Kolmogorov Smirnov Test: Was ist das für eine Methode?
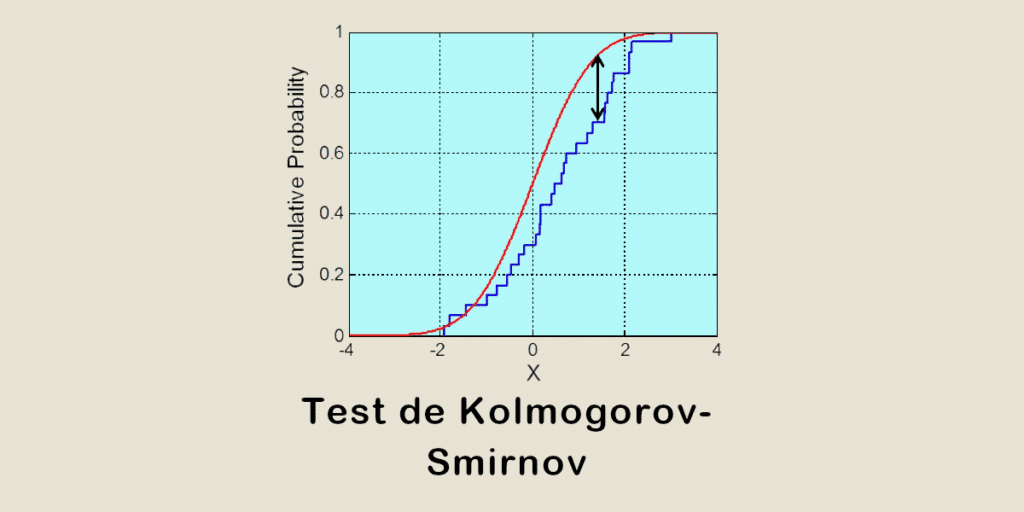
Der Kolmogorov Smirnov Test ist eine häufig verwendete Methode zum Vergleich von Daten. Erfahre die erstaunliche Geschichte seiner Erfindung und wie er heutzutage in der Data Science eingesetzt wird! 1933 veröffentlichte Andrei Kolmogorov einen Artikel mit dem Titel „Sulla determinazione empirica di una legge di distribuzione“ (Über die empirische Bestimmung eines Verteilungsgesetzes). Darin stellte der […]
HTML5: Was ist das? Vollständiger Leitfaden

Die Webentwicklung entwickelt sich ständig weiter. HTML5 hat sich als grundlegende und unverzichtbare Sprache etabliert. Seit seiner offiziellen Einführung am 28. Oktober 2014 hat HTML5 die Art und Weise, wie Websites erstellt werden, revolutioniert und bietet eine Vielzahl von erweiterten Funktionen, die das Nutzererlebnis verbessern. Die Entwicklung der grundlegenden Tags in HTML5 HTML5 hat die […]
Vereinfachte Bereitstellung mit GCP Cloud Deploy

Continuous Integration and Delivery (CI/CD) wird immer wichtiger, da es dem Ziel der Agilität bei der Anwendungsentwicklung entspricht. Das CI/CD-Prinzip hat sich jedoch im Laufe der Zeit als effektiv erwiesen, was zum Teil auf die Tools zurückzuführen ist, die die kontinuierliche Bereitstellung ermöglichen. Eines dieser Werkzeuge ist GCP Cloud Deploy. Hier erfährst du, wie es […]
Der Cloud Adoption Framework GCP CAF

Der Umstieg auf die Cloud ermöglicht es Unternehmen, flexibler und effizienter zu werden, bringt aber auch viele Herausforderungen mit sich. Das gilt sowohl für den verwendeten Technologiestack als auch für die Mitarbeiter, die daran beteiligt sind, und für alle Prozesse in der Organisation. Aus diesem Grund bietet die Google Cloud Platform ihr Adoption Framework an. […]
Entdecke den Rechenservice GCP Cloud Functions

