Les pipelines Azure DevOps permettent le CI/CD (intégration et livraison continue) sur les Azure Data Factories. Découvrez la méthode pour pousser les changements effectués sur un environnement de développement vers les environnements de test et de production !
Les Data Engineers développent et construisent des pipelines dans un environnement de Développement, puis les transfèrent vers l’environnement de Testing. Une fois les tests effectués, les pipelines peuvent être déployés en Production. Le but du processus est de détecter les bugs, les problèmes de qualité de données ou les données manquantes.
Cette séparation des environnements permet une séparation des tâches et minimise l’impact des changements effectués par les autres épiques. Elle réduit aussi les risques et les temps d’interruption, et permet de restreindre la sécurité et les permissions pour chaque environnement afin d’éviter les erreurs humaines et de protéger les données.
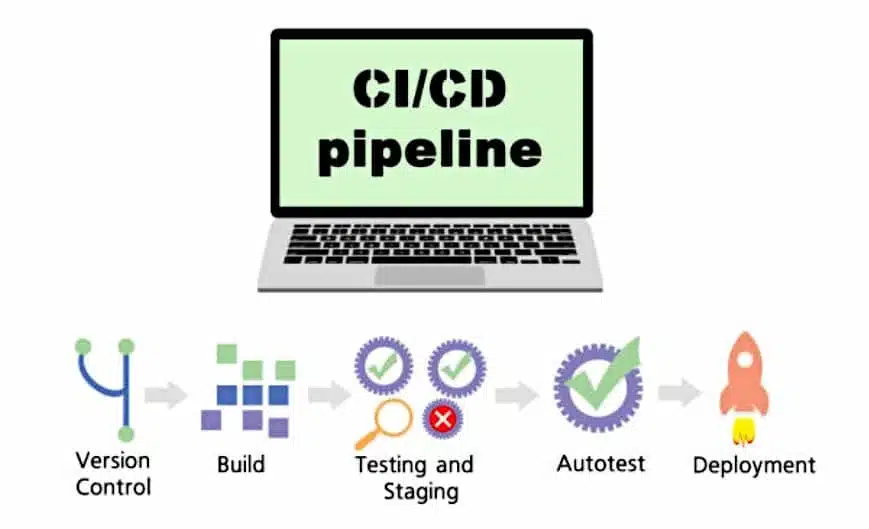
C’est la raison pour laquelle des environnements de développement, de test et de production séparés sont essentiels. Le CI/CD (intégration et livraison continue) permet d’aller plus loin en automatisant les tâches administratives et en minimisant les risques techniques.
L’automatisation et l’intégration du testing et du déploiement garantissent que les mêmes actions surviennent à chaque fois de façon constante. Les pipelines CI/CD implémentés au processus de développement permettent de tester et déployer les pipelines de données systématiquement et automatiquement.
À travers ce dossier, découvrez comment configurer un dépôt Azure DevOps pour votre Data Factory et utiliser les pipelines Azure DevOps pour pousser les changements d’un environnement vers d’autres.
Pourquoi le CI/CD pour Azure Data Factory ?
Selon la définition proposée par Microsoft, l’intégration continue est la pratique de tester change changement apporté à la base de code automatiquement et aussi tôt que possible. La livraison continue suit le testing survenant pendant l’intégration continue, et pousse les changements vers un système de staging ou de production.
Sur Azure Data Factory, l’intégration continue et la livraison continue (CI/CD) consistent à transférer les pipelines de Data Factory d’un environnement (développement, test, production) vers un autre.
Le but est donc de tester tout ce que nous développons sur Data Factory, d’utiliser de multiples environnements séparés et de simplifier les déploiements entre ces environnements au maximum pour obtenir une plateforme de Data Engineering fiable et facile à maintenir.
Quels sont les éléments prérequis ?
Plusieurs éléments sont prérequis pour ce processus. Un abonnement au cloud Azure est nécessaire, avec la capacité de créer des groupes de ressources et des ressources avec l’assignement de rôle « Propriétaire ».
Sans les privilèges liés à ce rôle, il est impossible de créer un principal de service, ouvrant l’accès aux Data Factories au sein du groupe de ressource.
La création de pipelines Azure Data Factory et DevOps est aussi indispensable. Pour cet exemple, nous allons créer toutes les ressources requises pour trois environnements : DEV, UAT et PROD.
