Lorsque l’apprentissage d’un modèle singulier peine à livrer de bonnes prédictions, les méthodes d’apprentissage d’ensemble apparaissent souvent comme une solution de choix. Les techniques d’ensemble les plus connues, le Bagging (Bootstrap Aggregating) et le Boosting, ont toutes toutes deux comme objectif d’améliorer la précision des prédictions faites lors de l’apprentissage automatique en combinant les résultats de modèles individuels, afin d’en extraire des prédictions finales plus robustes et précises.
Bagging : La Puissance de l'Apprentissage Parallèle
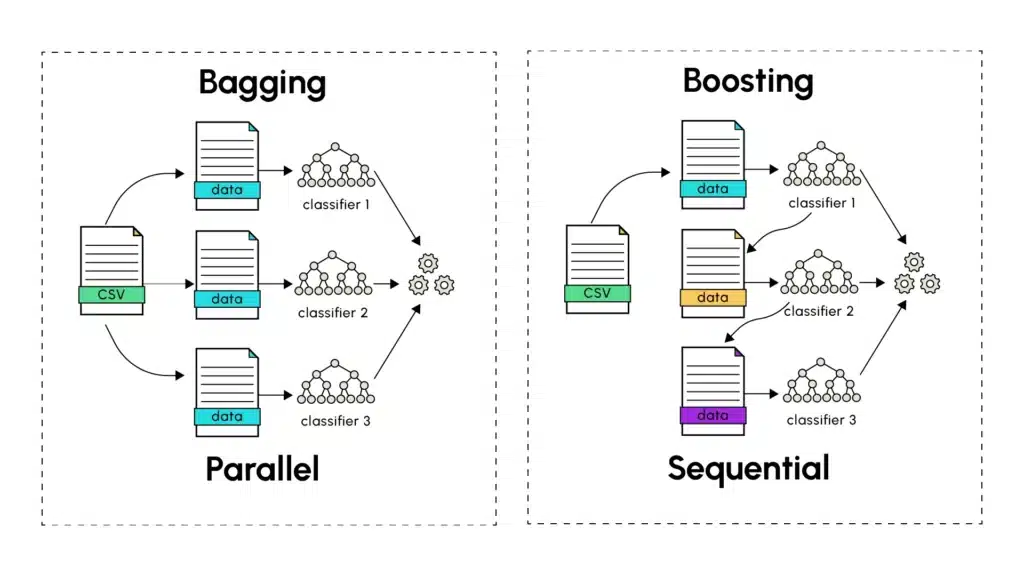
Le Bagging, introduit par Leo Breiman en 1994, se base sur l’entraînement de plusieurs versions d’un prédicteur tel qu’un arbre de décision, entraîné en parallèle de manière indépendante. La première étape du bagging consiste à effectuer un tirage d’échantillons aléatoires avec remise (appelé le bootstrapping) à partir de l’ensemble des données d’entraînement. Chaque prédicteur se voit être assigné un échantillon d’entraînement sur lequel il émet des prédictions. Ces dernières sont ensuite combinées avec celles de tous les autres prédicteurs distincts. Cette dernière étape passe par le calcul de la moyenne des prédictions faites par les différents modèles (pour les prédictions quantitatives) ou par une méthode de vote (pour les prédictions catégorielles), où la prédiction majoritaire en termes de nombre d’occurrence ou de probabilité est retenue.
La force principale du bagging réside dans sa capacité à réduire la variance sans augmenter le biais. En entraînant des modèles sur différents sous-ensembles ayant un certain pourcentage de données en commun, chaque modèle capture la diversité présente dans les jeux de données aléatoires, tout en obtenant des résultats finaux généralisant bien sur le jeu de données test. Une analogie avec le monde réel est la suivante : demandez l’avis de plusieurs experts sur un problème complexe. Chaque expert, bien que compétent, peut avoir des expériences et des perspectives légèrement différentes. Moyenner leurs opinions conduit souvent à de meilleures décisions que de se fier à un seul expert.
