
Avec ses nombreuses fonctionnalités permettant de traiter les données sur lesquelles nous travaillons, Pandas s’est établi comme un outil indispensable pour les Data Scientists et Data Analysts. Dans cet article vous verrez quelques fonctions, assez méconnues, qui pourront changer votre manière de travailler.
1. Ajouter une légende à un dataframe
De la même manière que pour les graphiques que l’on affiche avec Matplotlib ou Seaborn, il est possible, grâce à une ligne de code, d’ajouter une légende à un dataframe au moment de l’affichage.
Commençons par importer les librairies dont nous aurons besoin :
import pandas as pd
import numpy as np
Nous allons ensuite créer un dataframe avec des données aléatoires :
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=5),
'Taille': np.random.randint(150, 190, size=5),
'Poids': np.random.randint(50, 100, size=5),
'Salaire': np.random.randint(1000, 4000, size=5)})
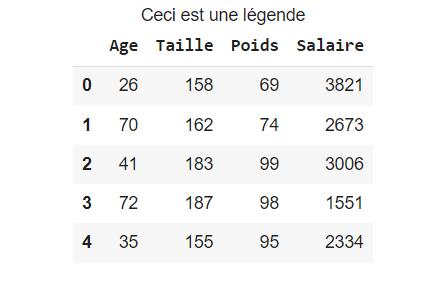
Enfin, en utilisant la fonction set_caption() on ajoute la légende au dataframe :
legende = "Ceci est une légende"
df.style.set_caption(legende)
2. Ajouter une barre de progression
Lorsque vous appliquez un traitement sur les données de votre dataframe, ce traitement peut prendre un certain temps et vous pourriez avoir envie de suivre son évolution. Pour cela il est possible d’afficher une barre de progression qui évolue avec le pourcentage du traitement complété.
Commençons par importer les librairies dont nous aurons besoin :
import pandas as pd
import time
from tqdm.notebook import tqdm
On initialise la fonction tqdm, qui nous servira à afficher la barre de progression dans le notebook :
tqdm.pandas()
Nous allons ensuite créer un dataframe avec des données aléatoires :
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=5),
'Taille': np.random.randint(150, 190, size=5),
'Poids': np.random.randint(50, 100, size=5),
'Salaire': np.random.randint(1000, 4000, size=5)})
On crée une fonction qui simule un traitement sur un dataframe qui prendrait 0.5 seconde par ligne :
def process_row(row):
tqdm.pandas(desc="Traitement en cours")
time.sleep(0.5)
On applique le traitement sur le dataframe, tout en affichant la barre de progression :
df.progress_apply(process_row, axis=1)
On affiche un message une fois le traitement terminé :
print("Traitement du DataFrame terminé.")

3. Modifier le formatage de notre dataframe
Lors de l’affichage de notre dataframe, il est possible d’ajouter des couleurs, de définir le nombre de décimales affichées ou d’ajouter les unités associées aux différentes colonnes. Pour cela nous pouvons utiliser la fonction style.format() de Pandas.
Comme précédemment on importe les librairies nécessaires et on crée le dataframe qui sera utilisé :
import pandas as pd
import numpy as np
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=10),
'Taille': np.random.randint(1500, 1900, size=10)/1000,
'Poids': np.random.randint(5000, 10000, size=10)/100,
'Salaire': np.random.randint(100000, 400000, size=10)/100})
On affiche le dataframe pour voir l’affichage par défaut :
df
On applique maintenant un formatage sur les données :
df.style.format({"Age": "{} ans",
"Taille": "{:.2f} cm",
"Poids": "{:.1f} kgs",
"Salaire":"{:,.2f}€"})\
.background_gradient()
Détaillons les différents éléments de cette commande :
"Salaire":"{:,.2f}€"
.2 indique que l’on veut garder 2 décimales.
f indique que l’on veut renvoyer un nombre à virgule flottante (float).
La virgule après les deux points indique que l’on veut séparer les milliers par des virgules.
background_gradient()
Permet de colorer les cases des différentes colonnes avec un dégradé de couleur, les valeurs les plus élevées ayant les couleurs les plus sombres.
