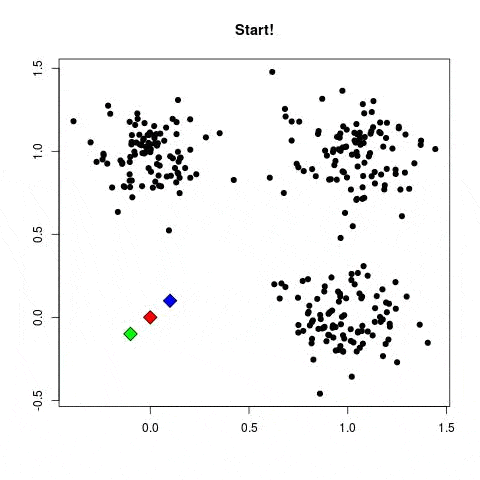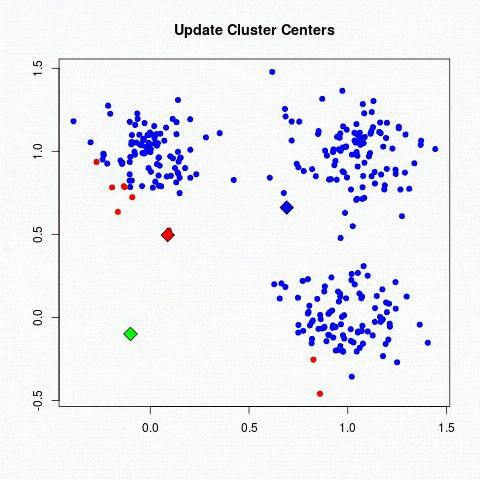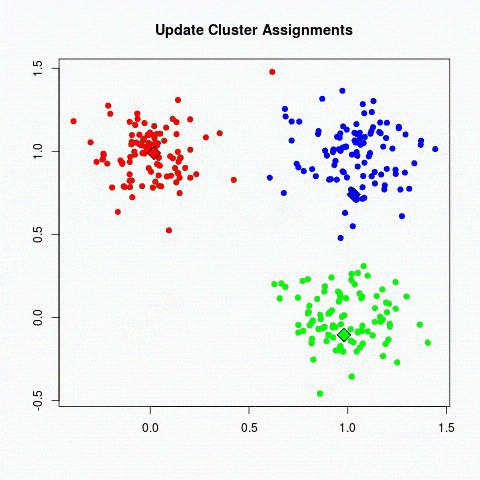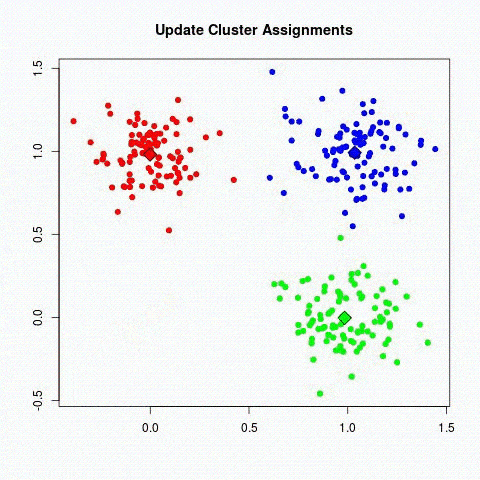
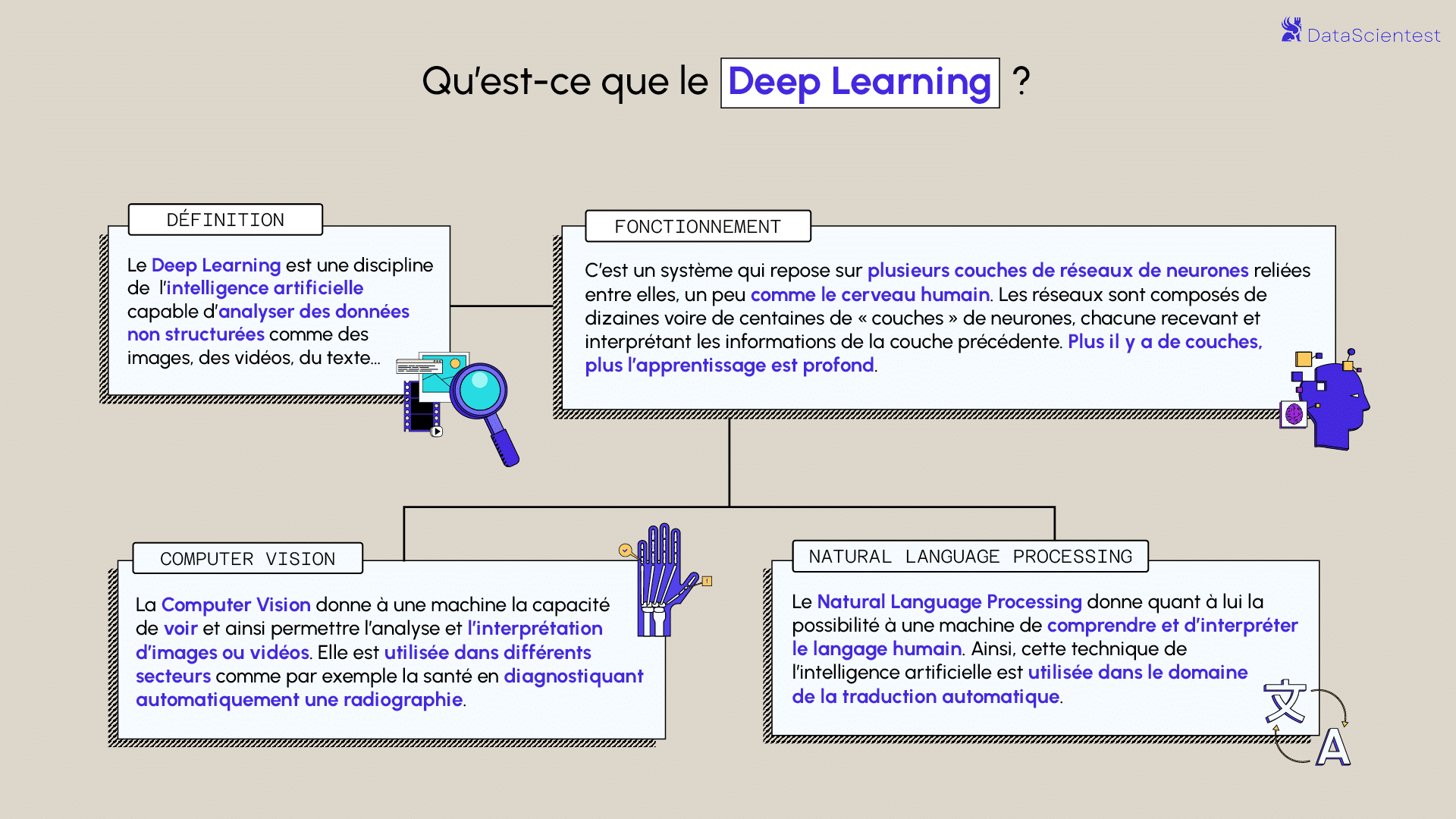
Le Deep learning ou apprentissage profond est l’une des technologies principales du Machine learning. Avec le Deep Learning, nous parlons d’algorithmes capables de mimer les actions du cerveau humain grâce à des réseaux de neurones artificielles. Les réseaux sont composés de