
Einleitung
Du hast wahrscheinlich schon von Machine Learning gehört, wenn es um die Vorhersage des Preises eines Hauses oder um Sportwetten geht. Die Einsatzmöglichkeiten sind vielfältig und du fragst dich wahrscheinlich, wie du sie für solche Projekte nutzen kannst.
In den vorherigen Artikeln haben wir über die Einrichtung einer geeigneten Umgebung und die Erforschung der notwendigen Daten gesprochen, bevor wir uns an die Modellierung eines ML-Projekts machen. Falls du sie noch nicht gelesen hast, empfehlen wir dir, dies zu tun, bevor du mit der Modellierung beginnst.
Heute geht es darum, wie du die Schritte zur Modellierung des Projektproblems organisieren kannst.
Auswahl der Modelle
Wenn du die Schritte des vorherigen Artikels befolgt hast, sollten dein Datensatz und deine Produktionsumgebung für die Modellierung bereit sein.
Beginnen wir damit, das Problem zu modellieren, d. h. die Problemstellung in eine bestimmte Aufgabe umzuwandeln.
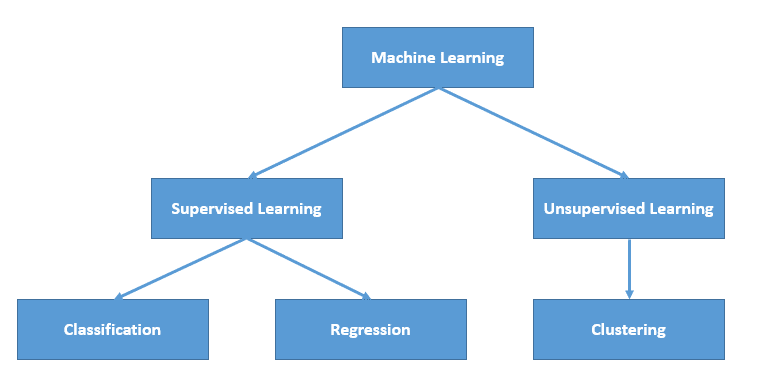
Arten des Lernens
Wir unterscheiden zwei Hauptfamilien im Bereich des ML: überwachtes und unüberwachtes Lernen.
Anmerkung: Es gibt auch andere Arten des Lernens, wie z. B. das halbüberwachte Lernen oder das Lernen durch Verstärkung, die wir in diesem Artikel nicht näher erläutern werden.
Die Frage, die du dir stellen musst, um herauszufinden, zu welcher Familie dein Problem gehört, ist folgende: Besitzt du die Zielvariable für mein Projekt?
Deine Zielvariable ist die Spalte, die du vorhersagen willst. Wenn du die Werte dieser Spalte besitzt, bist du in einem überwachten Lernprozess.
Wenn du nicht über die Werte verfügst, sondern versuchst, eine Schätzung der Spalte zu erhalten, ohne die genauen Werte zu kennen, handelt es sich um unüberwachtes Lernen.
1) Nicht überwachtes Lernen
Beim unbeaufsichtigten Lernen musst du die folgenden Techniken anwenden:
- Clustering (Kmeans, MeanShift, Spectral Clustering…).
- Algorithmen zur Dimensionsreduktion (PCA, TSNE).
- Die Erkennung von Anomalien (EllipticEnvelope, IsolationForest).
Brauchst du eine kleine Auffrischung zu diesen Themen? Sie werden alle in unserem Blog behandelt.
Kommen wir nun zum überwachten Lernen.
2) Überwachtes Lernen.
Wenn dein Datensatz hingegen die Zielvariable enthält, dann musst du dich fragen, ob die Spalte, die du vorhersagen willst, eine kontinuierliche oder eine kategoriale Variable ist.
Eine kontinuierliche Variable ist z. B. der Preis eines Hauses oder die Zeit, die eine Person auf einer Website verbringt, bevor sie zum Kauf übergeht.
Eine kategoriale Variable hingegen hat eine begrenzte Anzahl von Modalitäten, wie z. B. eine Altersgruppe oder die verschiedenen Arten von Treueabonnements einer bestimmten Telefongesellschaft.
Es gibt viele verschiedene Regressionsalgorithmen. Zu nennen sind hier die lineare Regression, Random Forests oder SVM Regressor.
Es gibt auch viele Klassifikationsalgorithmen wie Entscheidungsbäume oder das SVM-Modell.
Wenn du das Gefühl hast, dass eine Auffrischung dieser Algorithmen hilfreich wäre, haben wir ihnen einen Artikel in unserem Blog gewidmet, den du dir gerne ansehen kannst.
