Regex (regelmäßiger Ausdruck): Was ist das? Wie benutzt man es?

In der Welt der Computer müssen wir oft Aufgaben erledigen, die mit Textverarbeitung zu tun haben. Es gibt ein universelles Werkzeug namens Regex, das oft die leistungsfähigsten Lösungen in diesem Bereich anbietet. Reguläre Ausdrücke sind jedoch weitgehend unbekannt, da sie manchmal etwas verwirrend aussehen. Was ist Regex? Ein regulärer Ausdruck, auch umgangssprachlich Regex genannt, ist […]
Apache Flink : Definition, Struktur und Grenzen des Frameworks

Die Ursprünge von Apache Flink Apache Flink wurde ursprünglich an der Technischen Universität Berlin entwickelt. Die ersten Versionen wurden 2011 veröffentlicht und sollten komplexe Probleme bei der Verarbeitung von Daten in einer verteilten Echtzeitumgebung lösen. Flink wurde im Laufe der Jahre zu einer Referenz für eine Vielzahl von Unternehmen, bis es schließlich zu einem der […]
Was ist die Grad CAM-Methode?

In den letzten Jahren war die Erklärbarkeit ein wiederkehrendes, aber immer noch ein Nischenthema im maschinellen Lernen. Die Grad-CAM-Methode ist eine Lösung, um dieses Problem anzugehen. In jüngerer Zeit hat das Interesse an diesem Thema begonnen, sich zu beschleunigen. Ein Grund dafür: die wachsende Zahl von Modellen des maschinellen Lernens in der Produktion. Das führt […]
Einführung in die Wahrscheinlichkeitsrechnung – Teil 1

Was ist eine Wahrscheinlichkeit? Eine Wahrscheinlichkeit quantifiziert die Chance bzw. das Risiko, dass ein Ereignis eintritt. Dieser Wert liegt immer zwischen 0 und 1. Einige Anwendungsfälle der Wahrscheinlichkeit im Alltag Das Werfen eines Würfels Wenn man einen sechsseitigen ungesteppten Würfel wirft, hat man eine Chance von 1 zu 6, eine 3 zu würfeln. Wir definieren […]
Google schafft die erste Regulierung für künstliche Intelligenz

Basierend auf den effektivsten Sicherheitsmaßnahmen und seiner KI-Expertise erstellt Google die SAIF-Regelung. Diese Regelung legt Richtlinien im industriellen Maßstab fest, um sicherere KIs zu schaffen und einzusetzen. Sicherere KIs? Um die Entwicklung hochwertiger und sicherer Künstlicher Intelligenz zu ermöglichen, hat Google beschlossen, die SAIF-Richtlinie einzuführen. Diese Regelung wird bereits bei der Entwicklung von KI angewendet, […]
CPC (Cost per Click) : Was ist das? Wozu dient er?

Egal, ob es sich um Werbung in Suchmaschinen oder sozialen Netzwerken handelt, der CPC (oder Cost per Click) ist eine der wichtigsten Kennzahlen. Worum geht es also genau? Wozu dient er? Wie kann man ihn optimieren? Hier findest du die Antworten. Was ist Cost per Click? Der CPC ist der Preis pro Klick. Mit anderen […]
Data Pipeline: Was du noch nicht wusstest
Eine Data Pipeline ist eine Reihe von Prozessen und Werkzeugen, die verwendet werden, um Rohdaten aus verschiedenen Quellen zu sammeln, sie zu analysieren und die Ergebnisse in einem verständlichen Format darzustellen. Unternehmen nutzen Datenpipelines, um spezifische geschäftliche Fragen zu beantworten und strategische Entscheidungen auf der Grundlage von realen Daten zu treffen. Alle verfügbaren Datensätze (interne […]
Excel Makros aktivieren: Diese Schritte solltest du nicht überspringen

Excel Makros: Jeder, der Excel häufig benutzt, hat schon einmal sich wiederholende Aufgaben erledigen müssen. Sei es das Berechnen von Summen, das Formatieren von Daten oder das Auswählen von Zellen – diese Aufgaben von Hand zu erledigen, kann schnell zeitraubend werden. Das beste Mittel, um diese Prozesse zu beschleunigen, sind heutzutage Makros. Um Excel Makros […]
Excel Filter: Wie wendet man in Excel einen Filter an?

Deine Excel-Tabelle ist zu unübersichtlich. Fühlst du dich in einem Meer von Daten ertrunken? Keine Sorge, dieser Artikel soll dir helfen, die relevanten Daten mithilfe des Excel Filters zu finden. Was ist die Funktion eines Excel Filters? Der Excel-Filter, auch bekannt als Autofilter, ist ein praktischer Ansatz, um nur die Daten anzuzeigen, die zu einem […]
Open Data – eine Goldgrube für jedermann

Open Data bezeichnet alle Daten, die von öffentlichen Verwaltungen und Unternehmen veröffentlicht und gesammelt werden. Diese Daten sind in der Regel kostenlos oder zu sehr geringen Kosten erhältlich und leicht zugänglich. Die Verpflichtung zur Information und Transparenz gegenüber den Nutzern, die durch die DSGVO gewährleistet wird, macht Open Data zu einem demokratischen Pfeiler, aber auch […]
Linux Betriebssystem: Warum ist es das beliebteste OS für Entwickler?

Wenn man über das Linux Betriebssystem spricht, bedeutet das in der Regel, dass man die Entwicklung des Betriebssystems erlernen muss, und das kann Angst machen. Aber ist das wirklich gerechtfertigt? Das wollen wir in diesem Artikel herausfinden. Einführung – Was ist das Linux Betriebssystem? Linux ist ein Unix-ähnliches Betriebssystem, das auf dem Linux-Kernel basiert. Unix-Systeme […]
OLAP-Würfel, Snowflake, Star: Einführung in multidimensionale Architekturen
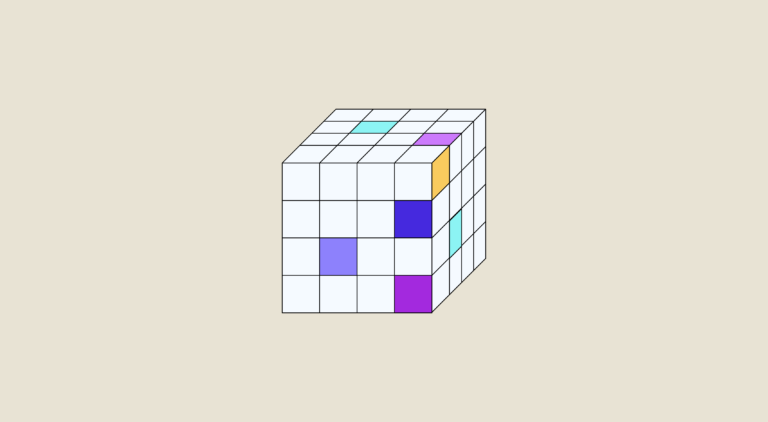
OLAP-Würfel: Multidimensionale Analyse ist die Fähigkeit, Daten zu analysieren, die in mehreren Dimensionen zusammengefasst wurden. In diesem Artikel lernst du das Stern- und das Schneeflockenmuster kennen, die beliebtesten Modelle für multidimensionale Daten. Am Ende des Artikels findest du eine Tabelle, in der die beiden Modelle miteinander verglichen werden. Was ist ein OLAP-Würfel? OLAP-Würfel, für Online […]
