Le word embedding désigne un ensemble de méthode d’apprentissage visant à représenter les mots d’un texte par des vecteurs de nombres réels. Aujourd’hui, nous allons vous présenter le 3ème volet de notre dossier NLP.
Vous avez raté les premiers épisodes ? Pas de panique les voici :
Cette section a pour but d’expliquer le fonctionnement et d’implémenter le célèbre algorithme Word2vec sur Python.
Word Embedding
Pour rappel, le word embedding est capable en réduisant la dimensionde capturer le contexte, la similarité sémantique et syntaxique (genre, synonymes, …) d’un mot.
Par exemple, on pourrait s’attendre à ce que les mots « remarquable » et « admirable » soient représentés par des vecteurs relativement peu distants dans l’espace vectoriel où sont définis ces vecteurs.
La méthode d’embedding généralement utilisée pour réduire la dimension d’un vecteur consiste à utiliser le résultat que retourne une couche dense, c’est à dire de multiplier une matrice d’embedding W par la représentation « one hot » du mot :

Sous forme vectorielle :


Embedding à l’aide du Word2vec
En revanche, pour éviter les contraintes de la première méthode, il est possible d’entraîner la matrice W de manière non supervisé avec simplement du texte à l’aide du célèbre algorithme Word2Vec.
Comment word2vec fonctionne ?
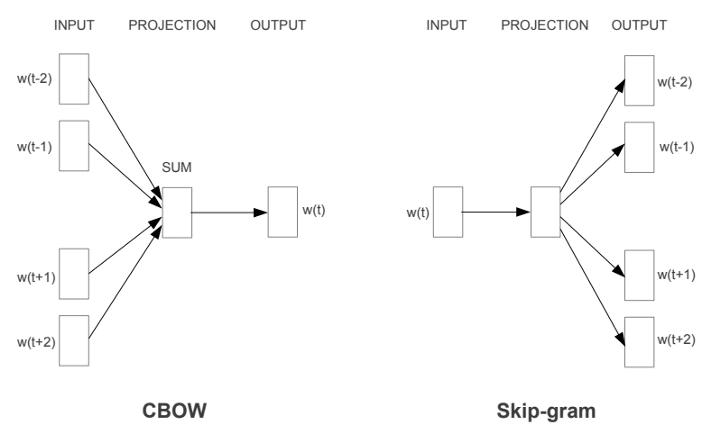
Il existe deux variantes du Word2vec, les deux utilisent un réseau de neurones à 3 couches (1 couche d’entrée, 1 couche cachée, 1 couche de sortie) : Common Bag Of Words (CBOW) et Skip-gram.
Dans l’image suivante, le mot dans la case bleu est appelé le mot cible et les mots dans les cases blanches sont appelés mots du contexte dans une fenêtre de taille 5.

CBOW : Le modèle est nourri par le contexte, et prédit le mot cible. Le résultat de la couche cachée est la nouvelle représentation du mot (ℎ1, …, ℎ𝑁).
Skip Gram : Le modèle est nourri par le mot cible, et prédit les mots du contexte. Le résultat de la couche cachée est la nouvelle représentation du mot (ℎ1, …, ℎ𝑁).
Mise en forme des données
Ici, nous allons présenter le modèle CBOW c’est-à-dire que le contexte est l’entrée de notre modèle et le mot cible (mot bleu) est la sortie. Nous définissons une fenêtre de longueurs 5 pour le contexte (entrée).

Modèle
Le modèle CBOW a des similitudes avec le modèle de classification que l’on vient d’implémenter dans la partie précédente. Notre modèle sera composé des couches suivantes :

