
Ces dernières années, la technologie de reconnaissance faciale a proliféré, trouvant une utilisation accrue dans différents domaines tels que les médias, les réseaux sociaux, la surveillance ou encore la sécurité. L'apprentissage profond, ou Deep Learning, permet au réseau d’apprendre automatiquement à partir des données.
L’apprentissage profond s’est en effet avéré très efficace pour reconnaître les visages, avec la capacité de gérer d’énormes volumes de données et d’atteindre des taux de précision élevés. La capacité du Deep Learning à extraire automatiquement des informations à partir d’images, telles que les traits du visage, les couleurs ou encore les contrastes de façon automatisée est l’un de ses principaux avantages pour la reconnaissance faciale.En d’autres termes, le réseau de neurone est capable d’apprendre les propriétés clés de l’identification, conduisant à un système de reconnaissance fiable et précis.
Le traitement des données, l'étape la plus importante du processus
Le prétraitement est une étape cruciale avant que les données d’image ne soient introduites dans le modèle de reconnaissance faciale. Selon les propriétés de l’ensemble de données à disposition et les exigences particulières de l’application, les étapes de prétraitement requises peuvent varier. On retrouve cependant parmi elles des opérations courantes.
Par exemple, la mise à l’échelle de l’image permet de fixer la taille des images pour l’ensemble des échantillons. En définissant une résolution de 256 x 256 pixels, le modèle est assuré de traiter des images de la même taille, ce qui peut augmenter les performances du modèle.
On peut également mentionner le processus de normalisation qui aidera très probablement votre modèle dans son fonctionnement. Pour ce faire, les données d’une image peuvent être transformées dans un espace colorimétrique particulier, ou les valeurs de pixel peuvent être modifiées pour avoir une moyenne nulle et une variance unitaire (distribution gaussienne).
L’alignement du visage sur les photos joue également un rôle majeur car les performances du modèle peuvent être affectées par la position du visage. Les repères faciaux peuvent être utilisés pour l’alignement, et le visage peut être recadré à une position spécifiée à l’aide d’un cadre de délimitation, communément appelé bounding box.

