Qu’est ce que le web scraping ?
En tant que Data Scientist, Data Engineer ou Data Analyst vous êtes amené à manipuler des jeux de données qui alimenteront une application, un algorithme de Machine Learning ou une analyse de données.
Dans certains cas, vous pouvez utiliser des jeux de données déjà construits, mais il arrive que vous ayez à constituer le jeu de données vous-même ou à compléter un jeu de données en récupérant des informations sur internet.
Récupérer manuellement des informations, par exemple en copiant-collant le contenu qui vous intéresse sur chaque page est impensable si la quantité d’informations à récupérer est importante. Heureusement, il est possible d’automatiser la collecte de contenu sur internet grâce au web scrapping.
Le web scraping désigne la récupération de données et de contenu de manière automatique sur internet. Python dispose de plusieurs librairies qui permettent d’effectuer du web scraping.
Parmi elles, la librairie Beautiful Soup est sans doute la plus connue et a l’avantage d’être simple d’utilisation. Elle n’est cependant pas capable de récupérer des informations insérées dynamiquement sur une page web via JavaScript. Aujourd’hui, nous nous intéresserons au framework Selenium qui a entre autres, l’avantage de le permettre.
Pourquoi utiliser Selenium pour web scrapper des données ?
Selenium est un framework open-source initialement développé pour exécuter des tests automatisés sur différents navigateurs (Chrome, Internet Explorer, Firefox, Safari,…). Cette librairie est également utilisée pour effectuer du web scraping, car elle permet de naviguer entre des pages internet et d’interagir avec les éléments de la page comme un utilisateur réel. Ainsi, il devient possible de scraper des sites web dynamiques, c’est-à-dire, des sites qui retournent un certain résultat à l’utilisateur en fonction de ses actions.
Dans la suite de cet article, nous verrons comment utiliser Selenium pour récupérer des articles d’actualité sur le site d’Euronews et constituer un dataframe prêt à être utilisé dans le cadre d’un projet de text mining.
Cas pratique : web scraping sur des articles de presses récupérés sur Euronews
Pour implémenter notre script de web scraping et notre analyse, nous utiliserons Jupyter Notebook. Tout d’abord, il sera nécessaire d’installer les différentes librairies nécessaires à l’utilisation de Selenium via un pip install sur votre environnement python.
```
pip install selenium
pip install webdriver_manager
```
Le module Selenium donne accès :
- Au webdriver de Selenium, composant essentiel qui interprète notre code, ici en langage python, et interagit avec le navigateur. Dans le cadre de ce tutoriel, nous utiliserons un web driver qui contrôle le navigateur Chrome.
- À la méthode By qui permet d’interagir avec le DOM et de trouver des éléments sur la page web.
Le module WebDriver Manager assure la gestion (le téléchargement, la configuration et la maintenance) des pilotes requis par Selenium WebDriver.
Importons maintenant, les librairies dont nous aurons besoin :
Ça y est, nous pouvons entrer dans le vif du sujet. Nous allons scraper les articles d’Euronews de la veille.