En somme, l’agrégation de plusieurs modèles à forte variance est utilisée afin de capturer au mieux les variations présentes dans chaque jeu d’entraînement. Cette approche permet donc de lisser les erreurs de prédictions individuelles émises par les différents modèles, afin de construire un modèle global à faible variance en combinant les prédictions de plusieurs modèles à hautes variances (overfitting). Le Bagging a notamment été popularisé à travers les Random Forests (forêts aléatoires) qui sont le résultat de l’entraînement parallèle d’arbres de décisions, un type de modèle connu pour sa forte variance.
Boosting : Apprentissage Séquentiel pour la Réduction des Erreurs
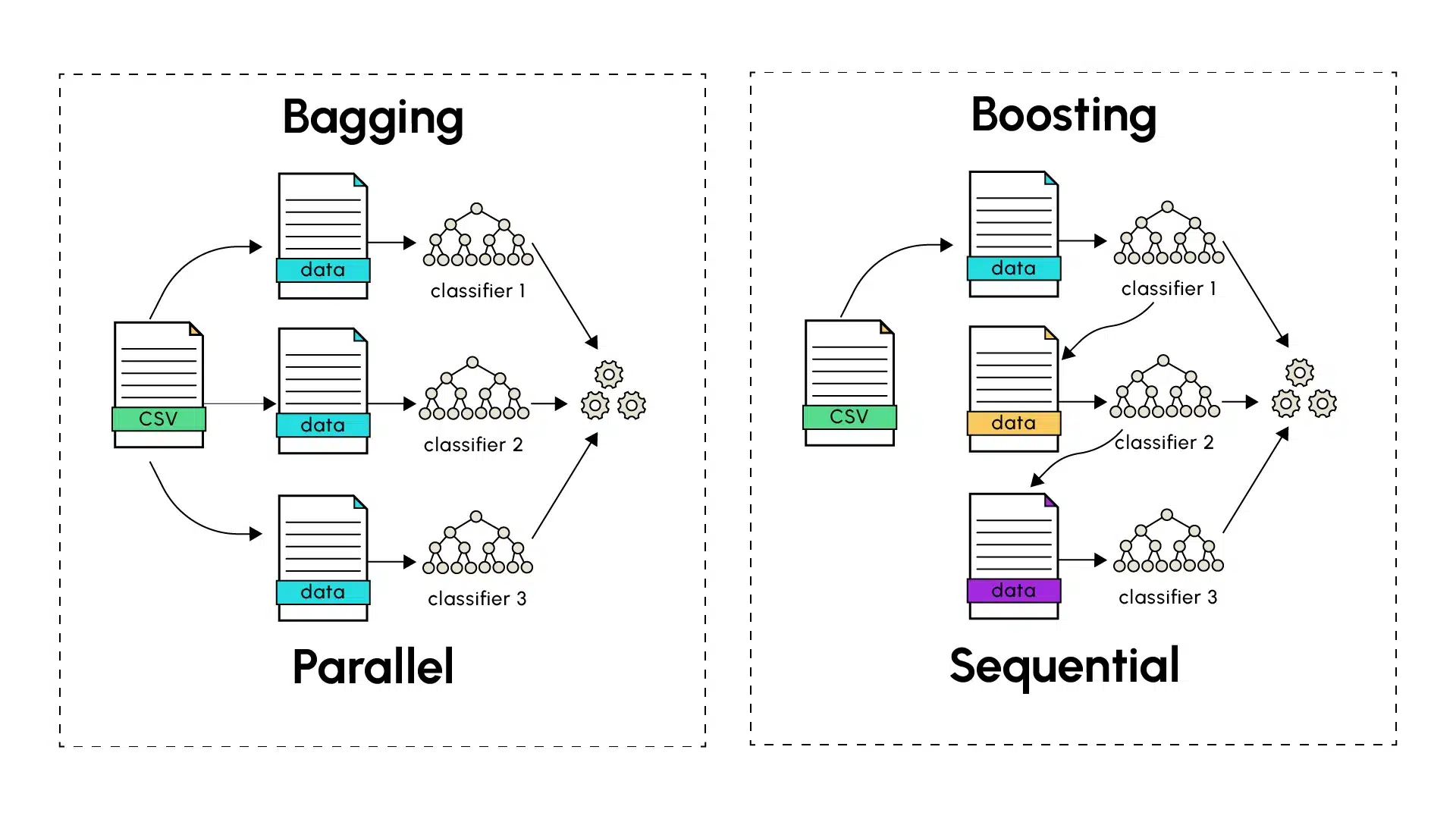
Contrairement au Bagging, le boosting suit une méthode séquentielle dans la construction du modèle final. Les prédicteurs individuels sont dits faibles (underfitting) et sont construits en série, l’un à la suite de l’autre. De ce fait, chaque modèle vise à corriger les erreurs de celui qui le précède dans le but de diminuer le biais introduit par chaque modèle faible. Les algorithmes de boosting incluent notamment AdaBoost (Adaptive Boosting), le Gradient Boosting et ses variantes XGBoost, LightGBM.