L’augmentation des données : en utilisant différentes modifications d’images, telles que le retournement, la rotation ou le recadrage, l’augmentation des données est une technique utilisée pour améliorer fictivement la quantité de l’ensemble de données. Cela pourrait contribuer à améliorer la résilience et la généralisabilité du modèle. Ci-dessous, l’œil humain est totalement capable d’identifier qu’il s’agit de la même image ayant subi certaines transformations. Cependant, aux yeux de la machine, les pixels ayant changé de position, l’image sera traitée comme un nouvel échantillon.

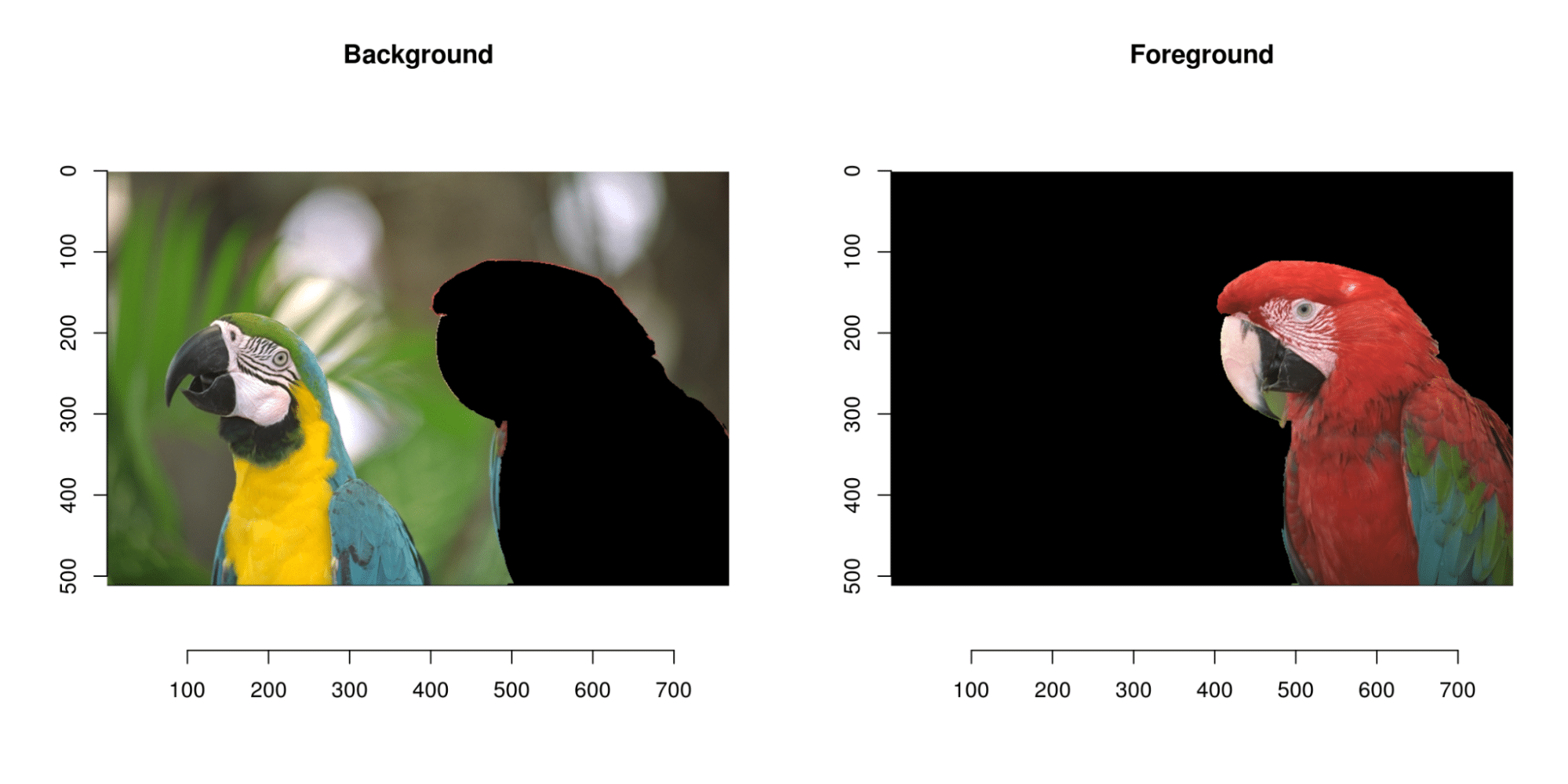
Nous pouvons également mentionner la suppression du fond : les performances du modèle peuvent être améliorées en supprimant le bruit de fond de l’image. Cela peut être accompli en séparant l’arrière-plan du premier plan à l’aide de techniques de segmentation d’image telles que le seuillage ou la détection de contour.
Il est important de garder à l’esprit que les procédures de prétraitement utilisées dépendent des caractéristiques de l’ensemble de données et des besoins particuliers de l’application.
Vous l’aurez donc compris, le prétraitement est une étape cruciale dans les travaux de reconnaissance faciale car il prépare les données d’images pour le modèle et améliore l’efficacité, la vitesse et l’efficience du système. La mise à l’échelle des images, la normalisation, l’alignement, l’augmentation des données, la suppression de l’arrière-plan et la détection des visages sont des exemples de techniques de prétraitement fréquentes.
Convolutional neural network (CNN) : Définition, caractéristiques et fonctionnement
Les réseaux de neurones convolutif sont un type d’architecture d’apprentissage en profondeur particulièrement bien adapté aux tâches de reconnaissance d’images telles que la reconnaissance faciale.
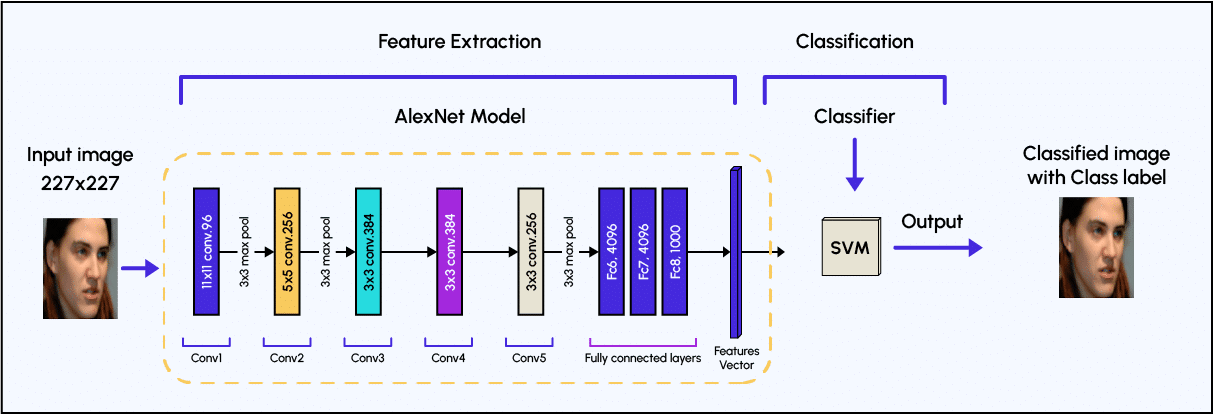
Dans un CNN pour la reconnaissance faciale, le réseau est formé sur un ensemble de données d’images de visages et d’images ne comportant pas de visages. Le CNN apprend à identifier les caractéristiques importantes d’un visage, telles que la forme des yeux, du nez et de la bouche, ainsi que la géométrie générale et la texture du visage. Ces caractéristiques sont ensuite utilisées pour identifier un visage dans une nouvelle image.
