
Avant de mettre un modèle de Machine Learning en production, il faut avant tout déterminer le modèle le plus adapté, sélectionner les paramètres optimaux etc… Ce sont des opérations redondantes qui vont s’appliquer à différents projets. Ne serait-il pas plus simple d’automatiser ces processus? C’est là qu’intervient TPOT.
Qu’est-ce que TPOT ?
TPOT est une librairie open source utilisée pour l’automatisation de Machine Learning. Basée sur la librairie Scikit-learn utilisant la programmation génétique, TPOT explore des milliers de pipelines différents et trouve celui qui sera le plus adapté pour un dataset donné.
Imaginons que vous disposez d’un jeu de données, pour lequel l’application d’un modèle de Machine Learning est pertinent. Vos premières étapes vont se concentrer autour de l’exploration des données et leur préparation.
L’étape suivante consiste à sélectionner le meilleur modèle de Machine Learning en adaptant vos données sur différents modèles et en recherchant le meilleur ensemble d’hyperparamètres.
Techniquement, vous allez faire appel aux mêmes librairies, sur différents projets. Ce qui va vous prendre beaucoup de temps et ne vous fera pas forcément gagner en compétence, puisque vous écrivez encore et encore le même code.
Pourquoi utiliser TPOT ?
Les outils de Machine Learning automatique (AutoML) permettent de répondre à une problématique simple : comment rendre la création et l’entraînement de modèle moins chronophage?
L’AutoML permet, comme son nom l’indique, d’automatiser une grande partie du processus de création d’un modèle sans perte de qualité, ce qui permet au Data Scientist de se concentrer sur l’analyse. Son pipeline est composé de plusieurs processus qui vont permettre de construire un modèle de Machine Learning performant (feature engineering, génération du modèle, optimisation des hyperparamètres).
Pour rappel, en Machine Learning, un pipeline codifie et automatise le workflow permettant à la donnée d’être transformée et corrélée dans un modèle que l’on peut ensuite analyser. Le chargement des données dans le modèle est alors entièrement automatisé.
On peut également se servir d’un pipeline pour séparer le workflow de notre modèle en différentes parties indépendantes et réutilisables, ce qui permet d’en simplifier la création et d’éviter la répétition des tâches.
Un bon pipeline va permettre de rendre la construction et la production de modèles de Machine Learning plus efficaces et scalables (évolutifs).
De plus, TPOT dispose d’une grande flexibilité puisque vous pouvez l’adapter aux modèles de réseaux neuronaux avec PyTorch. TPOT supporte notamment l’utilisation de Dask pour réaliser des entraînements en parallèle.
Comment fonctionne TPOT ?
TPOT, ou Tree-based Pipeline Optimization, utilise une structure basée sur les arbres de décisions binaires pour représenter un modèle de pipeline. Ce qui inclut la préparation de données, la modélisation des algorithmes, les réglages des hyperparamètres et la sélection du modèle.
Ci-dessous un exemple de pipeline indiquant les éléments automatisés par TPOT :
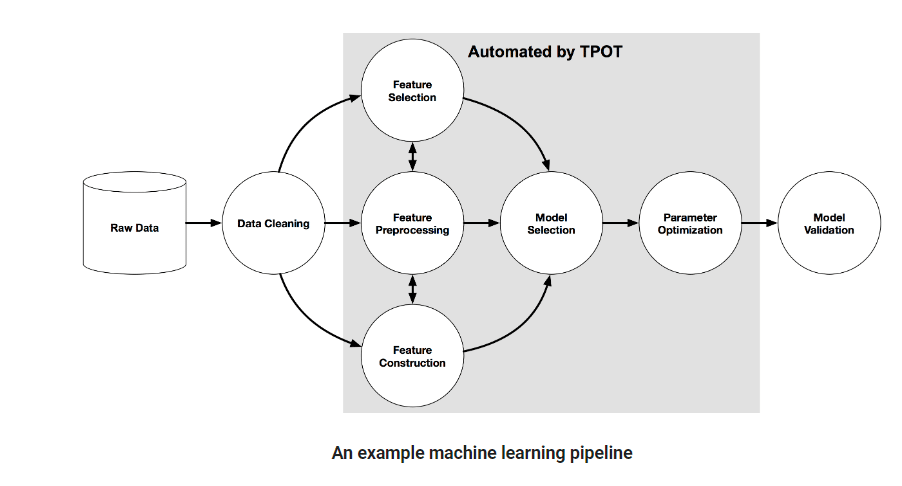
En combinant les algorithmes de recherche stochastique, comme la programmation génétique, et une représentation flexible d’expression trees, TPOT va automatiquement designer et optimiser les features (fonctionnalités), le modèle de Machine Learning, et les hyperparamètres. Le but sera de maximiser l’accuracy de la classification supervisée sur notre jeu de données.