Comment configurer l'environnement Azure ?
Pour commencer, nous allons créer trois groupes de ressources et trois Data Factories à partir du Azure Portal. Les noms de chaque groupe de ressources doivent être uniques dans l’abonnement, et les Data Factories doivent être uniques sur le cloud Azure.
Pour cet exemple, nous garderons cette structure pour le nom des ressources : « initiales-projet-environnement-ressource ». Pour plus d’informations sur les conventions de noms, vous pouvez consulter la documentation officielle de Microsoft.
En suivant cette structure, créez trois Groupes de Ressources portant les noms suivants : <Initiales>-warehouse-dev-rg <Initiales>-warehouse-uat-rg <Initiales>-warehouse-prod-rg
Une fois connecté à Azure, cliquez sur le bouton « créer une ressource » en haut de la page d’accueil. À l’aide de la barre de recherche, cherchez « Groupe Ressource » et sélectionnez « Groupe Ressource » dans les résultats.
Une fois sur la page d’information de ressource « Groupe Ressource », cliquez sur « Créer ». Sur la page « Créer un groupe ressource », vous devez compléter trois champs :
- Abonnement : choisissez votre abonnement dans la liste
- Groupe Ressource : « <Initiales>-warehouse-dev-rg »
- Région : choisissez la région la plus adaptée à votre emplacement actuel
Validez, puis cliquez sur « Créer » en bas de la page. Pour créer les Groupes Ressource UAT et PROD, réitérez le processus en remplaçant simplement le nom du groupe sur la page de création. Vous devriez maintenant voir les trois Groupes Ressource sur le portail Azure.
Nous allons maintenant créer les Data Factories pour chacun de ces trois Groupes Ressource. Les noms de ces Factories reprendront la même structure : <Initiales>-warehouse-dev-df <Initiales>-warehouse-uat-df <Initiales>-warehouse-prod-df
Gardez en tête que les noms de Data Factory doivent être uniques sur tout le cloud Azure. Vous devrez donc peut-être ajouter un numéro aléatoire à la fin des initiales choisies.
Pour créer la Data Factory DEV, cliquez sur le bouton « Créer une Ressource » en haut de la page d’accueil Azure. Dans la barre de recherche, tapez « Data Factory » et choisissez « Data Factory » dans les résultats de recherche.
Une fois sur la page d’information de ressource « Data Factory », cliquez sur « Créer ». Sur la page de création de Data Factory, vous devez compléter cinq champs.
- Abonnement : choisissez votre abonnement dans la liste
- Groupe Ressource : choisissez « <Initiales>-warehouse-dev-rg » dans le menu déroulant
- Région : choisissez la Région la plus proche de votre emplacement actuel
- Nom : « <Initiales>-warehouse-dev-df »
- Version : V2
Cliquez ensuite sur le bouton : « Suivant : configuration Git » en bas de page. Cochez « Configurer Git plus tard », validez puis cliquez sur « Créer » en bas de la page.
Pour créer les Data Factories UAT et PROD, répétez le processus en remplaçant le nom et en choisissant le Groupe Ressource correspondant à chacune.
Après avoir complété cette étape, vous verrez une Data Factory dans chaque Groupe Ressource. L’environnement de la Data Factory doit être identique à celui du Groupe Ressource.

Configurer l'environnement DevOps
La suite du processus consiste à créé un dépôt contenant le code Azure Data Factory et les pipelines. Rendez-vous sur le site web Azure DevOps et cliquez sur « s’inscrire à Azure DevOps » sous le bouton bleu « Commencer gratuitement ».
Utilisez vos identifiants Azure pour vous connecter. Sur la page de confirmation de répertoire, ne cliquez pas sur « Continuer ». La marche à suivre dépend du type de compte que vous utilisez.
Si vous utilisez un compte personnel pour Azure et DevOps, vous aurez besoin de changer de répertoire lors de la connexion. Ceci vous permettre de connecter Azure Services à DevOps. Une fois connecté, cliquez sur « changer de répertoire » à côté de l’adresse e-mail et sélectionnez « répertoire par défaut ». Cliquez ensuite sur « Continuer ».
Si vous utilisez un compte d’entreprise, il est déjà associé avec un répertoire. Vous pouvez donc cliquer directement sur « Continuer ». Sur l’écran « Créer un projet pour commencer », le nom de l’organisation est automatiquement créé en haut à gauche.