Voici un descriptif des différentes étapes que nous allons réaliser :
- Nous rendre sur la page d’archive d’articles de la veille
- Récupérer les liens de tous les articles parus la veille de la date du jour et les stocker dans une liste
- Itérer sur les liens contenus dans notre liste et créer une autre liste contenant un dictionnaire pour chaque article avec :
- Le titre de l’article
- La date à laquelle il est paru
- Les auteurs
- Les paragraphes de l’article
- La catégorie
- Le lien vers l’article
- Effectuer une rapide analyse visuelle de notre corpus de texte
Etape 1 : Utiliser Selenium pour accéder aux articles de la veille
Tout d’abord, commençons par nous intéresser à la structure de l’url des archives d’euronews. Pour récupérer les articles d’un jour donné, l’url est de la forme : https://www.euronews.com/{years}/{month}/{days}
Nous remarquons également qu’il y a une pagination à 30 articles par page et que lorsque le nombre d’articles est supérieur à 30, il est possible de passer d’une page à l’autre en insérant un query param dans l’url : https://www.euronews.com/{years}/{month}/{days}?p={page}
Photo à insérer :
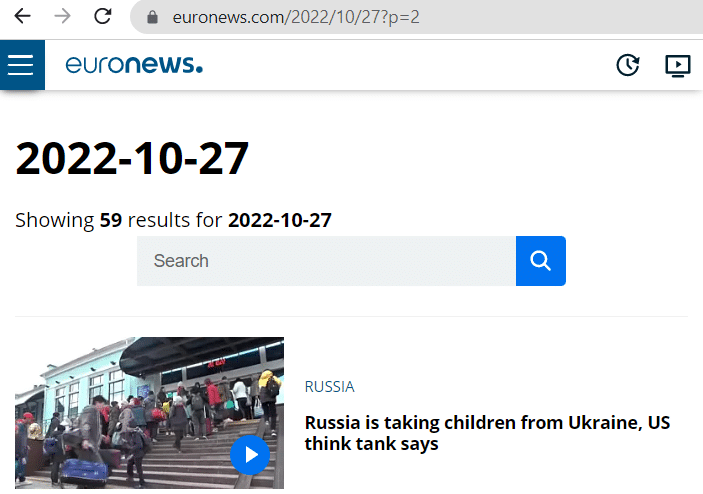
Testons la librairie Selenium en initialisant un webdriver Chrome. Le code ci-dessous nous permet d’effectuer automatiquement avec Selenium tout ce que nous aurions fait manuellement : ouverture du navigateur, accès à la page d’Euronews contenant les articles de la veille, clic sur le bouton d’acceptation des cookies et scroll sur la page.
Prise de contrôle d’un navigateur Chrome grâce à Selenium
Etape 2 : Récupérer les liens des articles
Quelque soient les librairies de web scraping utilisées, il est nécessaire d’inspecter la page pour identifier les éléments de la page web qui nous intéressent. Nous pouvons y accéder via les sélecteurs CSS.
Pour inspecter une page, effectuer un clic droit, puis cliquer sur « Inspecter » ou utiliser le raccourci Ctrl + Cmd + C sur macOS ou Ctrl + Shift + C sur Windows et Linux.
Comment inspecter une page web ?
Grâce à la classe BY de Selenium (qu’on utilisera plutôt que la méthode .find_elements_by), nous avons le choix entre plusieurs types de propriétés pour localiser un élément sur une page web, entre autres :
- L’ID de l’élément
- Le nom de l’élément
- Le nom de balise
- Son Xpath
- Sa classe
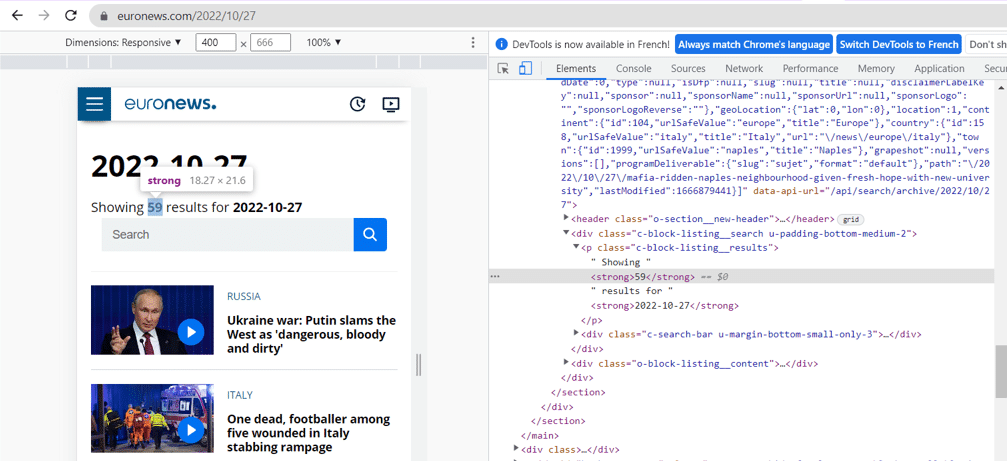
Après avoir inspecté, nous voyons que le compteur d’élément est situé dans la première balise strong de la classe « c-block-listing__results ».