Um eine neue Software oder Anwendung zu entwerfen, müssen die Entwickler oft die gesamte zugrunde liegende Infrastruktur (mit Servern, Speicherdienst und anderen Cloud-Ressourcen) bereitstellen. Das ist mit GCP Cloud Functions nicht mehr der Fall. Dieser Dienst der Google Cloud Platform vereinfacht die Arbeit von DevOps mithilfe von Mikrodiensten. Erfahre, wie Cloud Functions funktioniert und welche […]
Die Services der Google Cloud Platform (GCP)
Cloud Computing wird immer beliebter, da es die Skalierung und den Zugriff auf IT-Ressourcen über große Entfernungen hinweg erleichtert. Zu den wichtigsten Anbietern gehören Amazon Web Service (AWS), Microsoft Azure und Google Cloud Platform (GCP). In diesem Artikel werden wir uns mit der GCP beschäftigen. Was ist die Google Cloud Platform? GCP ist ein umfassender […]
Lookalike: Warum sind diese Zielgruppen im Marketing wichtig?

Personen mit ähnlichen Merkmalen werden mit größerer Wahrscheinlichkeit das gleiche Verhalten an den Tag legen. Ausgehend von diesem Prinzip definieren Organisationen ähnliche Zielgruppen, um ihre potenziellen Kunden besser anzusprechen. Dies wird als Lookalike Audiences bezeichnet. Focus. Was bedeutet Lookalike? „Lookalike“ kann ins Deutsche mit dem Ausdruck Doppelgänger übersetzt werden. Es handelt sich aber vor allem […]
Jensen Shannon Divergence: Alles über dieses ML-Modell
Die Jensen Shannon Divergence wird verwendet, um die Ähnlichkeit zwischen zwei Wahrscheinlichkeitsverteilungen zu messen, insbesondere im Bereich des maschinellen Lernens. Hier erfährst du alles, was du über dieses Maß wissen musst, von seiner Geschichte bis hin zu seinen modernen Anwendungen! Jahrhundert haben der dänische Mathematiker Johan Jensen und der amerikanische Statistiker Peter Shannon wichtige Beiträge […]
Traffic Manager: Alles über den Beruf

Ob sie ihre Produkte und Dienstleistungen verkaufen oder einfach nur auf sich aufmerksam machen wollen, die große Mehrheit der Unternehmen hat heute eine Website. Aber damit sie effektiv ist, muss sie qualitativ hochwertigen Traffic aufweisen. Da es immer mehr Webseiten gibt, ist es oft schwierig, qualitativen Traffic zu bekommen. Es sei denn, man verfügt über […]
SEA (Search Engine Advertising): Wie funktioniert es?

Im Zeitalter der Digitalisierung haben Unternehmen ein großes Interesse daran, in Suchmaschinen (und sozialen Netzwerken) aufzutreten. Aber bei Bing, Yahoo und Google ist die Konkurrenz besonders groß. Um sich eine erstklassige Position zu sichern, ist es besser, eine SEA-Strategie einzuführen. Worum geht es also? Wie funktioniert es? Was sind die Vor- und Nachteile? Finde die […]
Data Room: Was ist das? Wer nutzt es?

IData Room: Im Zeitalter von Big Data, in dem Daten zu einer der wertvollsten Ressourcen von Unternehmen werden, erscheint die Datensicherheit als eine äußerst wichtige Herausforderung. Dies beginnt bereits bei der Speicherung. Genau aus diesem Grund werden Datenräume immer häufiger eingerichtet. Worum geht es also? Für wen ist diese Lösung geeignet? Was sind die Vorteile? […]
Outbound Marketing: Prinzipien, Vorteile und Hebel zur Akquise

Niemand mag es, einen Telefonanruf von einem Werbeagenten zu erhalten. Aber jeder kauft gerne ein Produkt oder eine Dienstleistung, die seinem Bedürfnis oder Wunsch entspricht. Hier liegt die Feinheit zwischen dem Scheitern und dem Erfolg einer Outbound-Strategie. Für die meisten Unternehmen ist es notwendig, neue Kunden zu gewinnen, aber die richtige Umsetzung kann die Ergebnisse […]