Avant de créer le projet, vérifiez que l’organisation DevOps est bien connectée au bon Azure Active Directory. En haut à gauche, cliquez sur « Paramètres d’organisation ». Sur le panneau de gauche, sélectionnez « Azure Active Directory » et assurez-vous qu’il s’agit du compte que celui utilisé pour Azure Services.
Vous pouvez maintenant commencer à créer le projet. Nommez-le « Azure Data Factory », laissez la visibilité en privé, et sélectionnez « Git » pour la « gestion de version » et « Basic » pour le « traitement d’élément de travail ». Cliquez ensuite sur « Créer le projet ».
À ce stade, vous avez créé une organisation dans DevOps et un projet contenant le dépôt de code Azure Data Factory. Vous êtes maintenant sur la page d’accueil du projet, et la prochaine étape est de lier la Data Factory DEV au dépôt DevOps.
C’est la seule Data Factory qui sera ajoutée au répertoire, car elle servira de pipeline de relaxe DevOps pour pousser le code vers UAT et PROD.
Sur le portail Azure, rendez-vous dans le Groupe Ressource DEV et cliquez sur la Data Factory DEV. Sur la page d’accueil, cliquez sur « configurer un dépôt de code ».
Sur le panneau de « configuration de dépôt », complétez les différents champs :
- Type de dépôt : Azure DevOps Git
- Azure Active Directory : choisissez votre Azure Active Directory dans la liste
- Compte Azure DevOps : choisissez le nom d’organisation créé pendant l’étape précédente »
- Nom de projet : Azure Data Factory
- Nom de dépôt : Choisissez « utiliser un dépôt existant » puis « Azure Data Factory » dans le menu déroulant
- Branche de collaboration : master
- Branche de publication : adf_publish
- Dossier racine : laissez la racine par défaut « / »
- Importer une ressource existante : ne cochez pas cette option, puisque le Data Factory est nouveau et ne contient rien.
Confirmez, et vérifiez que votre Data Factory est connectée au dépôt. À gauche de l’écran, cliquez sur « Auteur ». Au moment de choisir une branche de travail, assurez-vous de cocher « Utilisez une branche existante » et « master ». Sauvegardez.
Sous « Ressources de Factory », cliquez sur le signe « + » et choisissez « nouveau pipeline ». Nommez-le « pipeline d’attente 1 » et insérez une activité « Attendre » sur la toile de pipeline. Cliquez sur « Tout sauvegarder » en haut de l’écran puis sur « Publier » et « OK ».
Rendez-vous sur le projet Azure Data Factory dans DevOps, et sélectionner « Dépôts ». Vous y trouverez le pipeline que vous venez de créer.
Le dépôt contient actuellement deux branches. La branche master créée en même temps que le dépôt contient chaque élément de la Data Factory, dont les datasets, les runtimes d’intégration, les services liés, les pipelines et les interrupteurs. Chaque élément est associé à un fichier .json avec ses propriétés.
La branche adf_publish est créée automatiquement lors de la publication du « Pipeline d’attente 1 » contient deux fichiers extrêmement importants permettant de passer le code du Data Factory DEV vers UAT et PROD.
Le fichier ARMTemplateForFactory.json contient tous les assets au sein de la Data Factory et toutes leurs propriétés, et le fichier ARMTemplateParametersForFactory.json contient tous les paramètres utilisés par les assets au sein de la Data Factory DEV.
Maintenant que les ressources sont créées et connectées, vous pouvez créer le pipeline. Il permet de rendre disponible le contenu de la branche adf_publish pour des relaxes sur UAT et PROD.

Créer un pipeline Azure DevOps
Le rôle principal du pipeline est de saisir les contenus de la branche adf_publish. Cette branche contiendra la version la plus récente de la Data Factory DEV, pouvant être utilisée ultérieurement pour le déploiement sur les Data Factories UAT et PROD.
Le script PowerShell de « pré et post-déploiement » doit être exécuté lors de chaque relaxe. Sans ce script, la suppression d’un pipeline dans le Data Factory DEV et le déploiement de l’état actuel de DEV vers UAT et PROD ne sera pas pris en compte sur UAT et PROD.
Ce script se trouve dans la documentation Azure Data Factory en bas de la page. Copiez-le dans votre éditeur de code favori, et sauvegardez-le en tant que fichier PowerShell.
