
L'exploration de données est un pilier essentiel de toute analyse de données significative. La qualité des outils utilisés dans cette phase initiale peut grandement influencer la réussite du projet.
Sweetviz est une bibliothèque Python open source qui génère de magnifiques visualisations de haute densité pour lancer l’Analyse Exploratoire des Données (EDA) avec seulement deux lignes de code. La sortie est une application HTML entièrement autonome.
Le système est conçu pour visualiser rapidement les valeurs cibles et comparer les ensembles de données. Son objectif est de faciliter l’analyse rapide des caractéristiques cibles, des données d’entraînement par rapport aux données de test, et d’autres tâches de caractérisation des données similaires.
Installation de Sweetviz et principales fonctions
Commençons par l’aspect pratique : l’installation de Sweetviz. Cette opération est rapide et simple grâce au gestionnaire de packages pip de Python. Ouvrez votre terminal ou invite de commande et exécutez la commande suivante :
```pip install sweetviz```Avec l’installation complète, vous serez prêt à explorer vos données avec la puissance visuelle de Sweetviz. La création d’un rapport avec Sweetviz est un processus rapide en deux étapes :
- Créez un objet DataframeReport à l’aide de l’une des fonctions suivantes : analyze(), compare() ou compare_intra().
- Utilisez une fonction show_xxx() pour afficher le rapport. Vous pouvez désormais choisir entre les options de rapport HTML ou notebook.
Les fonctions suivantes permettent de proposer facilement et rapidement des analyses visuelles poussées grâce à Sweetviz :
analyze() : La fonction analyze() est le cœur de Sweetviz. Elle permet de générer un rapport complet sur un ensemble de données. Lors de son exécution, cela générera une application HTML en 1080p en plein écran dans votre navigateur par défaut
```import sweetviz as sv
report = sv.analyze(df)
report.show_html('report.html')```
Cette fonction produit un rapport HTML détaillé comprenant des statistiques descriptives, des visualisations et des comparaisons entre les différentes colonnes.
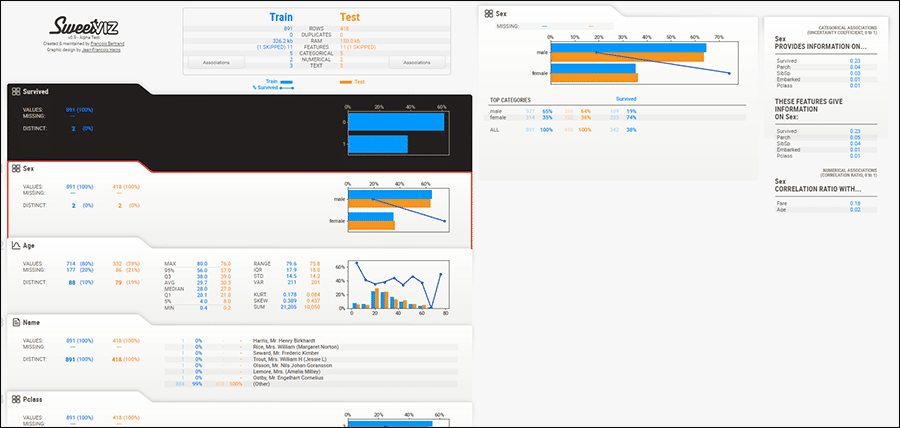
compare() : Particulièrement utile pour comparer deux ensembles de données, que ce soit pour évaluer un ensemble d’entraînement par rapport à un ensemble de test ou pour comparer deux ensembles distincts.
```compare_report = sv.compare([df, 'Entraînement'], [df_test, 'Test'])
compare_report.show_html('compare_report.html')```
Vous aurez alors un rapport de comparaison, mettant en évidence les différences et similitudes entre les deux ensembles de données :

analyze_feature() : Pour obtenir une analyse approfondie d’une fonction spécifique
« `feature_report = sv.analyze_feature(df, ‘Revenu’)
feature_report.show_html(‘feature_report.html’)« `
Vous produirez ici un rapport détaillé pour la fonction spécifiée, fournissant des informations approfondies sur sa distribution et son comportement.
compare_intra() : Permet de comparer plusieurs ensembles de données similaires
« `intra_compare_report = sv.compare_intra(df_grouped, groupby=’Catégorie’)
intra_compare_report.show_html(‘intra_compare_report.html’)« `
Cette fonction génère un rapport de comparaison intragroupe, soulignant les différences significatives entre les sous-groupes.
En intégrant ces fonctions dans votre flux de travail, vous exploitez pleinement le potentiel de Sweetviz pour explorer, comprendre et comparer vos données.
Utilité approfondie de Sweetviz
L’utilisation de la fonction analyze() fournit un aperçu global des données, compare() vous permet d’évaluer les différences entre des ensembles distincts. La fonction analyze_feature() offre des informations ciblées et compare_intra() simplifie la comparaison entre différents groupes au sein de votre ensemble de données.
Pourquoi utiliser Sweetviz ?
Vous connaissez probablement les bibliothèques Matplotlib, Seaborn ou encore Plotly. Comment Sweetviz se différencie des autres bibliothèques d’exploration de données?
Sweetviz vs Pandas Profiling : Sweetviz se distingue par sa simplicité d’utilisation et ses rapports visuels intuitifs, offrant une analyse détaillée avec une seule ligne de code. On le préfère pour sa facilité d’intégration et ses rapports visuels rapides.
Sweetviz vs Matplotlib/Seaborn : Sweetviz simplifie l’exploration de données en générant automatiquement des rapports visuels complets avec une seule ligne de code. Matplotlib et Seaborn nécessitent souvent une écriture manuelle de code pour chaque visualisation. L’automatisation de Sweetviz permet d’accélérer le processus d’analyse exploratoire, tandis que Matplotlib et Seaborn demandent souvent plus d’efforts pour obtenir des résultats similaires.
Sweetviz vs Plotly : Bien que Plotly soit idéal pour les graphiques interactifs, Sweetviz se distingue par sa simplicité d’utilisation. Sweetviz offre une visualisation similaire sans nécessiter une configuration manuelle complexe.

En conclusion, Sweetviz offre une multitude de fonctions puissantes pour l’analyse exploratoire des données. En intégrant ces fonctionnalités dans votre flux de travail, vous pouvez exploiter pleinement la richesse de vos données. Que ce soit pour générer des rapports détaillés, comparer des ensembles de données, ou analyser spécifiquement des fonctionnalités, Sweetviz se démarque comme un compagnon précieux dans votre boîte à outils d’analyse de données.









