Définition de Test Unitaire
Le test unitaire, en programmation informatique, désigne la procédure qui permet de s’assurer du bon fonctionnement d’un logiciel ou d’un code source (respectivement d’une partie d’un logiciel ou d’une partie d’un code).
Après avoir été longtemps considéré comme une tâche de second plan, le test unitaire est devenu une pratique courante et même essentielle, faisant désormais partie intégrante du cycle de vie standard de développement.
Le test unitaire est un élément essentiel à tout code source pour s’assurer que l’application fonctionne comme prévu dans le cahier des charges malgré des évolutions éventuelles du code source. De plus, les bonnes pratiques de développement logiciel telles que le Test Driven Development (TDD) et le DevOps s’appuient énormément sur les tests unitaires.
Le rôle et les critères du test unitaire
Les tests unitaires sont développés pour confronter la version finale livrée à la spécification normalement fournie dans les premières phases d’un projet informatique. Ils permettent alors de statuer quant au succès ou à l’échec d’une vérification. Un test peut alors être compris comme un critère qui permettrait de valider les attendus d’un programme ou d’un code informatique.
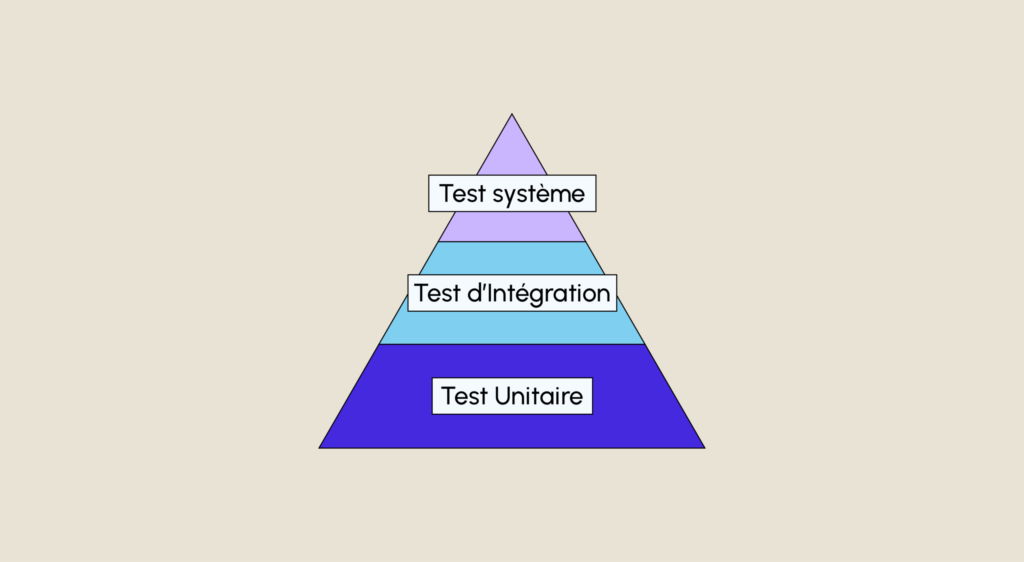
Mike Cohn, l’un des principaux contributeurs de la méthodologie Agile Scrum, positionne les tests unitaires à la base de sa Pyramide des tests (dans laquelle les niveaux suivants correspondent aux tests de services et d’interfaces).
Le test unitaire permet ainsi entre autres :
- D’identifier rapidement des erreurs :
Plusieurs méthodes (avec entre autres la méthode eXtreme Programming) préconisent d’écrire les test en même temps voire avant la fonction à tester pour faciliter le débogage
- De faciliter la maintenance :
Après la modification d’un code, les tests permettent de rapidement identifier les éventuelles régressions (tests échoués)
- De compléter la documentation du code :
Les tests permettent souvent de mieux mettre en évidence l’utilisation d’une fonction. Ils permettent ainsi de compléter la documentation des fonctionnalités.
Plusieurs critères doivent être réunis pour pouvoir bien définir un test unitaire :
- Unité : Le test unitaire se concentre sur le plus petit élément identifiable d’une application (on parle d’unité). Cependant, plusieurs éléments ou lignes de code peuvent servir à définir une unité qui peut alors être une fonction, une méthode de classe, un module, un objet, etc. C’est la raison pour laquelle les tests unitaires sont appelés des tests de bas niveau (à l’inverse des tests dits de haut niveau vérifiant la validité d’une ou de plusieurs fonctionnalités plus complexes).
- Test en boîte blanche : Le test doit s’effectuer en boîte blanche pour évoquer le fait que l’ingénieur qualité souvent en charge du test ou le développeur lui même doit avoir une connaissance de la partie du code (de l’unité) à tester
- Isolation : Les tests doivent s’effectuer en isolation car chaque unité testée doit s’effectuer de manière indépendante des autres tests. La suite de tests unitaires doit pouvoir être lancée dans n’importe quel ordre sans affecter le résultat des tests suivants ou précédents.
- Rapidité : les différents tests doivent pouvoir s’exécuter rapidement pour permettre de les lancer à chaque modification du code source
- Idempotence : l’idempotence signifie qu’une opération a le même effet à chaque fois qu’on l’applique. Le test doit donc être indépendant de l’environnement ou du nombre de fois qu’il est exécuté.