Dans Azure DevOps, cliquez sur « Dépôts » à gauche de l’écran. Dans la branche adf_publish, passez la souris sur le dossier Data Factory DEV et cliquez sur « ellipses ». Cliquez sur « Télécharger les fichiers » et téléchargez le fichier depuis son emplacement de sauvegarde. Validez. Vous devriez maintenant voir le script avec une extension « .ps1 » dans la branche adf_publish.
Nous allons maintenant créer le Pipeline Azure de CI/CD. À gauche de la page DevOps, cliquez sur « Pipelines » et sélectionnez « Créer un Pipeline ».
Sur la page suivante, choisissez « Utiliser l’éditeur classique », car il permet de suivre visuellement les étapes en cours. Lorsque tout est complété, vous pourrez inspecter le code YAML généré.
Ce pipeline doit être connecté à la branche adf_publish, puisqu’elle contient les fichiers .json ARMTemplateForFactory et ARMTemplateParametersForFactory.
Sur le panneau de sélection de sources, choisissez Azure Data Factory comme projet d’équipe et dépôt et adf_publish comme branche par défaut. Cliquez sur « Continuer ».
À présent, nous allons transférer le contenu du dossier de Data Factory DEV sous la branche adf_publish dans « Dépôts » > « Fichiers ». À droite de « Agent job 1 », cliquez sur le signe « + ». Cherchez « Publier les artefacts », et cliquez sur « Ajouter ».
En cliquant sur la tâche « Publier Artefact : lâcher » sous « Agent job 1 », vous verrez des réglages additionnels à droite de l’écran. Changez uniquement le « Chemin de Publication » en cliquant sur le bouton d’ellipse et choisissez le dossier « <Initiales>-warehouse-dev-df ». Cliquez sur « OK ».
En haut du pipeline, cliquez sur le ruban « Interrupteurs » et vérifiez d’avoir coché « Activer l’intégration continue ». Sous « Spécification de branche », choisissez « adf_publish ».
Ce réglage permet au pipeline d’exécuter et de saisir l’état le plus récent de la Data Factory DEV chaque fois qu’un utilisateur publie de nouveaux éléments. Cliquez sur « Sauvegarde et Queue », puis « Sauvegarder et exécuter ».
En cliquant sur « Agent job 1 », vous pouvez observer plus en profondeur ce qui se passe en arrière-plan. Une fois le job complété avec succès, cliquez sur « Pipelines » à gauche de l’écran. Vous pouvez voir le pipeline créé et son état, et les changements les plus récents.
Créer un pipeline de relaxe DevOps pour le CI/CD
Le pipeline de relaxe utilise le produit du pipeline créé dans l’étape précédente, afin de transférer le transférer vers les Data Factories UAT et PROD.
Sur la page DevOps, cliquez sur « Pipelines » puis « Relaxes ». Cliquez sur « Nouveau Pipeline », et renommez l’étage « UAT ». Cliquez sur « Sauvegarder » dans l’angle supérieur droit, et validez.
Après avoir créé l’étage UAT, nous allons ajouter l’artefact : le pipeline créé précédemment. Ce pipeline contiendra les configurations à transférer entre chaque étage.
Au sein du pipeline de relaxe, cliquez sur « Ajouter un artefact ». Sur le panneau « Ajouter un artefact », cliquez sur « Ajouter ».
La suite du processus est l’ajout de tâches à l’étage UAT au sein du « nouveau pipeline de relaxe ». En haut du pipeline, cliquez sur « Variables ». Nous allons ajouter des variables GroupeRessource, DataFactory et Location pour qu’elles puissent être passées automatiquement aux différentes tâches.
Cliquez sur le bouton « Ajouter » et créez les trois variables de pipeline. Assurez-vous que la variable de location contienne le même emplacement que les Groupes Ressource et les Data Factories.
Sauvegardez les changements, et rendez-vous sur la vue de pipeline. Cliquez sur « 1 job, 0 tâche » sur la boîte UAT et cliquez sur le bouton « + » à droite de « Agent job ». Cherchez « Azure PowerShell » et ajoutez-le depuis la liste. Nommez cette tâche « script Azure PowerShell : pré-déploiement ».
Au moment de choisir un Abonnement Azure, vous devez créer un Principal de Service au sein du Groupe de Ressource UAT. Ce Principal de Service sera ajouté au Groupe de Ressource PROD ultérieurement.