Pour récupérer l’élément nous allons utiliser son XPath. Le XPath est un chemin XML qui permet de naviguer dans la structure HTML d’une page et de trouver n’importe quel élément sur celle-ci. En web scraping, il est particulièrement utile de passer par le chemin XPath d’un élément lorsque la classe de l’élément ne suffit pas à l’identifier, par exemple lorsque nous souhaitons récupérer une sous balise d’un élément d’une certaine classe.
Le Xpath d’un élément HTML est structuré ainsi :
//tag_name_of_major_element[@attribute=”Value”]/tag_name_of_sub_element[index_of_the_sub_element]
Où :
- tag_name_of_major_element correspond à la balise principale (div, img, p, b etc.)
- attribute correspond à la classe ou l’id de l’élément et value à sa valeur
- tag_name_of_sub_element correspond au tag de la sous-balise
- index_of_the_sub_element commence à 1 et correspond au numéro de la sous balise. Cet index n’est que s’il y a plusieurs sous-éléments contenus dans le tag principal.
La méthode .text, nous permet d’accéder à la valeur du texte de l’élément, ici « 57 ».
Grâce au nombre d’articles récupérés et la pagination à 30 que nous avons observée, nous calculons le nombre de pages que nous devrons scraper, ici 2.
Nous allons maintenant récupérer les liens des différents articles. En inspectant, on remarque que les liens des articles ont la classe object__title__link. On récupère tous les éléments qui ont cette classe et on crée une liste qui contient pour chaque élément, la valeur de l’attribut href (qui contient le lien) que l’on a récupéré grâce à la méthode get attribute.
Etape 3 : Scraping du contenu de chaque article
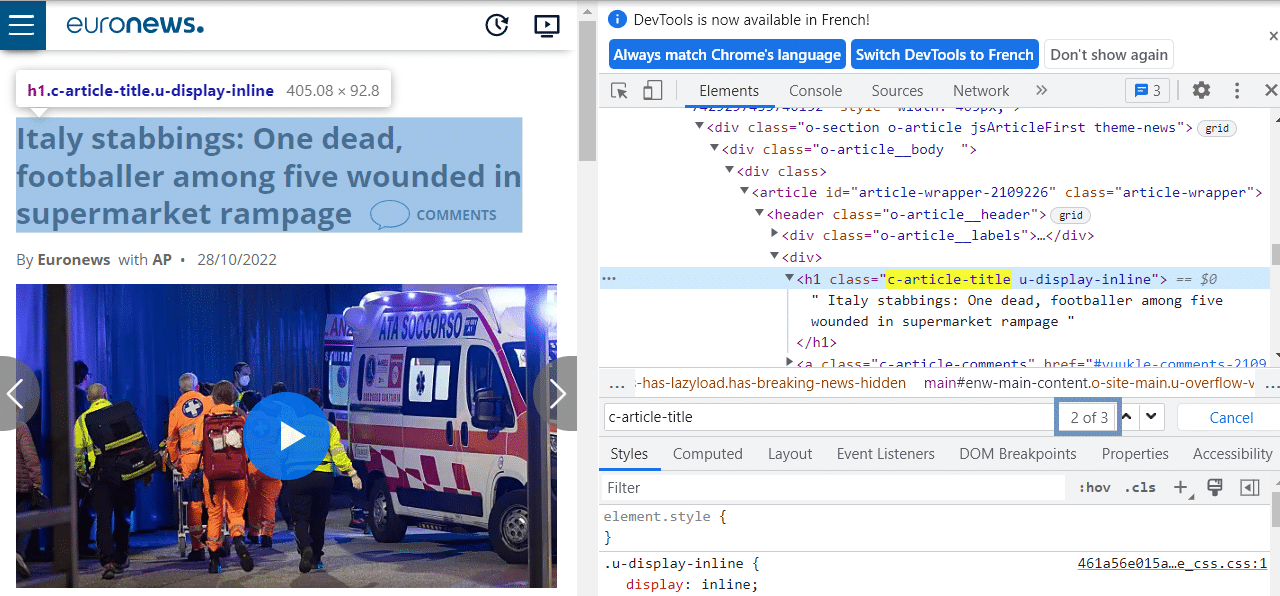
On remarque que les données contextuelles qui nous intéressent comme le titre, l’auteur, la catégorie etc. sont toujours situées en deuxième position des classes qu’on a localisées. En effet, en première position, le HTML contient des informations sur l’article précédent qui ne sont pas affichés sur la page.
