
Les Restricted Boltzmann Machines (RBM) sont un type de réseau de neurones artificiels conçu pour l’apprentissage non supervisé. Elles permettent d’apprendre une distribution de probabilité à partir d’un ensemble de données d’entrée.
Inventées par Geoffrey Hinton et Terry Sejnowski en 1985, puis popularisées dans les années 2000, les RBM sont particulièrement adaptées à la réduction de dimension, à l’extraction de caractéristiques et à la prédiction de données manquantes. Elles servent souvent de blocs de construction pour des architectures plus profondes comme les Deep Belief Networks (DBN).
Quelle est l'origine des RBM ?
Les RBM sont une version restreinte des Boltzmann Machines (BM), qui sont des réseaux neuronaux énergétiques où tous les neurones sont interconnectés. Cependant, dans une RBM, les connexions entre neurones d’une même couche sont interdites, ce qui simplifie le calcul et l’entraînement du modèle. Cette restriction permet aux RBM d’apprendre des représentations latentes utiles dans divers domaines tels que la vision par ordinateur, le traitement du langage naturel et la recommandation de contenus.
Comment fonctionnement les RBM ?
Les Restricted Boltzmann Machines (RBM) fonctionnent selon une architecture particulière composée de deux couches de neurones : une couche visible, représentant les données d’entrée, et une couche cachée, qui en extrait des caractéristiques pertinentes. Contrairement aux réseaux de neurones classiques, elles ne possèdent pas de couche de sortie, leur objectif étant de modéliser une distribution de probabilité des données. L’apprentissage repose sur l’ajustement des poids reliant ces deux couches, sans connexions internes au sein d’une même couche.
1. Architecture d’une RBM
Les RBM sont des graphes bipartites symétriques où chaque neurone de la couche visible est connecté à chaque neurone de la couche cachée, mais aucune connexion n’existe entre les neurones d’une même couche. Chaque connexion est associée à un poids qui est mis à jour pendant l’apprentissage.
2. Phase apprentissage
Durant la phase d’apprentissage, une technique appelée Contrastive Divergence (CD-k) est utilisée pour mettre à jour ces poids. Le processus commence par la présentation d’un vecteur d’entrée à la couche visible, qui transmet ensuite l’information à la couche cachée à l’aide d’une fonction d’activation sigmoïde. Un nouvel échantillon est alors généré à partir de cette couche cachée pour reconstruire une version approximative de l’entrée initiale. La différence entre cette reconstruction et l’originale permet d’évaluer une erreur qui sert ensuite à ajuster les poids du modèle. Ce processus est répété de manière itérative jusqu’à ce que les ajustements des poids deviennent négligeables.

3. Fonction d’énergie et distribution de probabilité
Les RBM sont basées sur une fonction d’énergie qui détermine la probabilité d’un état donné. La probabilité jointe des couches visibles et cachées est donnée par la distribution de Boltzmann.
L’équation de la distribution de Boltzmann décrit la probabilité Ρ(Ε) qu’une particule occupe un état d’énergie Ε à une température Τ. Elle est donnée par la formule suivante :
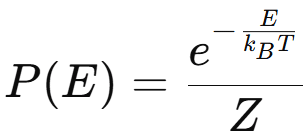
- P(E) est la probabilité d’un état ayant l’énergie E,
- E est l’énergie de l’état,
- kB est la constante de Boltzmann,
- T est la température en kelvins,
- Z est la fonction de partition
Ainsi, plus un état a une faible énergie, plus il est probable.
4. Mise à jour des poids
Les poids des connexions entre les neurones sont mis à jour en minimisant l’erreur de reconstruction. L’équation de mise à jour est donnée par :
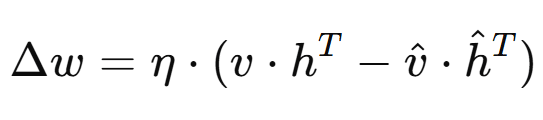
où Δω est la mise à jour des poids, η est le taux d’apprentissage, v et h sont les activations des neurones visibles et cachés, respectivement, et v̂ et ĥ sont les activations reconstruites. Cette mise à jour ajuste les poids pour réduire l’erreur entre les activations réelles et reconstruites.