- La couche Embedding va transformer chaque mot du contexte en vecteur d’embedding. La matrice W de l’embedding sera apprise au fur et à mesure que le modèle s’entraîne. Les dimensions résultantes sont : (lot, context_size, embedding).
- Ensuite, la couche GlobalAveragePooling1D permet de sommer les différents embedding pour avoir une dimension en sortie (batch_size, embedding).
- Enfin, La couche Dense de taille « voc_size » permet de prédire le mot cible.
La fonction de perte cross-entropy est généralement utilisée pour entraîner le modèle :
Métrique dans cette espace
Maintenant que le modèle est entraîné, il peut être intéressant de comparer la distance entre les mots.
La « Cosine similarity » est généralement utilisée comme métrique pour mesurer la distance lorsque la norme des vecteurs n’a pas d’importance. Cette métrique capture la similitude entre deux mots.
Plus la cosine similarity » est proche de 1, plus les deux mots sont liés.
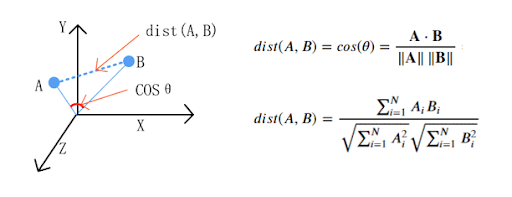
Avec cette métrique et dans ce sous-espace vectoriel, les 5 mots les proches de « body » sont :
intestines -- 0.30548161268234253
bodies -- 0.2691531181335449
arm -- 0.24878980219364166
chest -- 0.2261650413274765
leg -- 0.2193179428577423
Les nombres ci-dessus représentent les distances cos-similarité entre le mot « body » et des mots les plus proches.
Pour le mot « <b>zombie </b>» :
slasher -- 0.3172745406627655
cannibal -- 0.28496912121772766
zombies -- 0.2767203450202942
horror -- 0.2607246935367584
zombi -- 0.25878411531448364
Pour le mot « <b>amazing </b>» :
brilliant -- 0.3372475802898407
extraordinary -- 0.319326251745224
great -- 0.29579296708106995
breathtaking -- 0.2907085716724396
fantastic -- 0.2871546149253845
Pour le mot «<b> god</b> » :
heavens -- 0.268303781747818
jesus -- 0.26807624101638794
goodness -- 0.2618488669395447
gods -- 0.24795521795749664
doom -- 0.22242328524589539
Propriétés arithmétiques
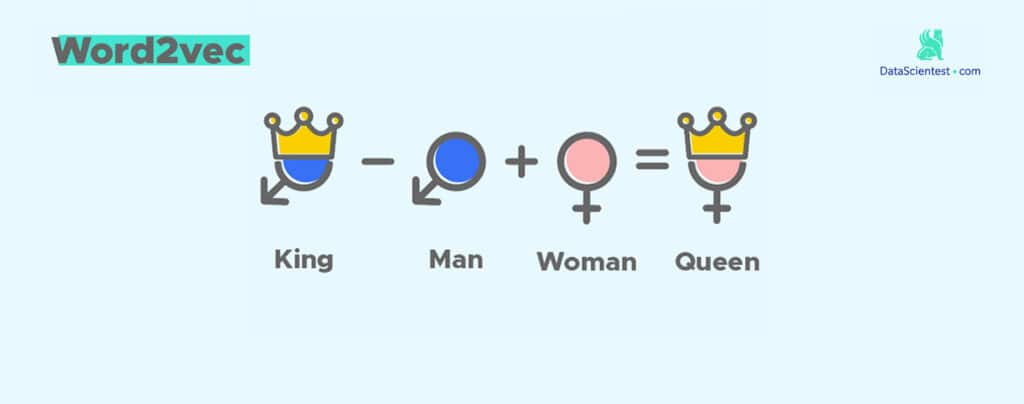
Nous pouvons maintenant nous poser la question si notre sous-espace vectoriel des mots a des propriétés arithmétiques. Prenons le célèbre exemple suivant :
𝐾𝑖𝑛𝑔 − 𝑀𝑎𝑛 + 𝑊𝑜𝑚𝑎𝑛 = 𝑄𝑢𝑒𝑒𝑛
Dans cet exemple la propriété arithmétique est la royauté. Nous souhaitons vérifier si cette propriété va se propager à « woman ». C’est-à-dire que nous allons rechercher les mots les plus proches du vecteur suivant :
