L’entreprise chinoise DeepSeek dévoile son dernier bijou technologique : DeepSeek-V3, un modèle de langage ouvert ultra-performant avec 671 milliards de paramètres et des performances capables de rivaliser avec GPT-4 ou Claude 3.5. En plus de proposer des coûts d’entraînement réduits, DeepSeek-V3 se positionne comme une alternative crédible aux solutions fermées.
Quelles sont les caractéristiques de DeepSeek-V3 ?
DeepSeek-V3 se distingue par son architecture innovante, conçue pour allier puissance de calcul et efficacité économique. Contrairement aux modèles traditionnels, il utilise une approche appelée mixture-of-experts (MoE). Cette technique n’active qu’une fraction de ses 671 milliards de paramètres (37 milliards par token), ce qui réduit la consommation de ressources tout en maintenant des performances élevées.
Deux innovations majeures renforcent l’efficacité du modèle :
- La prédiction multi-tokens (MTP), permettant de générer plusieurs tokens simultanément, accélère le processus de génération (jusqu’à 60 tokens par seconde).
- Le load balancing sans perte, qui optimise dynamiquement l’utilisation des experts sans compromettre la qualité des résultats.
Grâce à des optimisations algorithmiques et matérielles, comme l’utilisation du framework FP8 et de l’algorithme DualPipe, le modèle a été entraîné en seulement 2788K heures GPU, pour un coût total estimé à 5,57 millions de dollars. Une prouesse notable lorsqu’on sait que des modèles comme Llama-3.1 nécessitent des investissements dépassant les 500 millions de dollars.
Une concurrence internationale
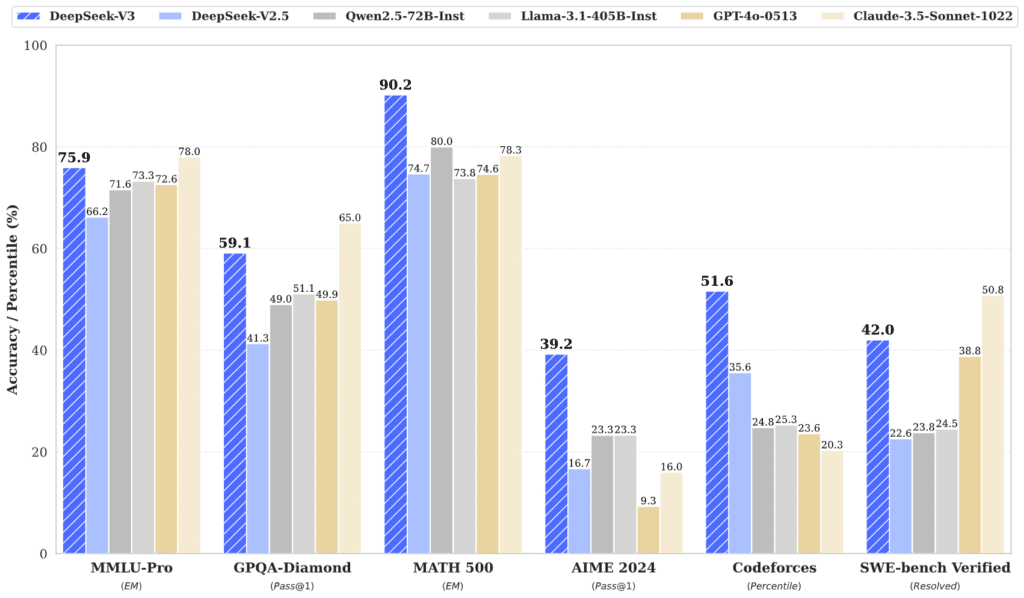
En matière de performance, DeepSeek-V3 n’a rien à envier à ses homologues fermés. Lors de tests comparatifs, il a surpassé plusieurs modèles open source de référence, notamment Llama-3.1-405B et Qwen 2.5-72B. Mieux encore, il s’est mesuré avec succès à des modèles fermés tels que GPT-4o et Claude 3.5 Sonnet, rivalisant sur des tâches multilingues et mathématiques.