L’architecture d’un CNN se compose généralement de plusieurs couches, chacune ayant une fonction spécifique. La première couche, appelée couche d’entrée, reçoit les données d’image brutes. Les couches suivantes, appelées couches convolutionnelles ou couches cachées, utilisent un ensemble de filtres pour extraire les caractéristiques de l’image. Ces filtres glissent sur l’image (étape de convolution), recherchant des motifs et des caractéristiques spécifiques.
Les caractéristiques résultantes sont ensuite passées à travers une fonction d’activation non linéaire, telle qu’une unité linéaire rectifiée (ReLU), qui introduit une non-linéarité dans le réseau et lui permet d’apprendre des modèles plus complexes.
Après les couches convolutionnelles, le réseau comprend des couches de regroupement ou pooling, qui réduisent la résolution spatiale des caractéristiques apprises par le réseau tout en conservant des informations importantes. Cela se fait en prenant le maximum ou la moyenne d’une petite région de la carte des caractéristiques. Les couches de pooling rendent le réseau plus robuste aux petits changements de position du visage dans l’image.

Enfin, les caractéristiques sont transmises à travers des couches entièrement connectées (fully connected layer), qui effectuent la tâche de classification. Ces couches produisent une probabilité pour chaque classe possible, dans le cas de la reconnaissance faciale, un visage ou pas de visage. Cette sortie est ensuite comparée à un seuil, pour prendre la décision finale. Ce seuil permet de décider de la précision que l’on souhaite pour prendre la décision. Par exemple, si le seuil est à 0.9, le modèle effectue la tâche de reconnaissance faciale uniquement lorsque sa performance lors de l’association de l’image à une personne en particulier est supérieure à cette valeur.
Il est important de noter que les CNN pour la reconnaissance faciale sont formés avec un grand ensemble de données d’images de différents individus, ce qui leur permet d’identifier un large éventail de personnes avec une grande précision. Cependant, il est nécessaire d’avoir un ensemble de données diversifié pour éviter les biais, car les performances de ces modèles peuvent être affectées par la démographie des individus dans l’ensemble de données.
Quelles sont les architectures concurrentes aux réseaux de neurones convolutif ?
Plusieurs nouvelles architectures d’apprentissage en profondeur (ou Deep Learning Architectures) ont été développées pour la reconnaissance faciale ces dernières années. Voici quelques exemples :
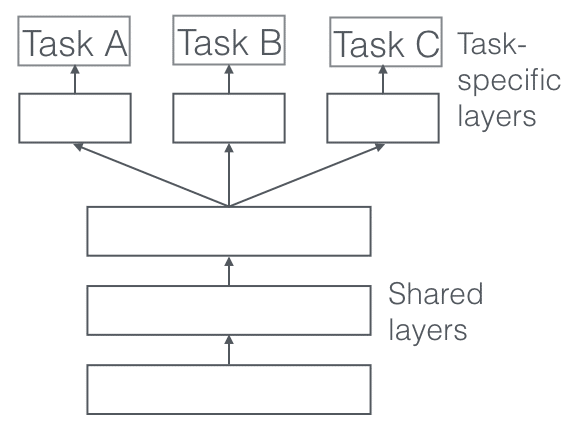
Architectures d’apprentissage multi-tâches (MTL) : l’apprentissage multi-tâches est un type d’architecture d’apprentissage en profondeur capable d’apprendre plusieurs tâches simultanément, telles que la reconnaissance faciale et la détection de repères faciaux. Cela peut améliorer les performances globales du modèle et réduire la quantité de données nécessaires à la formation.