- Automatisé : Le test unitaire doit pouvoir produire directement un résultat en termes de succès ou d’échec et ne pas nécessiter d’intervention manuelle du développeur pour conclure.
Pour résumer on peut donc dire que la valeur réelle du test s’apprécie lors d’importants changements dans le code source d’une application ou d’un système. Les tests permettent alors de s’assurer que le comportement attendu est maintenu. Le test unitaire contribue donc à réduire le niveau d’incertitude.
Si les méthodologies et les frameworks de test sont désormais bien ancrés en développement logiciel, comment et où s’insère le test unitaire en data science ?
Les tests en Machine learning
En développement logiciel traditionnel, l’élément clé qui influence le comportement du système est le code source. Les technologies de Machine Learning ont introduit 2 nouveaux éléments qui impactent directement également le comportement du système. Il s’agit du modèle utilisé et des données. Par ailleurs, le comportement des modèles de Machine Learning ne sont pas spécifiquement définis par des lignes de code mais majoritairement par les données utilisées en phase d’entraînement. C’est la raison pour laquelle, les systèmes se basant sur les technologies de Machine Learning, nécessitent des tests supplémentaires à cause du fait que les règles gouvernant le comportement du système global sont moins explicites que les règles des systèmes traditionnels.
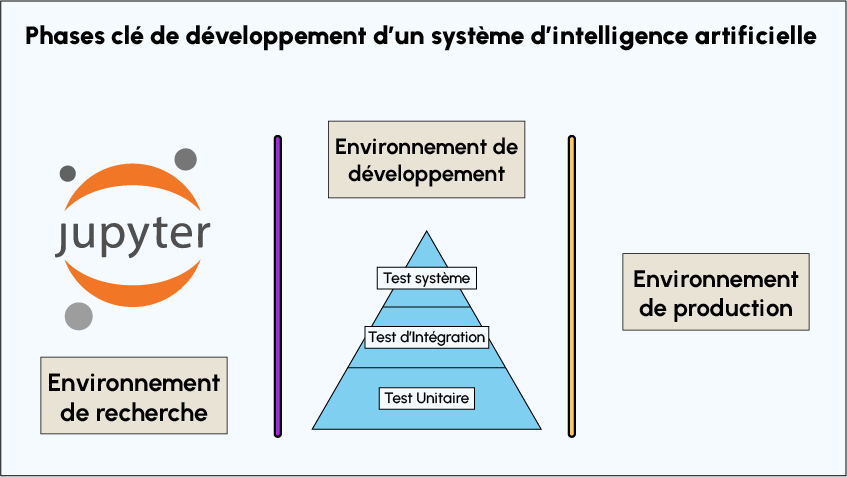
Les boucles de travaux en Machine Learning s’effectuent très souvent à cheval sur 3 environnements :
- L’environnement de recherche et développement :
Il s’agit le plus de souvent du Jupyter Notebook utilisé pour développer les différents modèles et les différentes approches. Cependant, s’il est techniquement possible de construire et de réaliser des tests unitaire sur des fonctionnalités des bases (d’une classe par exemple en Python), la plupart des tests unitaires sont généralement réalisés dans les environnements de développement et de production.
- L’environnement de développement :
C’est dans ce dernier environnement que la plupart des tests vont être réalisés. On distingue généralement dans cet environnement plusieurs niveaux de tests :
- Les tests unitaires qui constituent la base (comme illustré sur le graphique ci-dessous)
- Les test d’intégration pour s’assurer du fonctionnement optimal de différents composants
- Les test systèmes pour s’assurer du fonctionnement global du système d’ensemble
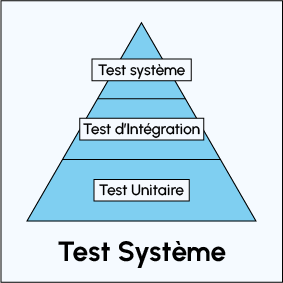
La question se pose alors de savoir où positionner le curseur de définition du nombre de tests. Pour définir le nombre optimal de test, on peut se servir des questions suivantes :
- Est-ce que la base de tests permet de réduire l’incertitude sur le fonctionnement de notre système ?
- Quelles sont les missions critiques et principales de notre système ?
- Les priorités sont-elles clairement identifiées ?
En ce qui concerne les problématiques de machines learning, des exemples de tests unitaires qu’il est possible de réaliser sont donnés ci-dessous :
- Test du format et du type de données
- Test des paramètres du modèle de Machine Learning
- Test sur les variables d’entrée
- Test sur la qualité des modèles
- L’environnement de production :
Il s’agit de l’environnement dans lequel les utilisateurs d’une application vont avoir accès à cette dernière. Dans cet environnement, les tests réalisés permettant de s’assurer du bon fonctionnement global du système sont généralement beaucoup plus complexes.
Les librairies de test en Python
En langage Python les deux principales librairies utilisées pour réaliser des tests unitaires sont Unittest et Pytest. L’utilisation de la librairie unittest pour la réalisation de tests nécessite une bonne connaissance de la programmation orientée objet de Python ceci à cause du fait que les test sont réalisés par l’intermédiaire d’une classe.