On obtient le résultat suivant :

4. Ajouter une moyenne glissante
La moyenne glissante est utilisée dans l’analyse des séries temporelles pour lisser les variations à court terme, réduire le bruit et mettre en évidence les tendances sous-jacentes. Il est possible d’ajouter une moyenne glissante dans un dataframe grâce à la fonction rolling().
On importe les librairies nécessaires et on crée notre jeu de données aléatoirement :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
liste_dates = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D')
random_data = np.random.randn(len(liste_dates))
time_series = pd.DataFrame({'Valeur' : random_data}, index=liste_dates)
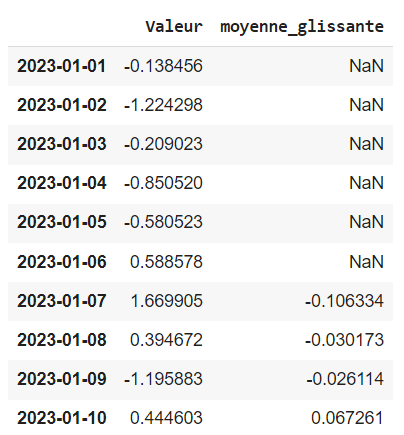
On crée ensuite la moyenne glissante avec une fenêtre de 7 jours dans une nouvelle colonne de notre dataframe :
time_series["moyenne_glissante"] = time_series["Valeur"].rolling(window=7).mean()
time_series.head(10)
On obtient le dataframe suivant. Nous pouvons voir que les six premières lignes n’ont pas de valeur pour la moyenne mobile. Cela vient du fait que la moyenne mobile pour une date est calculée à partir des dates précédentes.
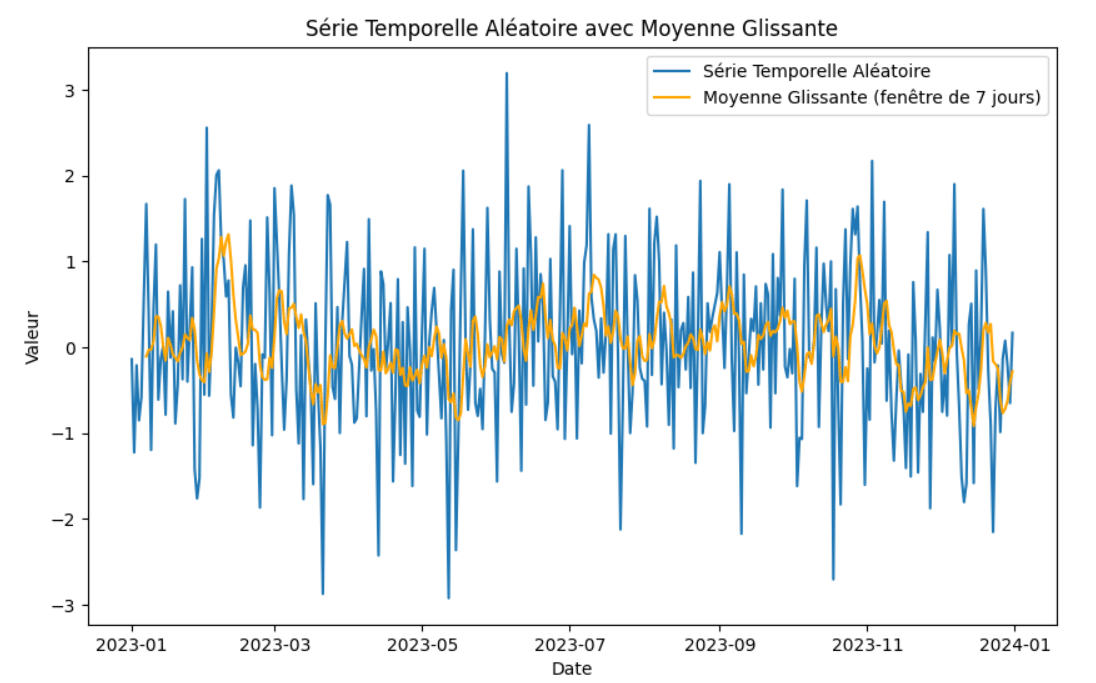
On affiche ensuite la série initiale et la courbe de la moyenne glissante :
plt.figure(figsize=(10, 6))
plt.plot(time_series["Valeur"], label='Série Temporelle Aléatoire')
plt.plot(time_series["moyenne_glissante"], label='Moyenne Glissante (fenêtre de 7 jours)', color='orange')
plt.title('Série Temporelle Aléatoire avec Moyenne Glissante')
plt.xlabel('Date')
plt.ylabel('Valeur')
plt.legend()
plt.show()
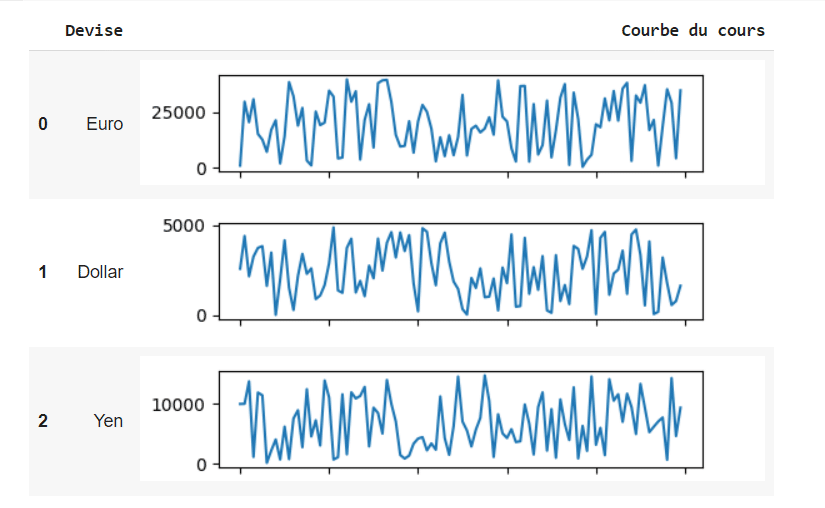
5. Afficher des courbes dans un dataframe
Il est possible d’ajouter des courbes dans un dataframe