Choisissez votre abonnement Azure dans la liste déroulante. Pour limiter l’accès du Principal de Service, ne cliquez pas directement sur « Authorize » et sélectionnez « options avancées ».
Sur la fenêtre pop-up « Authentification de Principal de Service », vérifiez que l’option « Groupe de Ressource UAT » est sélectionnée pour le « Groupe de Ressource ». Cliquez sur « OK ».
Gardez « Chemin de fichier de script » comme « Type de Script ». Cliquez sur l’ellipse à droite du « Chemin de Script » et choisissez le script PowerShell téléchargé précédemment. Cliquez sur « OK ».
Nous utiliserons les « Arguments de Script » fournis dans la documentation Azure Data Factory. Pour le pré-déploiement, utilisez les arguments « -armTemplate « $(System.DefaultWorkingDirectory)/<your-arm-template-location> » -ResourceGroupName <your-resource-group-name> -DataFactoryName <your-data-factory-name> -predeployment $true -deleteDeployment $false ». Assurez-vous que l’emplacement du template Arm soit localisé au sein du drop d’artefact, choisissez l’environnement UAT pour le nom du Groupe Ressource et configurez le nom de la Data Factory comme le Groupe Ressource UAT. En guise de version Azure PowerShell, choisissez « Dernière version installée ». Sauvegardez.
Ajoutez une autre tâche, cliquez sur le bouton « + », cherchez « Template ARM » et ajoutez « Déploiement de template ARM » depuis la liste. Changez le nom pour « Déploiement de template ARM : Data Factory ». Choisissez le Principal de Service créé précédemment dans « connexion Gestionnaire de Ressource Azure ».
Complétez les autres champs :
- Abonnement : choisissez votre abonnement
- Action : créer ou mettre à jour un Groupe Ressource
- Groupe Ressource : Utilisez la variable de Groupe Ressource créée auparavant
- Emplacement : Utilisez la variable de Location
- Emplacement de template : Artefact Lié
- Paramètres de Template : Choisissez le fichier ARMTemplateForFactory.json
- Paramètres de remplacement de template : remplacez le paramètre « factory name » par la variable de Data Factory
- Mode de déploiement : Incrémental

Ajoutez ensuite une tâche Azure PowerShell nommée « script Azure PowerShell : Post-Déploiement ». Par rapport aux arguments de pré-déploiement, remplacez uniquement « -predeployment $true » par « -predeployment $false » et «-deleteDeployment $false » par « -deleteDeployment $true ».
Il faut maintenant donner au Principal de Service l’accès au Groupe de Ressource PROD, avant de commencer à créer l’étage PROD du pipeline de relaxe. Rendez-vous sur le portail Azure, naviguez vers le Groupe de Ressource UAT et sélectionnez « Contrôle d’Accès (IAM) ». Sous le rôle « Contributeur », copiez le nom de l’organisation DevOps et le nom du projet.
Rendez-vous sur le Groupe de Ressource PROD et naviguez sur « Contrôle d’Accès (IAM) ». Dans l’ongle de visualisation des accès, cliquez sur le bouton « + Ajouter » et sélectionnez « Ajouter un assignement de rôle ». Choisissez le rôle de Contributeur dans le menu déroulant, et laissez « Assigner l’accès à » comme « Utilisateur, groupe ou principal de service ». Collez le nom précédemment copié dans la barre de recherche, et sélectionnez le principal de service. Sauvegardez.
Nous pouvons maintenant compléter l’étage PROD du pipeline de relaxe. Revenez sur le « Nouveau pipeline de relaxe » et passez la souris sur l’étage UAT. Cliquez sur « Cloner ».
Renommez « Copie de UAT » en « PROD ». Les variables ResourceGroup et DataFactory sont dupliquées, mais sous le scope Prod. Modifiez leurs valeurs en remplaçant « UAT » par « PROD ». Sauvegardez.
Alors que le pipeline Azure Data Factory-CI est configuré pour s’exécuter à chaque changement dans adf_publish, il faut maintenant ajuster le Pipeline de relaxe pour qu’une nouvelle relaxe survienne à chaque changement dans adf_publish. Le changement doit ensuite s’appliquer automatiquement à la Data Factory UAT. Pour la Data Factory PROD, une approbation pré-déploiement est requise avant que les changements DEV et UAT soient appliqués.