Le processus commence par un apprenant faible effectuant des prédictions sur le jeu de données d’entraînement. Les instances mal prédites sont alors identifiées par l’algorithme de Boosting qui leur assigne des poids plus élevés. Le modèle suivant se concentre plus sur ces cas précédemment difficiles à identifier lors de son entraînement afin de rendre ses prédictions plus robustes. Le processus continue et chaque modèle subséquent vise à corriger les erreurs des apprenants faibles précédents, jusqu’à ce que le dernier modèle de la série soit entraîné. Tout comme pour le Bagging, le nombre de modèles à entraîner pour contribuer aux prédictions finales peut être déterminé empiriquement en tenant compte de la complexité, du temps d’entraînement et de la précision des prédictions finales.
Le Gradient Boosting pousse le concept de Boosting plus loin en utilisant une approche basée sur la minimisation des gradients pour ajuster les prédictions. Chaque nouveau modèle est entraîné pour corriger les résidus des prédictions précédentes en suivant la direction du gradient de la fonction de perte, ce qui permet une optimisation plus précise et efficace.
Différences Clés et Compromis
1. Approche d'Entraînement :
- Bagging : Les modèles sont entraînés indépendamment et en parallèle.
- Boosting : Les modèles sont entraînés séquentiellement, chacun apprenant des erreurs précédentes.
2. Gestion des Erreurs :
- Bagging : Réduit la variance par moyenne.
- Boosting : Réduit à la fois le biais et la variance par apprentissage séquentiel.

3. Risque de Surapprentissage :
- Bagging : Généralement plus résistant au surapprentissage.
- Boosting : Plus sensible au surapprentissage, particulièrement lorsque celui-ci cherche à classer correctement des données bruitées.
4. Vitesse d'Entraînement :
- Bagging : Plus rapide, car les modèles peuvent être entraînés en parallèle.
- Boosting : Plus lent, en raison de sa nature séquentielle.
Applications Pratiques
Les deux techniques excellent dans différents scénarios. Le Bagging performe souvent bien quand :
- Les modèles de base sont complexes (haute variance).
- Le jeu de données contient beaucoup de bruit.
- Des capacités de traitement parallèle sont disponibles.
- L’interprétabilité est importante.
Le Boosting brille typiquement quand :
- Les modèles de base sont simples (haut biais).
- Les données sont relativement peu bruitées.
- Atteindre une précision maximale de prédiction est crucial.
- Les ressources informatiques permettent un traitement séquentiel.

Considérations pour l'Implémentation
Lors de l’implémentation de ces techniques, plusieurs facteurs méritent attention :
- Taille du Dataset : Les grands jeux de données bénéficient généralement plus du bagging
- Ressources Computationnelles : Le bagging peut exploiter le traitement parallèle
- Réglage des Paramètres : Le boosting nécessite généralement un réglage plus minutieux
- Interprétabilité : Les modèles baggés tendent à être plus interprétables
Conclusion
Le bagging et le boosting sont maintenant des techniques fondamentales en apprentissage automatique. Alors que le bagging offre robustesse et simplicité par apprentissage parallèle, le boosting fournit de puissantes capacités d’amélioration séquentielle. Comprendre leurs forces et faiblesses respectives permet aux praticiens de choisir l’approche appropriée à leur cas d’utilisation spécifique.