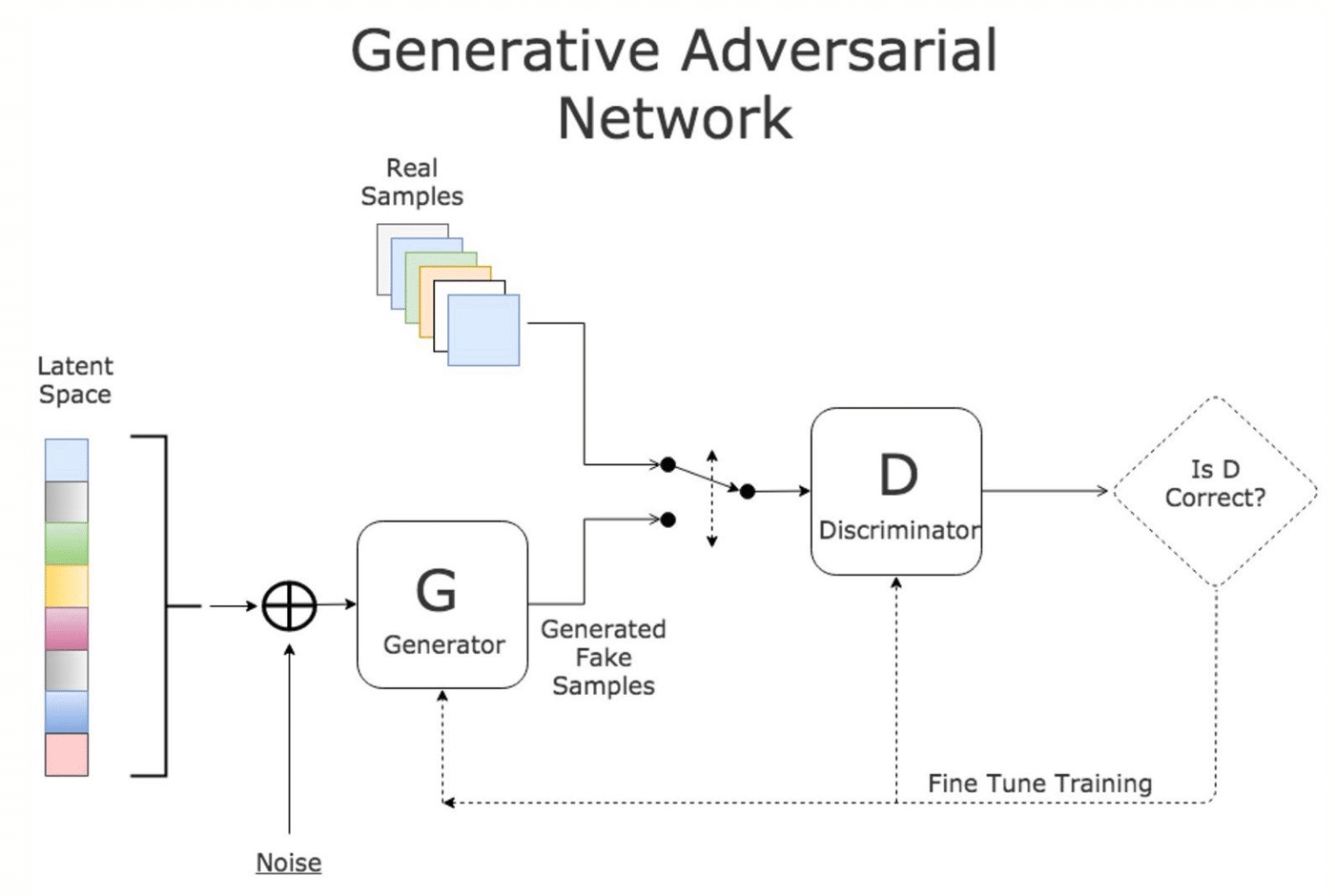
Réseaux antagonistes génératifs (GAN) : les GAN sont un type d’architecture d’apprentissage en profondeur qui se compose de deux réseaux : un générateur et un discriminateur. Le générateur crée de nouvelles images similaires aux données d’apprentissage, tandis que le discriminateur essaie de faire la distinction entre les images générées et les images réelles. Les GAN ont été utilisés pour la reconnaissance faciale en entraînant le générateur à créer des images de visages pouvant tromper le discriminateur.