dizaines voire de centaines de « couches » de neurones, chacune recevant et interprétant les informations de la couche précédente.
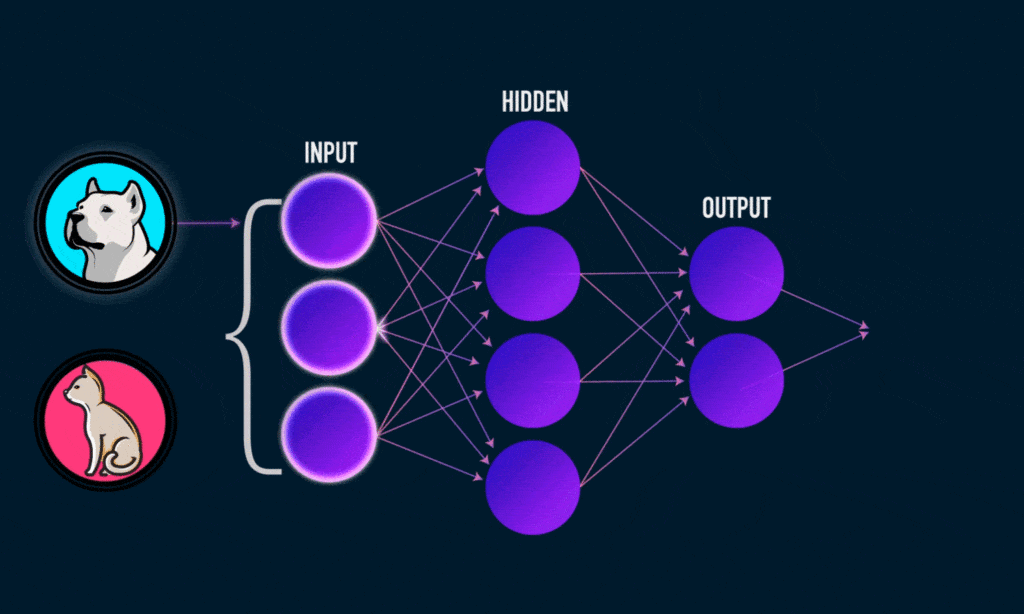
source : Medium.com
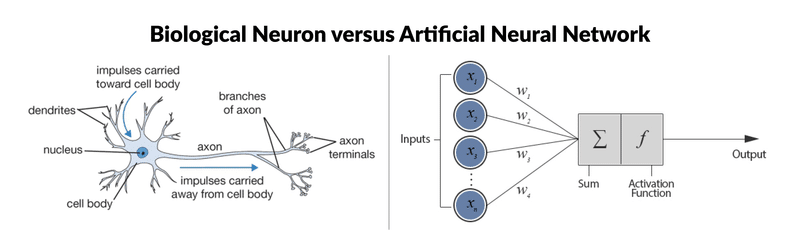
Chaque neurone artificiel représenté dans l’image précédente par un rond, peut être vu comme un modèle linéaire. En interconnectant les neurones sous forme de couche, nous transformons notre réseau de neurones en un modèle non-linéaire très complexe.
