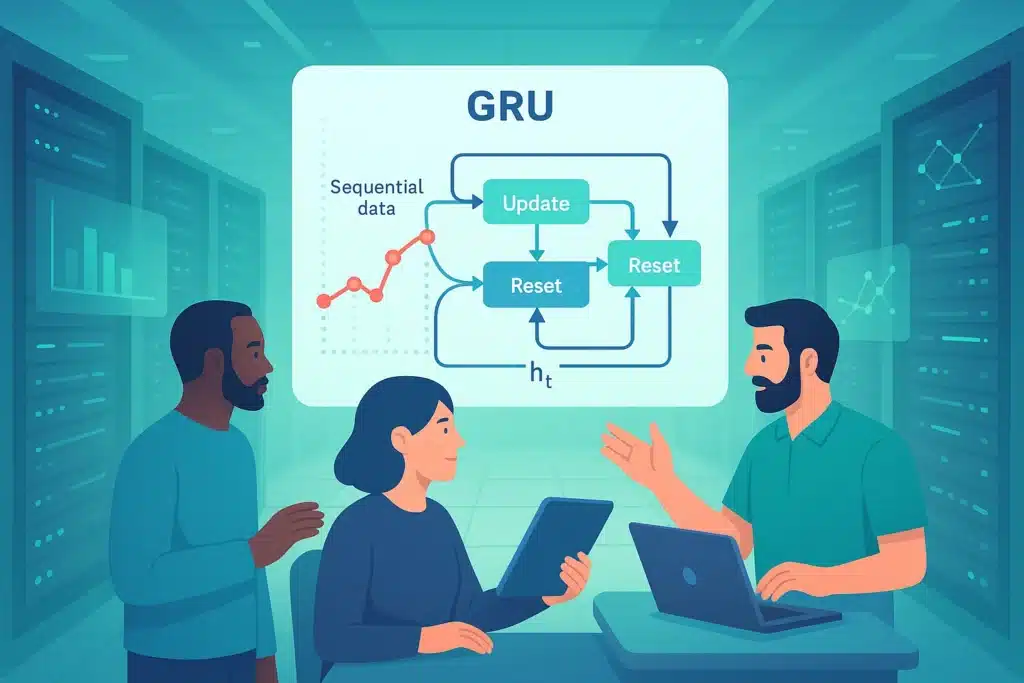
Pour un traitement efficace des données séquentielles en Deep Learning et en Machine Learning, il est essentiel de comprendre les Gated Recurrent Units (GRUs), ces réseaux neuronaux capables de se souvenir des informations clés sur la durée.
Les données qui ont une notion temporelle sont omniprésentes : texte, musique, valeurs boursières, données de capteurs … Le sens de chacune des données est déterminé par les éléments qui la précèdent : un mot prend sa signification complète en fonction des mots qui l’ont précédé dans une phrase ; la prédiction de la température de demain s’appuie sur les températures observées aujourd’hui et les jours précédents ; ou encore l’identification d’un motif dans un signal audio nécessite d’analyser la séquence sonore sur une certaine durée…
Les réseaux de neurones classiques ne sont pas adaptés à ce genre de séquences, car ils manquent de “mémoire”.
La première approche pour gérer correctement ce type de données a été les Recurrent Neural Networks (RNNs). Cependant, ceux-ci ont des difficultés à retenir les informations éloignées à cause du vanishing gradient (les gradients rétrécissant à chaque couche du RNN, ils deviennent alors de plus en plus petits, si petits qu’ils ne permettent plus de mettre à jour efficacement les poids des couches trop éloignées entre elles, on perd alors de l’information concernant le début d’une séquence lorsqu’on arrive à la fin de celle-ci).
Pour surmonter cette limitation cruciale et permettre aux réseaux de Deep Learning de traiter efficacement de longues séquences, des architectures plus sophistiquées de RNNs ont été développées.
Parmi les plus efficaces et les plus populaires se trouvent les Gated Recurrent Units (GRUs).
Les GRUs sont une amélioration des RNNs simples, conçus pour mieux gérer la mémoire, et donc la transmission d’information, sur de longues durées.