Dans le « nouveau pipeline de relaxe », cliquez sur le bouton « interrupteur de déploiement continu » pour l’activer. Pour ajuster les conditions du l’étage UAT pour s’exécuter automatiquement, cliquez sur le bouton de « conditions de pré-déploiement » sur l’étage UAT. Veillez à sélectionner l’option « après relaxe ».
Cliquez sur les conditions « pré-déploiement » pour l’étage PROD et configurez l’interrupteur sur « après étage » avec l’étage configuré sur UAT. Activez aussi les « approbations pré-déploiements » et entrez votre email. Sauvegardez.
Pour tester le pipeline de relaxe, initiez manuellement le pipeline Azure Data Factory-CI afin de l’activer. Rendez-vous dans Pipelines, et sélectionnez Azure Data Factory-CI. Cliquez sur « exécuter le pipeline » en haut, et cliquez à nouveau sur « exécuter ». Rendez-vous dans « Relaxes », et vous devriez maintenant voir la première relaxe. Vous constatez aussi que l’étage UAT du Pipeline de Relaxe est en cours d’exécution.
Une fois l’étage UAT complété avec succès, l’étage PROD est près pour l’approbation. Rendez-vous sur votre Data Factory UAT et vérifiez si le « Pipeline d’attente 1 » est présent.
Rendez-vous sur votre « Nouveau pipeline de relaxe » et cliquez sur l’étage PROD. Approuvez. Vous pouvez voir la progression de l’étage PROD, et la présence du « Pipeline d’attente 1 ».
Pour terminer, vous pouvez effectuer des changements dans la Data Factory DEV afin d’observer l’intégralité du processus du début à la fin. Rendez-vous sur la Data Factory DEV, créez un pipeline appelé « Pipeline d’attente 2 » et insérez une activité « Attente 2 ». Supprimez le « Pipeline d’attente 1 ».
Cliquez sur « tout sauvegarder » et « publiez » tous les changements. Dans « Pipelines » sur Azure DevOps, vous pouvez voir que le pipeline Azure Data Factory-CI a déjà été activé puisque le adf_publish vient de changer. De même, dans « Relaxes », « Relaxe-2 » a été créé et l’étage UAT est en cours de déploiement.
La Data Factory PROD est actuellement sur « Relaxe-1 ». Approuvez l’étage PROD. On constate que les changements effectués sur la Data Factory DEV sont aussi appliqués aux Data Factories UAT et PROD !
Ceci confirme que toutes les ressources sont connectées correctement, et que les pipelines fonctionnent correctement. Tout futur déploiement dans la Data Factory DEV peut être répliqué sur UAT et PROD.
Ainsi, vous éviterez les petites différences entre les environnements et éviterez les pertes de temps liées à la résolution de problèmes. N’hésitez pas à visualiser le code YAML généré au fil des étapes de cette prise en main, afin de comprendre sa structure et son contenu…
Comment apprendre à maîtriser Azure DevOps ?
Azure DevOps est très utilisé par les équipes DevOps. Afin d’apprendre à maîtriser ce service cloud et ses différents éléments comme les Data Factories, vous pouvez choisir DataScientest.
Nos formations à distance permettent d’apprendre à maîtriser tous les meilleurs outils cloud et DevOps, mais aussi les meilleures pratiques et méthodes de travail. À la fin du cursus, vous aurez toutes les compétences d’un ingénieur DevOps.
De même, notre formation Data Engineer couvre tous les aspects de l’ingénierie des données. Vous découvrirez notamment la programmation en Python, le CI/CD, les bases de données, le Big Data ou encore les techniques d’automatisation et de déploiement.
Tous nos programmes se complètent en Formation Continue ou en mode BootCamp, et permettent un apprentissage par la pratique grâce à un projet fil rouge. Vous pourrez aussi obtenir les meilleures certifications cloud et DevOps.
Notre organisme leader francophone des formations Data Science est reconnu par l’État, et éligible au Compte Personnel de Formation pour le financement. N’attendez plus et découvrez DataScientest !
Vous savez tout sur Azure DevOps Pipelines et Data Factory. Pour plus d’informations sur le même sujet, consultez notre dossier complet sur le DevOps et notre dossier sur le cloud Microsoft Azure.