À contrario, l’utilisation de la librairie Pytest offre un peu plus de flexibilité dans le design et la réalisation de tests. En plus du fait que la réalisation de test avec la librairie Pytest est beaucoup plus flexible, cette dernière librairie offre davantage de commandes et options de test (assert instruction).
Pour illustrer des cas d’utilisations simples de ces deux librairies nous allons considérer les deux exemples suivants:
- Test d’une fonction calculant le carré d’un entier : Nous testerons que les valeurs données en sortie sont des entiers (test réalisés avec Pytest)
- Test du type et des intervalles des données d’entrée (avec unittest)
Très loin d’être exhaustif, ces deux exemples permettront de mieux se rendre compte de quelques possibilités d’utilisation de ces librairies.
Exemple de test avec Pytest
Supposons par exemple que dans le cadre d’un projet des développeurs ont créé une fonction pour calculer le carré d’un nombre entier et que l’on souhaite réaliser des tests pour s’assurer que les sorties de la fonction sont des nombres entiers. On décide alors de réaliser des tests sur une liste de valeurs.
Etape 1 : Définition de la fonction number_squared dans le fichier function.py
Etape 2 : Définition de la fonction de test dans le fichier test_in_int.py
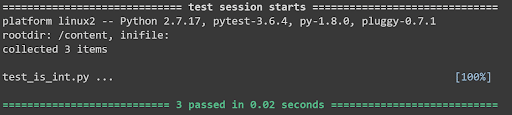
L’exécution de la commande pytest dans un terminal renvoie le résultat suivant :
La seule contrainte imposée avec l’utilisation de la librairie Pytest est d’avoir le nom du fichier de test commençant par le préfixe ‘test_’ (le nom complet serait test_nom_du_fichier.py). Ainsi, à chaque modification \ mise à jour de la fonction on pourra utiliser la fonction de test pour s’assurer que le comportement attendu de la fonction reste cohérent.
Exemple de test avec unittest
Dans cet exemple on va utiliser la librairie unittest pour réaliser un test avec un jeu de données exemple. On va utiliser le jeu de données iris (cliquer ici pour plus de détails). Le test que l’on se propose d’implémenter est de vérifier le type et l’étendue des données d’entrée d’un modèle de Machine Learning.
Imaginons par exemple, que le Data Scientist d’une équipe ait développé un modèle permettant de classer les trois espèces de fleurs. Cependant, les données (précisément les variables de notre jeu de données) utilisées pour développer le modèle respectaient un certain type et s’étendaient sur un certain intervalle.
Si d’aventure, les informations fournies par des utilisateurs de notre modèle étaient très différentes des données d’entraînement (on parle en anglais de data drift), le modèle de Machine Learning mis en production pourrait ne plus être pertinent et fournir des prédictions incohérentes. C’est la raison pour laquelle il est nécessaire pendant la phase de développement de définir un test pour s’assurer de la cohérence des données d’entrée par rapport aux données d’entraînement.
Avec l’aperçu et la description du jeu de données ci-dessous, on peut voir que les variables sont de type flottant (des nombres réels) avec des valeurs en général comprises entre 1 et 8.
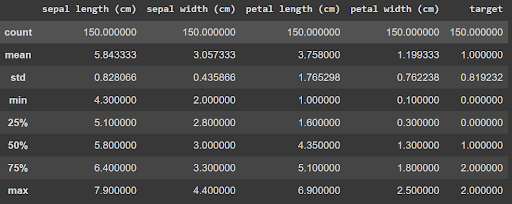
Etape 1 : Définition d’un dictionnaire des types et des intervalles des variables
Dans une structure de dictionnaire, on va définir pour chacune des variables à la fois le type et l’intervalle de chaque variable en cohérence avec la description du jeu de données ci-dessus (Analogie avec le domaine de définition en mathématique).
Etape 2 : Création d’un pipeline de traitement des données et d'entraînement d’un modèle de régression logistique
Cette étape peut être décomposée en plusieurs phases mais nous avons regroupé toutes les phases dans une seule classe.
Etape 3 : Définition de la class de test pour notre campagne de test
Avec la librairie unittest, il est nécessaire de définir un classe de test :
Etape 4 : Exécution des tests
Pour exécuter le test à l’intérieur d’un Jupyter Notebook il suffit alors d’utiliser le code ci-dessous :
L’exécution du code nous donne l’affichage suivant :

Conclusion
La réalisation de tests unitaires est une étape incontournable pour diminuer le niveau d’incertitude et garantir une certaine cohérence entre le spécification d’entrée et le produit final. On comprend alors mieux la place que cette étape occupe dans les méthodes agiles. Dans le processus de développement des applications de Machine Learning, les tests unitaires sont le plus souvent réalisés en phase de développement par un Data Scientist ou un Data Engineer pour garantir les performances du système et s’assurer de la cohérence des résultats obtenus par rapport aux données d’entrée.
Si le métier de Data Engineer vous intéresse, découvrez le parcours pensé par DataScientest sur la page dédiée.