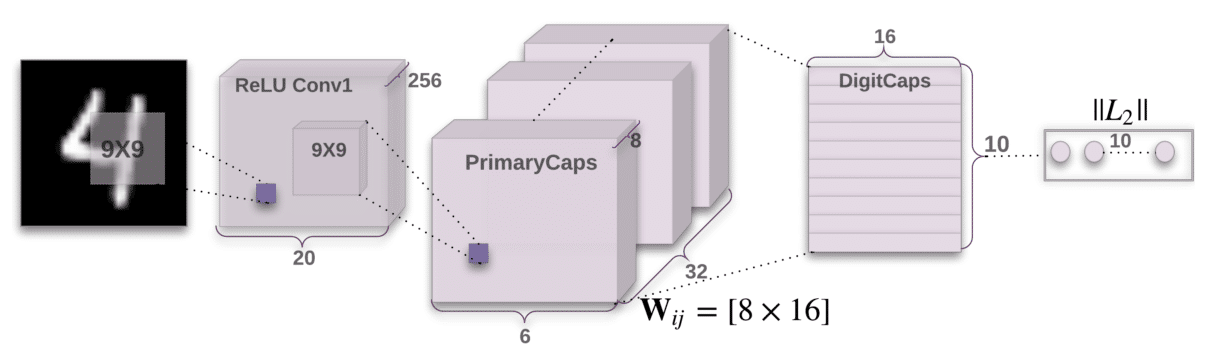
Réseaux de capsules : les réseaux de capsules sont un type d’architecture de Deep Learning conçu pour mieux capturer les relations spatiales entre les parties d’une image, telles que la position des yeux, du nez et de la bouche sur un visage. Cela peut améliorer la précision de la reconnaissance faciale, en particulier lorsqu’il s’agit de visages partiellement occultés ou sous des angles différents.
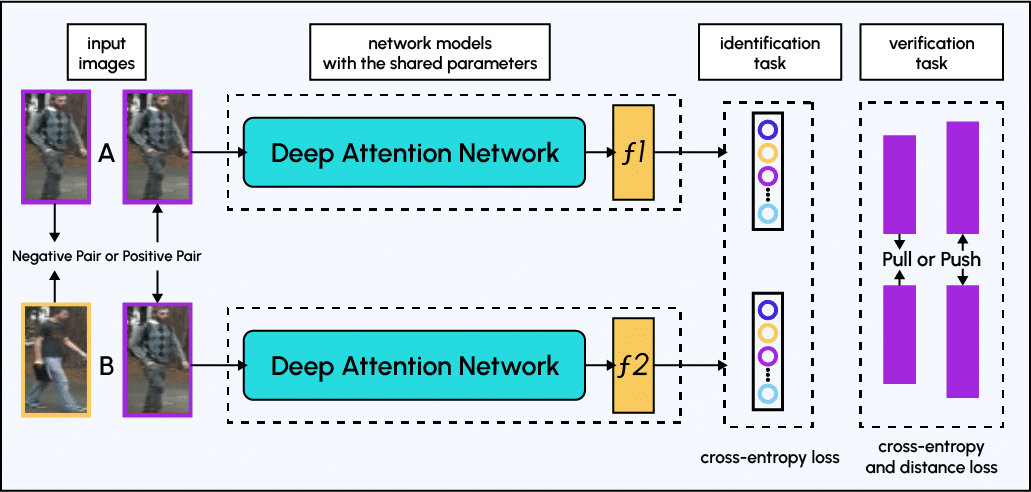
Modèles basés sur l’attention : les modèles basés sur l’attention sont des architectures d’apprentissage en profondeur qui utilisent des mécanismes d’attention pour se concentrer sur les régions les plus informatives d’une image, telles que les yeux, le nez et la bouche d’un visage. Cela peut améliorer les performances de la reconnaissance faciale, en particulier lorsqu’il s’agit de visages partiellement occultés ou sous des angles différents.