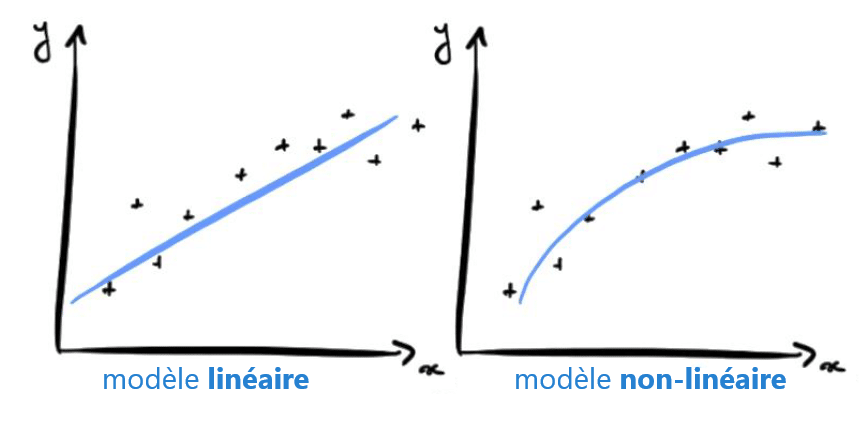
Pour illustrer le concept, prenons un problème de classification entre chien et chat à partir d’image. Lors de l’apprentissage, l’algorithme va ajuster les poids des neurones de façon à diminuer l’écart entre les résultats obtenus et les résultats attendus. Le modèle pourra apprendre à détecter les triangles dans une image puisque les chats ont des oreilles beaucoup plus triangulaires que les chiens.
Les modèles de Deep learning ont tendance à bien fonctionner avec une grande quantité de données alors que les modèles d’apprentissage automatique plus classique cessent de s’améliorer après un point de saturation.
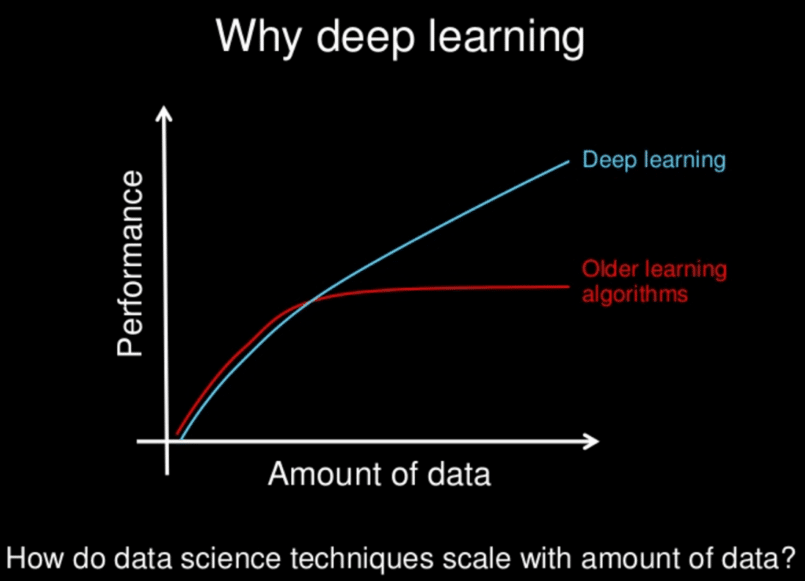
Au fil des années, avec l’émergence du big data et de composants informatiques de plus en plus puissant, les algorithmes de Deep Learning gourmands en puissance et en données ont dépassé la plupart des autres méthodes. Ils semblent être prêt à résoudre bien des problèmes : reconnaître des visages, vaincre des joueurs de go ou de poker, permettre la conduite de voitures autonomes ou encore la recherche de cellules cancéreuses.