On importe les librairies nécessaires :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from base64 import b64encode
from io import BytesIO
from IPython.display import HTML
On ajoute ensuite la ligne suivante pour permettre à Matplotlib d’afficher des graphiques dans le flux du code :
%matplotlib inline
On crée ensuite un dataframe avec des données aléatoires :
data = [('Euro', np.random.randint(40000, size=100)),
('Dollar', np.random.randint(5000, size=100)),
('Yen', np.random.randint(15000, size=100))]
df = pd.DataFrame(data, columns=['Devise', 'Cours'])
On va ensuite définir une fonction pour créer les courbes que l’on veut afficher :
# On convertit le dataframe en liste
data = list(data)
# On crée le graphique avec une taille définie
fig, ax = plt.subplots(1, 1, figsize=(5, 1))
# On affiche les données
ax.plot(data)
# On ferme le graphique pour ne pas qu’il s’affiche en dehors des endroits voulus
plt.close(fig)
# On enregistre l’image en png et on sauvegarde ses données binaires
img = BytesIO()
fig.savefig(img, format='png')
encoded = b64encode(img.getvalue()).decode('utf-8')
# On renvoie l’image encodée en HTML
return '<img decoding="async" src="data:image/png;base64,{}"/>'.format(encoded)
Enfin, on affiche le dataframe avec les courbes :
df['Courbe du cours'] = df['Cours'].apply(create_line)
HTML(df.drop(columns = ['Cours']).to_html(escape=False))
Les différentes fonctions présentées dans cet article vous permettront d’ajouter des informations dans vos dataframes et ainsi en tirer plus de données pertinentes lorsque vous devrez les présenter !
Si vous souhaitez maîtriser les dataframes de A à Z, consultez notre formation de Data Scientist !