Les résultats sont particulièrement frappants sur les benchmarks chinois et spécialisés, où DeepSeek-V3 excelle. Par exemple, il a obtenu un score impressionnant de 90,2 au test Math-500, contre 80 pour Qwen. Cependant, il reste légèrement en retrait face à GPT-4o sur des tâches comme SimpleQA ou FRAMES, illustrant qu’il reste encore des marges d’amélioration sur certains domaines spécifiques.
Ce modèle témoigne de la montée en puissance des entreprises chinoises dans la course à l’intelligence artificielle. En défiant les leaders américains malgré des restrictions technologiques croissantes, DeepSeek ouvre la voie à une concurrence plus équilibrée, à la fois sur le plan technologique et économique.
Une aubaine pour le domaine de l'open source ?
DeepSeek-V3 marque une étape clé pour la communauté open source. En publiant son modèle sous licence permissive MIT et en rendant son code accessible sur des plateformes comme GitHub et Hugging Face, DeepSeek offre à la communauté mondiale des outils de pointe. Cette transparence permet aux développeurs, entreprises et chercheurs de tester, adapter et améliorer le modèle selon leurs besoins spécifiques.
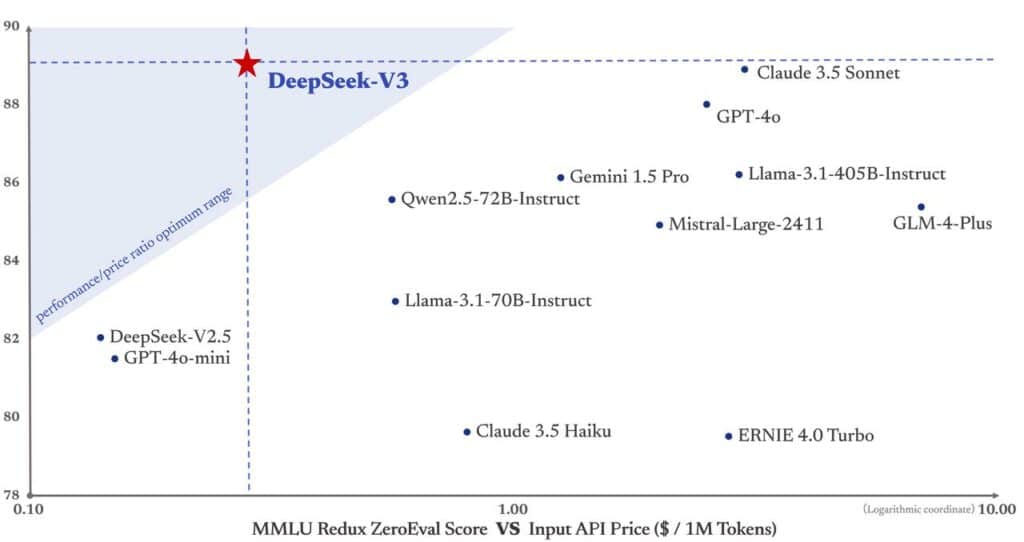
En outre, son lancement met en lumière un autre avantage majeur : une démocratisation des technologies avancées. Contrairement aux solutions fermées, souvent coûteuses et limitant l’accès, DeepSeek-V3 permet à un plus large éventail d’acteurs de tirer parti des capacités des grands modèles de langage. Les tarifs compétitifs proposés pour son API (0,27$/million de tokens en entrée et 1,10$/million en sortie) renforcent son attractivité pour les petites et moyennes entreprises.
En offrant un modèle ouvert capable de rivaliser avec les leaders fermés, DeepSeek ne se contente pas de bousculer les géants américains. Il redéfinit également les normes de l’innovation dans le secteur, en prouvant que l’open source peut rivaliser, voire dépasser, les solutions propriétaires.
Si cet article vous a plu et si vous envisagez une carrière dans la Data Science ou tout simplement une montée en compétences dans votre domaine, n’hésitez pas à découvrir nos offres de formations ou nos articles de blog sur DataScientest.
Source : api-docs.deepseek