Le code ci-dessous permet de récupérer les contenus qui nous intéressent sur la page :
Voici les différentes étapes du code précédent :
- On accède à chaque article
- On récupère le texte des données contextuelles de l’article (titre, auteurs, catégorie, date de publication)
- On récupère les paragraphes de l’article
- On crée un dictionnaire avec les données récupérées
- On ajoute ce dictionnaire à une liste nommée « list_of_articles »
- En cas d’erreur, on enregistre le lien de l’article dans une liste « errors ».
NB : On remarque que la majorité des articles en erreur sont des articles vidéo dont la structure html diffère. Dans le cadre de cet article, nous décidons de ne pas gérer les quelques cas d’erreurs
Voici en vidéo, le résultat de notre code pour les premières pages scrapées.
Naviguer automatiquement de page en page grâce à Selenium
Etape 4 : Rapide visualisation
Avant de conclure, nous allons effectuer une rapide visualisation des articles scrapés. Cette étape pourrait s’inscrire dans les premières étapes d’un projet de Natural Processing Language (NLP).
Tout d’abord, nous importons les librairies nécessaires pour la suite puis, nous constituons un dataframe grâce à la liste de dictionnaires list_of_articles.

Dans un premier temps, nous nous intéressons aux différentes catégories d’articles en affichant le nombre d’articles par catégorie grâce à la librairie Seaborn.

Avant d’afficher le nuage de mots, nous supprimons les stopword grâce à la classe stopwords du package nltk.corpus.
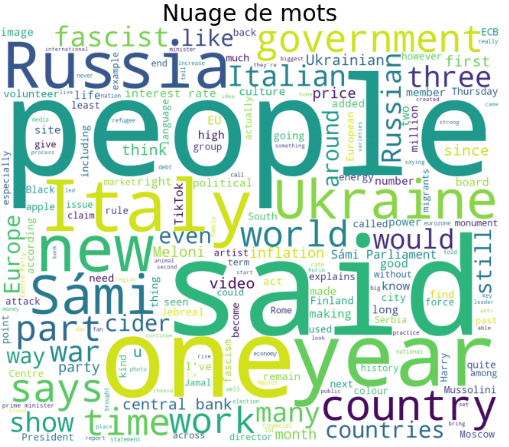
Voilà, nous arrivons au bout de ce tutoriel qui a permis de voir comment Selenium peut vous aider à scraper des données sur internet et a donné l’occasion de réaliser une rapide analyse visuelle sur des données textuelles.
Si cet article vous a plu, et que vous souhaitez découvrir de nouveaux cas d’usage utilisant Selenium vous pouvez regarder le webinar réalisé par un de nos Data Scientists sur le sujet :
Si vous souhaitez en savoir davantage sur le contexte d’utilisation du web scraping dans les différents métiers de la data, n’hésitez pas à consulter notre article à ce sujet ou à vous informer sur le contenu de nos différents cursus.