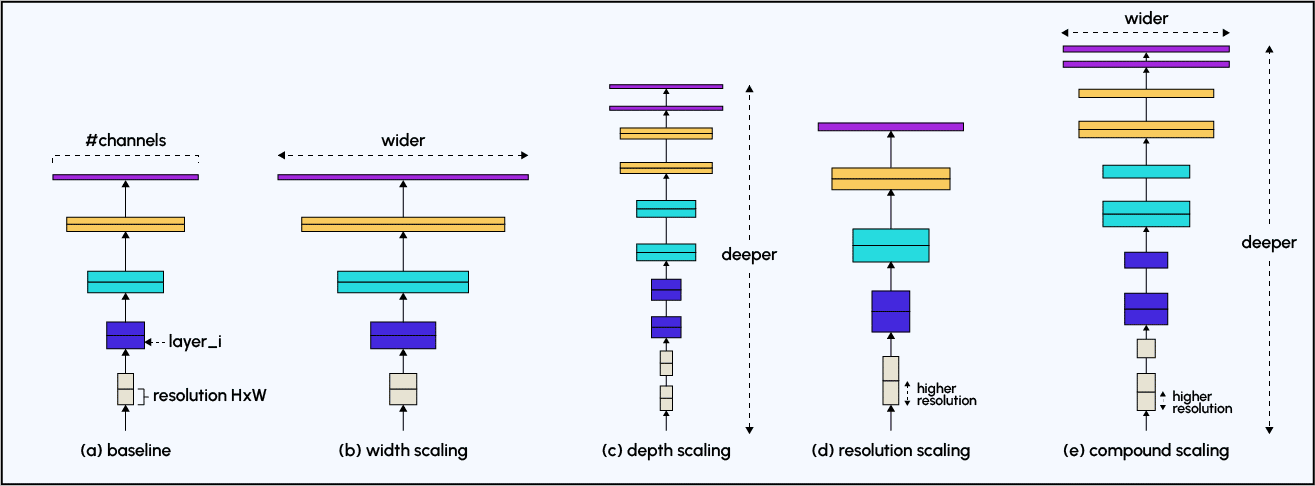
Architectures légères : les architectures légères telles que MobileNet, ShuffleNet et EfficientNet sont conçues pour être moins coûteuses en calcul que les CNN traditionnels. Cela peut les rendre plus adaptés à la reconnaissance faciale sur les appareils mobiles et les systèmes embarqués avec des ressources de calcul limitées.
Il est important de noter que ces architectures font toujours l’objet de recherches et d’améliorations et que la meilleure architecture pour un cas d’utilisation spécifique dépend des caractéristiques de l’ensemble de données, des ressources de calcul disponibles et des exigences spécifiques de l’application.
Reconnaissance faciale et RGPD : Est-ce compatible ?
La technologie de reconnaissance faciale crée d’importants problèmes d’éthique et de confidentialité, en particulier lors de l’application de l’apprentissage en profondeur ou Deep Learning. En effet, l’utilisation de la reconnaissance faciale soulève des questions sur la confidentialité et la possibilité d’une utilisation abusive des données. De plus, il existe des problèmes de biais dans les données de formation, ce qui peut entraîner des erreurs et des préjugés envers des groupes spécifiques.

Pour cette raison, il est essentiel de mettre en place des lois et des politiques appropriées pour garantir l’utilisation responsable de cette technologie.
Le règlement général sur la protection des données (RGPD) est un règlement de l’Union européenne (UE) qui est entré en vigueur le 25 mai 2018. Il remplace la directive européenne sur la protection des données de 1995 et renforce les lois européennes sur la protection des données. Le RGPD réglemente la collecte, le stockage et l’utilisation des données personnelles, y compris les données biométriques telles que la reconnaissance faciale.
La technologie de reconnaissance faciale, qui utilise des algorithmes pour identifier et faire correspondre le visage d’une personne, peut traiter des données biométriques telles que les traits du visage, les motifs géométriques et même les caractéristiques comportementales. Cela signifie que la technologie de reconnaissance faciale relève du champ d’application du RGPD, car elle traite des données personnelles.
En vertu du RGPD, les organisations doivent obtenir le consentement explicite des individus pour la collecte et le traitement de leurs données personnelles. Les organisations doivent également informer les individus des finalités spécifiques pour lesquelles leurs données seront utilisées et de la durée de leur conservation. Ils doivent également offrir aux personnes un droit d’accès, de rectification ou de suppression de leurs données personnelles.
De plus, les organisations utilisant la technologie de reconnaissance faciale doivent effectuer une évaluation de l’impact sur la protection des données (AIPD) avant de déployer la technologie. Une DPIA (en anglais, Data Protection Impact Assessment) est un processus qui aide les organisations à identifier et à atténuer les risques associés au traitement des données personnelles. Cela comprend l’évaluation de l’impact de la technologie sur les droits et libertés des individus, ainsi que l’évaluation de l’efficacité des mesures mises en place pour protéger les données personnelles.