Le mécanisme clé : Les Portes (Gating Mechanism)
L’innovation majeure des GRUs, et des RNNs de leur famille (comme les LSTMs), réside dans l’utilisation de « portes » (gating mechanism). Au lieu de simplement mélanger l’entrée actuelle et l’état caché précédent (previous hidden state h t-1) de manière brute, comme le fait un RNN simple, les GRUs utilisent ces portes pour contrôler sélectivement et dynamiquement le flux d’informations à travers l’unité récurrente.
Ces portes agissent comme des filtres, basés sur des fonctions d’activation (comme la sigmoïde par exemple), pour décider quelles informations de l’ancienne mémoire et de la nouvelle entrée sont les plus importantes.
Un GRU utilise deux portes essentielles :
- La Porte de Réinitialisation (Reset Gate) : Cette porte décide quelle partie de l’état caché précédent est ignorée ou « oubliée » lors du calcul d’un état candidat potentiel pour le nouvel état caché.
- La Porte de Mise à Jour (Update Gate) : Décide combien de l’état caché précédent doit être conservé et combien du nouvel état candidat (qui représente la nouvelle information potentielle à intégrer) doit être ajouté pour former le nouvel état caché.
Ces mécanismes permettent au GRU de retenir ou d’oublier des informations sur de longues périodes.
GRU vs LSTM
Les Long Short Term Memory (LSTMs) sont très similaires aux GRUs, ils utilisent également des “portes” pour gérer leur mémoire à long terme et atténuer le vanishing gradient.
La différence avec les GRUs est qu’ils utilisent trois portes, contre seulement deux pour les GRUs, les rendant plus complexes et plus longs à entraîner.

Les avantages des GRUs
L’avantage principal des GRUs par rapport aux RNNs classiques, réside en sa capacité à capturer efficacement les dépendances entre les données d’une même série, même plus éloignée. En effet, grâce aux portes, le GRU peut sélectivement choisir de retenir des informations pertinentes sur de très longues séquences et d’ignorer celles qui ne le sont pas.
Par exemple, dans une phrase très longue, un GRU peut apprendre à maintenir en mémoire le sujet principal et le verbe, même s’ils sont séparés par de nombreux mots, pour assurer la cohérence grammaticale et sémantique à la fin de la phrase. Cette capacité les rend particulièrement performants pour comprendre le contexte dans de longues séries de données.
Ces portes permettent donc aux gradients de circuler plus directement à travers le temps, les empêchant ainsi de devenir trop petits (vanishing) lorsqu’ils remontent vers les premières couches du réseau. Cela stabilise l’entraînement et permet au réseau d’apprendre efficacement les poids qui capturent les dépendances long terme.
Les LSTMs suivent aussi ces principes. Cependant, les GRUs ont une architecture plus simple, avec moins de paramètres (moins de portes) que les LSTMs. Cela se traduit par une efficacité computationnelle accrue : ils sont généralement plus rapides à entraîner et à exécuter, tout en atteignant des performances de pointe sur une grande variété de tâches séquentielles, jusqu’à parfois même surpasser les LSTMs.
Ce qui est un avantage significatif pour les applications en temps réel ou lorsque les ressources de calcul sont limitées.

Quelles applications ?
Les avantages des GRUs ouvrent la porte à de nombreuses applications concrètes dans divers domaines :
- Natural Language Processing (NLP) : Les GRUs sont largement utilisés pour des tâches comme la traduction automatique, la génération de texte, l’analyse de sentiment, la reconnaissance vocale (speech recognition) et d’autres tâches où la compréhension du contexte séquentiel est cruciale.
- Séries Temporelles (Time Series) : Ils sont également efficaces pour la prédiction de valeurs futures basées sur un historique (prévisions financières, météorologiques, consommation d’énergie…).
- Modélisation de Séquences Diverses : Enfin, ils sont régulièrement utilisés pour générer de la Musique, des génomes, et toute autre donnée qui se présente sous forme de séquence ordonnée.
Conclusion
En résumé, les Gated Recurrent Units (GRUs) représentent une avancée significative par rapport aux Recurrent Neural Networks (RNNs) simples.
Grâce à leurs mécanismes de portes intelligents, ils gèrent efficacement la mémoire à long terme et surmontent les problèmes d’entraînement des RNNs simples, tels que le vanishing gradient.
Leur efficacité, leur robustesse et leurs bonnes performances en font un choix populaire en Deep Learning et Machine Learning pour une grande variété d’applications.