In beiden Fällen gibt es keine Zauberformel, sondern du musst zunächst die verschiedenen Modelle testen, um dasjenige zu bestimmen, das dir die beste Leistung bringt.
Wenn du jedoch eine Klassifikation durchführst und deine Klassen unausgewogen sind, ist es ratsam, deinen Datensatz mithilfe von Resampling-Techniken wieder ins Gleichgewicht zu bringen.
Deep-Models und neuronale Netze können sowohl bei der Regression als auch bei der Klassifizierung eingesetzt werden. Sie bieten oftmals eine höhere Leistung, haben aber auch zwei Nachteile, die es zu beachten gilt.
Neuronale Netze sind sehr anfällig für Overlearning (d. h. sie sind schwer zu verallgemeinern) und sind nicht gut interpretierbar. Mit interpretierbar ist gemeint, dass es komplex ist, ihre Entscheidungen zu verstehen und zu antizipieren.
Auswahl und Optimierung der Vorlage
Du hast jetzt die Leistung jedes Modells, das für dein Problem in Frage kommt. Du musst nun das Modell mit der besten Leistung auswählen, aber wie?
Die Kreuzvalidierung ist eine sehr nützliche Technik, mit der du herausfinden kannst, ob dein Modell verallgemeinerbar ist, d. h., ob es sich gut verhält, wenn es auf neue Daten trifft.
Sie ermöglicht es dir auch, die optimalen Parameter deines Modells parallel zur Optimierungsmethode zu finden. Es gibt verschiedene Methoden zur Optimierung von Hyperparametern, wie z. B. die `GridSearchCV`-Funktion, die Zufallssuche oder die Bayes’sche Optimierung…
Metrisch
Die Leistung von Akkordmodellen erhalten, aber nach welcher Metrik?
Für Regressionsprobleme kannst du die Metriken MAE, MSE oder R2 in Betracht ziehen.
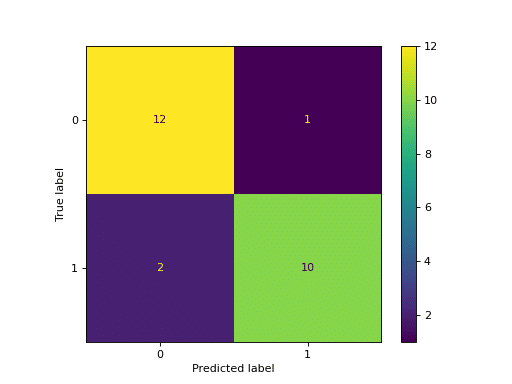
Bei Klassifikationsproblemen kannst du die Werkzeuge der Konfusionsmatrix oder des Klassifikationsberichts verwenden.
Die Konfusionsmatrix ist eine praktische Darstellung der Genauigkeit eines Modells mit zwei oder mehr Klassen, während der Klassifikationsbericht mehr Informationen über andere Metriken (z. B. Recall, f1-Score usw.) liefert.
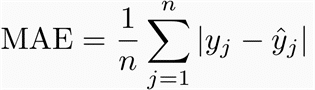
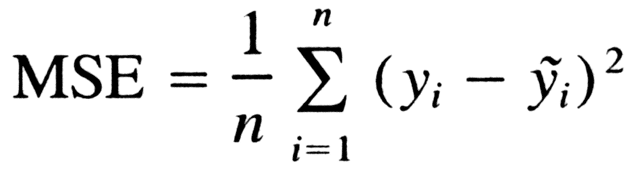
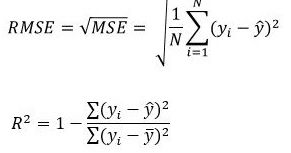
Abschluss
Zu diesem Zeitpunkt hast du die Leistung deiner verschiedenen Modelle in deinem Datensatz mit den hyperoptimalen Parametern und der/den Bewertungsmetrik(en). Du kannst nun die Leistung der Modelle vergleichen und dich auf das beste Modell einigen.
Um dies zu tun, solltest du nicht nur die Leistung des Modells berücksichtigen, sondern auch die Interpretierbarkeit hinterfragen. In einigen Bereichen, wie z. B. in der Medizin oder beim autonomen Fahren, kann es entscheidend sein, zu verstehen, wie dein Modell seine Entscheidungen trifft. Diese beiden Aspekte müssen berücksichtigt werden, um den besten Kompromiss zu finden und das am besten geeignete Modell zu finden.
Fazit
Jetzt weißt du, wie du die verschiedenen Schritte der Modellierung deines Projekts durchführen kannst.
Wenn dir dieser oder die anderen Artikel gefallen haben, dann abonniere unseren YouTube-Kanal, um über Themen der Data Science informiert zu werden, die dich interessieren könnten.