arithmetic_vector = word2vec[index_word1] – word2vec[index_word2] + word2vec [index_word3]
Ici, le mot « queen » n’est pas beaucoup représenté dans notre jeu de données, ce qui explique une mauvaise représentation. Pour cette raison, nous allons plutôt nous intéresser à la propriété de nombre :
Men − 𝑀𝑎𝑛 + 𝑊𝑜𝑚𝑎𝑛 = Women
En utilisant l’opération définie précédemment et une métrique de cos similarité, les 5 mots les plus proches sont :
women -- 0.2889893054962158
females -- 0.272260844707489
strangers -- 0.24558939039707184
teens -- 0.2443128377199173
daughters -- 0.24117740988731384
Le résultat pour Zombies − Zombie + 𝑊𝑜𝑚𝑎𝑛 :
women -- 0.2547883093357086
females -- 0.23258551955223083
ladies -- 0.22764989733695984
stripper -- 0.22274985909461975
develops -- 0.2202150821685791
Le résultat pour Men − Man + Soldier :
soldiers -- 0.3547001779079437
daughters -- 0.21896378695964813
letters -- 0.21452251076698303
backyard -- 0.21437858045101166
veterans -- 0.21067838370800018
Le résultat pour Zombies − Zombie + monster :
werewolves -- 0.2724993824958801
monsters -- 0.25695472955703735
creature -- 0.24453674256801605
dragons -- 0.22363890707492828
bloke -- 0.21858260035514832
Ici, le mot « monsters » et « werewolves » semblent être très proche dans le contexte de notre jeu de données.
En utilisant une ACP, nous pouvons trouver la dimension de la propriété de nombre :
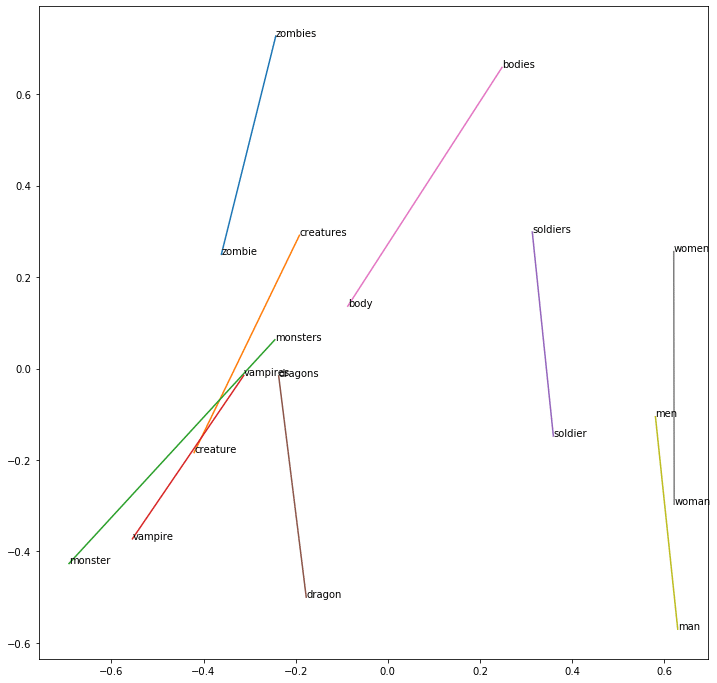
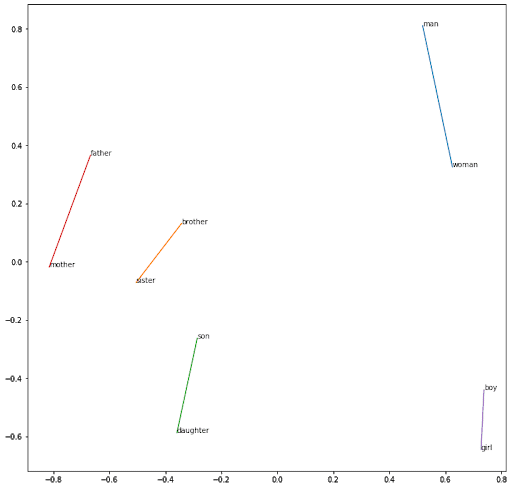
En utilisant le même raisonnement pour capturer le genre :
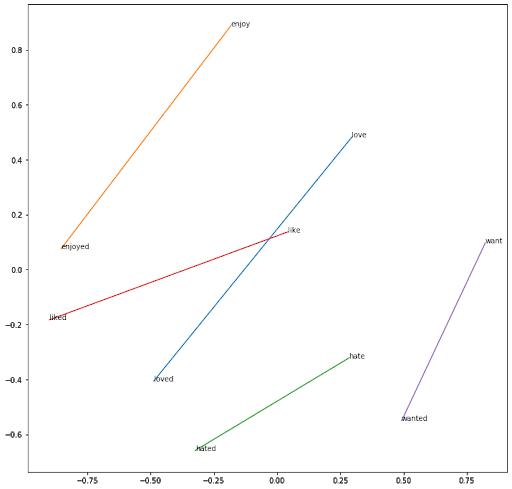
En utilisant le même raisonnement entre les verbes à l’infinitif et les verbes finissant par -ed :
Le « word2vec embedding » capture efficacement les propriétés sémantiques et arithmétiques d’un mot. Il permet également de réduire la dimension du problème et par conséquent la tâche d’apprentissage.
Nous pouvons nous imaginer utiliser l’algorithme word2vec pour pré-entraîner la matrice d’embedding du modèle de classification. Par conséquent, notre modèle de classification aura une bien meilleure représentation des mots lors de la phase d’apprentissage des sentiments.
Envie de démarrer une formation plus détaillée sur les différents aspects abordés de cet article ?









