérations (gènes) de sorte que cela produise de nouvelles architectures. Ainsi, une population de départ est progressivement affinée en laissant se reproduire seulement les meilleurs individus sélectionnés selon une méthode d’évaluation donnée. De façon similaire aux approches d’apprentissage par renforcement, ces méthodes sont coûteuses en heures-GPU.

Les applications
Les NAS sont un domaine en expansion, qui évolue à une grande vitesse et qui continue à dépasser des architectures développées à la main. Il s’agit aussi d’un domaine avec énormément d’applications, pour mentionner quelques unes :
- La classification des images
- La détection d’objets
- Le traitement du langage naturel
- Le traitement des séries temporelles
- La génération d’images ainsi que de vidéos ou de sons.
Avantages et limitations
Une limitation importante des NAS est le coût computationnel qu’elles peuvent représenter lorsque l’on essaye d’aborder des sujets complexes avec un nombre important de solutions latentes. Plus que l’espace de recherche est large, plus qu’il y aura des options à tester, entraîner et évaluer il y en aura.
Il est aussi important de noter qu’il est difficile de prédire la performance d’un modèle potentiel lorsqu’on l’évalue dans des données réelles.
De plus, l’espace de recherche doit toujours être défini à la main. Par contre, la maîtrise sur le sujet n’est plus un empêchement pour l’efficacité de l’architecture.
Néanmoins, ces difficultés sont en voie de disparaître avec l’arrivée des méthodes plus rapides et plus complètes d’évaluation d’architectures. Cela veut dire que bientôt la recherche automatique d’architecture neuronale sera facilement applicable dans l’ensemble des entreprises, trouvant des solutions selon leurs besoins de façon flexible et efficace.
En conclusion
La recherche automatique d’architecture neuronale nous permet de créer des nouveaux modèles à partir de zéro qui sont mieux performants que ceux créés à la main d’une façon plus rapide et optimale tout en restant flexible aux possibles modifications que l’on pourrait souhaiter de faire à la main.