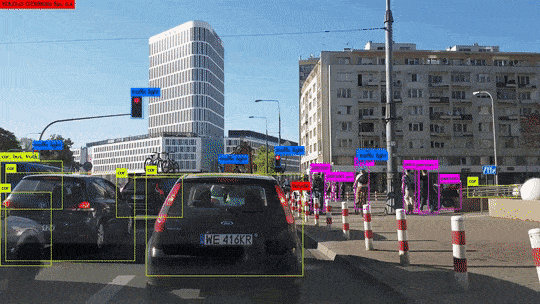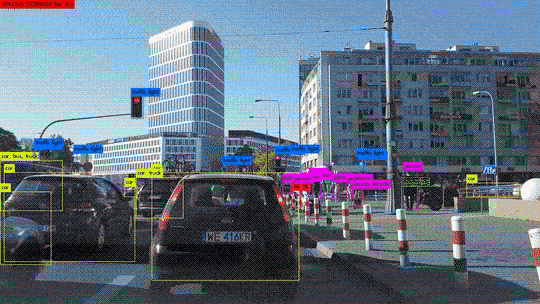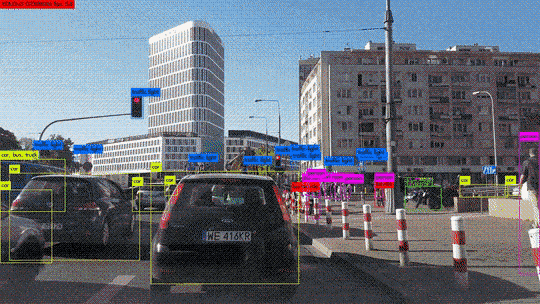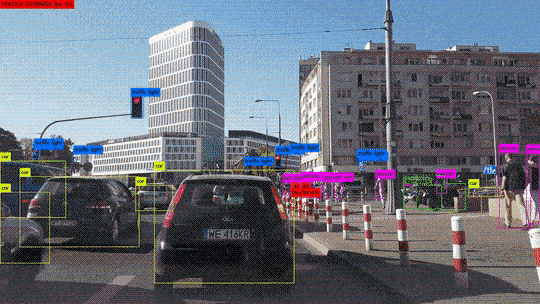


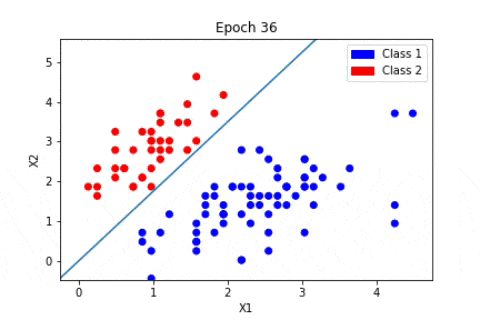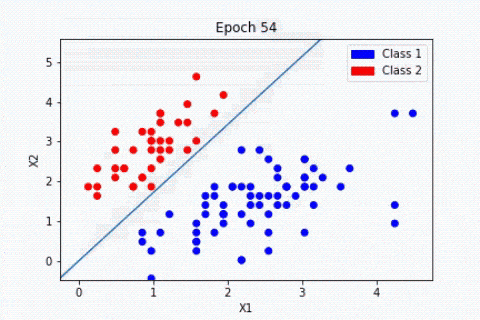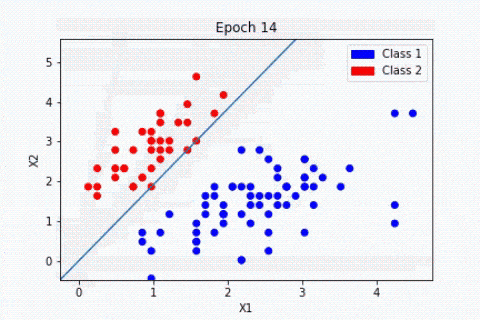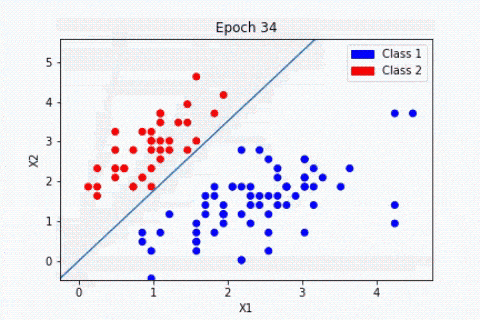
Procédons à une comparaison simple des étapes principales de l’algorithme du perceptron avec les éléments constitutifs des neurones biologiques. Ce choix d’algorithme se justifie car il se rapproche au mieux du fonctionnement des neurones biologiques :
- Les synapses/dendrites : pondération de chaque élément en entrée wixi
- Corps cellulaires : application d’une fonction d’activation f à la somme des entrées pondérées
- Axone : sortie de notre modèle
 x
x