Quels sont les avantages et inconvénients des RBM ?
1. Avantages
Les RBMs ont plusieurs avantages. Leurs principaux atouts sont:
- Apprentissage non supervisé : Le fait que les RBMs fonctionnent avec un apprentissage non supervisé les rend très efficaces pour extraire des caractéristiques à partir de données brutes.
- Capacité à modéliser des données complexes et de haute dimension : Elles sont capables de modéliser des distributions complexes et de haute dimension.
- Utilisées comme blocs de base pour des architectures profondes (DBN) : Elles constituent un élément fondamental dans la conception d’architectures plus profondes telles que les Deep Belief Networks.
2. Inconvénients
- Difficultés à trouver des bons hyperparamètres : Le taux d’apprentissage doit être bien ajusté. Une valeur trop élevée risque de provoquer des oscillations et d’empêcher la convergence du modèle, tandis qu’un taux trop faible ralentit considérablement l’apprentissage. En outre, le nombre de neurones cachés influence directement la capacité du modèle à apprendre des représentations pertinentes. Enfin, un nombre insuffisant peut limiter la richesse des caractéristiques extraites, tandis qu’un trop grand nombre augmente le risque de sur-ajustement.
- Le processus d’apprentissage peut être long pour de grands ensembles de données : En raison du grand nombre d’itérations nécessaires pour ajuster les poids de manière optimale. Cette contrainte devient aussi plus problématique lorsqu’on travaille avec de vastes ensembles de données, où chaque mise à jour des poids requiert de nombreuses opérations de calcul.

Comment sont utilisés les RBM ?
Les RBM ont trouvé de nombreuses applications dans divers domaines :
- Filtrage collaboratif : Utilisées dans les systèmes de recommandation pour prédire les préférences des utilisateurs.
- Vision par ordinateur : Reconnaissance d’objets, débruitage et reconstruction d’images.
- Traitement du langage naturel : Modélisation du langage, classification de textes et analyse de sentiments.
- Bioinformatique : Prédiction de structures protéiques, analyse d’expression génique.
- Finance : Prédiction de prix d’actions, analyse de risques et détection de fraudes.
- Détection d’anomalies : Identification de transactions frauduleuses, surveillance réseau et diagnostic médical.
Les applications des RBM sont variées et couvrent de nombreux domaines. Dans les systèmes de recommandation, elles permettent d’optimiser le filtrage collaboratif en prédisant les préférences des utilisateurs. En vision par ordinateur, elles sont utilisées pour la reconnaissance d’objets, le débruitage d’images et la reconstruction de données visuelles. En traitement du langage naturel, elles servent à la modélisation du langage, l’analyse de sentiments ou encore la classification de textes. Elles trouvent également leur place en bioinformatique, notamment pour l’analyse d’expression génique et la prédiction de structures protéiques, ainsi qu’en finance pour la prédiction des prix d’actions ou la détection de fraudes. Enfin, elles sont employées dans des contextes de cybersécurité et de diagnostic médical, où elles facilitent l’identification d’anomalies et la détection de comportements inhabituels.
Conclusion
Les Restricted Boltzmann Machines sont des outils puissants pour l’apprentissage non supervisé et l’extraction de caractéristiques. Leur capacité à apprendre des représentations utiles les rend indispensables pour de nombreuses applications en intelligence artificielle. Bien qu’elles présentent certains défis en termes d’entraînement et de paramétrage, elles restent un composant clé dans la conception de modèles plus avancés tels que les Deep Belief Networks et d’autres architectures neuronales profondes.








