
L’acronyme HDFS symbolise Hadoop Distributed File System. Comme son nom l’indique, HDFS est étroitement lié à l’outil Hadoop. À quoi sert HDFS ? Quel est le lien entre HDFS et Hadoop ? Comment HDFS fonctionne ? Nous allons répondre à toutes ces questions à l’aide de cet article.
Qu'est ce que Hadoop ?
Hadoop est outil open-source qui a révolutionné le monde informatique, c’est notamment grâce à lui que le Big Data a émergé. En effet, avec le Big Data (données de masse), nous sommes contraints de traiter des données volumineuses, et c’est une tâche longue et ardue avec les outils traditionnels. Avec Hadoop, nous passons par une architecture distribuée permettant de faire des économies de coût et des gains de performances.
La différence entre une architecture distribuée et une architecture classique réside dans l’utilisation d’un cluster de machines, autrement dit un groupe d’ordinateurs. Depuis Hadoop, les données sont partagées entre les machines du cluster et les opérations sont donc parallélisées. Il y a une distinction à faire entre les machines du cluster : certaines machines possèdent les données et traitent les données tandis qu’une les coordonne. Cette architecture est communément appelée « master-slave »(maître-esclave). Dans Hadoop, la machine « master » est appelée le Namenode et les machines « slaves » sont nommées Datanodes.
Maintenant que nous avons les notions basiques sur Hadoop, nous pouvons commencer à parler de HDFS. Pour avoir plus d’informations sur Hadoop, vous pouvez consulter cet article.

Quel est l'intérêt d'utiliser les HDFS ?
Nous avons mentionné les opérations réalisées avec Hadoop, mais cet outil est constitué de plusieurs composants. Nous traitons les données avec les opérations de MapReduce tandis que le composant Yarn sert à monitorer les différentes machines de votre cluster en leur allouant les ressources nécessaires. HDFS est conçu pour le stockage de fichier, comme l’indique son nom (Hadoop Distributed File System pour rappel), il s’agit d’un système de fichier.
Tout comme pour le système de fichier de notre système d’exploitation, tous les types de fichier peuvent être organisés dans différents dossiers (« hierarchical file system ») avec HDFS. Qu’il s’agisse de fichiers “classiques” comme csv ou json ou bien d’autres types de fichiers utilisés pour les tâches liées au Big Data tel que parquet, avro et orc. Nous ne sommes pas limités comme dans une base de données relationnelle, il faut plutôt voir HDFS comme un Data Lake. Nous y entreposons les données brutes de notre pipeline de données, puis nous y faisons des traitements pour les placer dans un Data Warehouse ou des bases de données.
Comment fonctionnent les HDFS ?
Si on peut le comparer avec un système de fichier classique d’un système d’exploitation, il y cependant des différences au niveau de l’usage et du stockage. En effet, nous sommes dans un cluster de machines, donc comment savoir dans quelle machine du cluster se trouvent nos données ? Vous l’avez sûrement deviné, nous allons employer le Namenode. Pour pouvoir administrer les différentes machines du cluster, le Namenode doit être au courant de l’état de chaque machine, c’est pourquoi nous pouvons y trouver des métadonnées.
En particulier, nous saurons dans quelles machines les données sont entreposées. Un autre avantage d’un cluster Hadoop est que nous sommes « fault tolerant » (tolérant à la panne). En effet, nous avons plusieurs machines à notre disposition, de ce fait nous allons pouvoir créer des copies de nos données et les répartir entre les machines. Ainsi, si une machine tombe en panne, nous pouvons toujours avoir accès aux données. Par ailleurs, les données ne sont pas réparties « entièrement » entre les machines, elles sont segmentées en blocs. Cela permet de se prémunir face aux risques de panne des machines en ne perdant que partiellement nos données.
Observons le schéma ci-dessous pour bien appréhender le stockage des données dans HDFS :
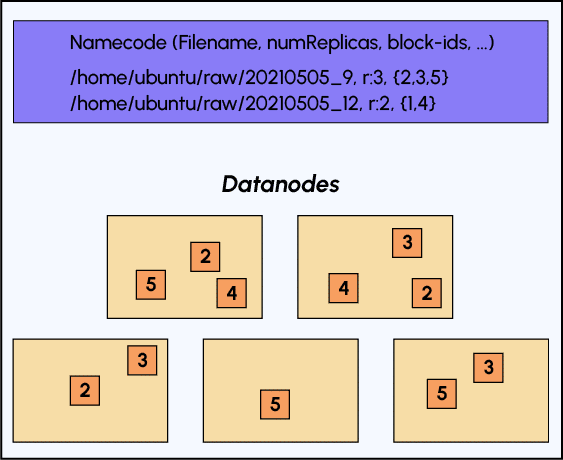
Comme énoncé précédemment, dans le namenode, nous retrouvons les métadonnées de notre fichier: son nom, le nombre de répliques et sa segmentation en blocs, mais d’autres métadonnées sont aussi disponibles.
Ces différents éléments nous confirment bien que l’utilisation de HDFS diffère d’une utilisation d’un système de fichier via une interface graphique. En fait, nous l’employons plus dans un aspect de batch processing et nous accèderons à nos données par un lien comme celui-ci « hdfs:/cluster-ip:XXXX//data/users.csv ».
Pour aller plus loin
Après avoir compris comment fonctionnait Hadoop, nous voulons maintenant pratiquer le système de fichier HDFS et la suite Hadoop. Cependant, il est difficile de l’utiliser en tant que particulier. La première raison est simplement car nous n’avons pas à notre disposition un cluster de machines. La seconde raison est que même avec un cluster de machines, il nous reste à installer Hadoop dessus et l’utiliser dans des problématiques de Big Data, ce qui est rarement nécessaire pour un particulier.
Vous pouvez en apprendre plus sur les différents composants de l’outil Hadoop en faisant la formation Data Engineer de DataScientest.
Vous en apprendrez également plus sur son « remplaçant » : Spark qui permet de traiter des données volumineuses bien plus rapidement qu’Hadoop, mais qui ne comporte pas d’aspect stockage, d’où son enseignement aux côtés de HDFS.