Il est important de noter que pour trouver le pipeline le plus optimisé il faudra laisser TPOT travailler pendant un certain temps. Vous pouvez évidemment le laisser tourner quelques minutes mais ce ne sera pas suffisant pour trouver le meilleur modèle à utiliser pour votre jeu de données.
En fonction de la taille de votre dataset, TPOT peut prendre plusieurs heures, voire plusieurs jours, pour s’exécuter. Il est recommandé de faire tourner plusieurs instances en même temps pendant plusieurs heures pour une recherche poussée et efficace.
Comme l’algorithme d’optimisation de TPOT est de nature stochastique, ce qui signifie une randomisation partielle, il est possible que pour deux exécutions recommandent des pipelines différents pour un même jeu de données. Si c’est le cas, soit les pipelines ne correspondront pas à cause d’un manque de temps d’exécution, soit ils auront des scores de performances très proches.
Trouver le meilleur pipeline avec TPOT
Maintenant que l’on comprend ce qu’est TPOT et son intérêt, nous allons voir comment le mettre en place et s’en servir. Pour rappel, TPOT se base sur scikit-learn ce qui rend son code familier si vous avez déjà utilisé cette librairie.
- Commencez par importer les modules TPOT et les autres modules dont vous avez besoin pour définir votre modèle : ‘pip install tpot’.
- Pendant l’étape de transformation de données il faudra impérativement renommer la variable cible et lui donner le nom ‘class’.
- TPOT ne prend en compte que les données au format numérique, il sera nécessaire d’appliquer les transformations nécessaires aux variables explicatives.
- Après avoir séparé votre jeu de données en un jeu d’entraînement et un jeu de test, vous pouvez définir votre Classifier TPOT et ses paramètres.
- Pour appliquer TPOT à votre jeu de données il suffit d’utiliser la méthode .fit()
- Une fois que le calcul est terminé vous verrez apparaître en output le meilleur pipeline pour votre jeu de données. Vous pourrez ensuite utiliser la méthode .score() pour mesurer la performance du modèle que TPOT aura choisi.
Ci-dessous, vous trouverez un exemple pour créer un pipeline en utilisant TPOT :
# Pour la classification
from tpot import TPOTClassifier
# Pour la régression
from tpot import TPOTRegressor
from sklearn.model_selection import train_test_split
# Paramétrage du TPOTClassifier
tpot_classification = TPOTClassifier(verbosity=2, max_time_mins=2, max_eval_time_mins=0.04, population_size=40)
# Paramétrage du TPOTRegressor
tpot_regression = TPOTRegressor(generations=5, population_size=50, scoring=’neg_mean_absolute_error’, cv=cv, verbosity=2, random_state=1, n_jobs=-1)
# Application de TPOT à notre jeu de données train
tpot_classification.fit(X_train, y_train)
tpot_regression.fit(X_train, y_train)
# Calcul du taux de bonnes prédictions
tpot.score(X_test,y_test)
# Extraction du code généré par TPOT pour modifier le pipeline créé
tpot.export(‘tpot_titanic_pipeline.py’)
Conclusion
TPOT est un outil très utile pour trouver un premier modèle optimisé. Il faudra certainement retravailler le pipeline obtenu avant de l’envoyer en production. Cependant, pour obtenir de premiers résultats, cet outil est plus que suffisant et vous fera gagner un temps considérable.








