
La 16 mars dernier, dans le cadre de son webinar hebdomadaire, DataScientest a eu le plaisir d’accueillir des experts data de l’entreprise namR. Respectivement Data Analyst et Lead Computer Vision Engineer, Marc Stéfanon et Sylvain Gavoille ont expliqué à notre communauté comment l’Intelligence artificielle et l’Open Data peuvent participer à la rénovation énergétique des bâtiments. Dans cet article, nous allons reprendre l’ensemble de leur présentation.
I. Présentation de namR
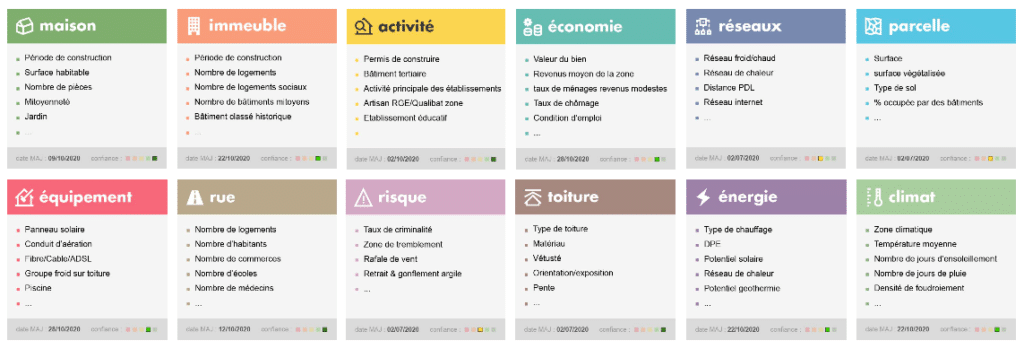
Créée en 2017, namR enrichit, produit et fournit des données géolocalisées hautement actionnables. Ces données couvrent l’ensemble du territoire français et représentent 34 millions de bâtiments sur lesquels namR est en mesure de donner 200 caractéristiques différentes permettant notamment d’accélérer la transition écologique et d’enrichir la connaissance des territoires. L’entreprise compte aujourd’hui 40 personnes et réalise un chiffre d’affaires annuel de 5,3 millions d’euros.
NamR récolte des données provenant de ses partenaires et de l’Open data, c’est-à-dire des données dont l’accès est public et libre de droit. Ces données sont fortement lacunaires, non structurées et de plusieurs types (images, textes, cartes, etc.). L’activité de namR consiste à nettoyer ces données et les enrichir grâce au Machine Learning, des algorithmes géospaciaux et à des règles métier partagées par des partenaires spécialisés. L’activité est totalement compatible avec les règles fixées par le Règlement Général sur la Protection des Données (RGPD) puisqu’il utilise des données non personnelles.
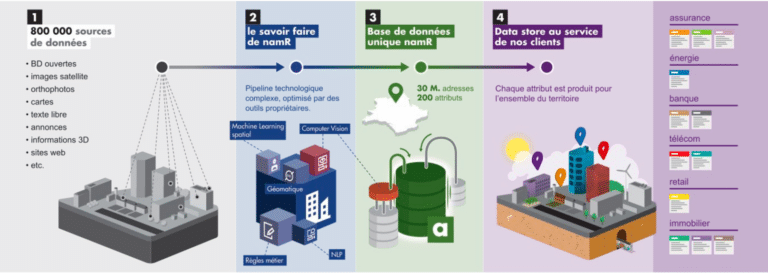
Ce traitement des données permet d’associer à chaque adresse une entité (parcelle, bâtiment, etc.) et à chaque entité des attributs (hauteur, surface vitrée, présence d’un jardin, d’une piscine, etc.).
Les clients de namR, selon leur activité, ont besoin d’information diverses sur les adresses de leurs clients ou sur leurs propres adresses pour les entreprises ou collectivités qui ont une multitude d’adresse (opérateurs téléphoniques, banques, etc.). Selon leurs besoins, namR leur fournit des assets pertinents et les intègre dans leurs outils comme tableau, toucan toco ou des plateformes cloud comme Azure, AWS ou Google Cloud.
Par exemple, pour une entreprise sur le marché de l’énergie, namR est en mesure de donner quel type de chauffages sont utilisés à chaque adresse ou de savoir où des panneaux solaires peuvent être installés. Les entreprises peuvent ainsi identifier les potentiels énergétiques des biens, cibler les adresses à haut potentiel et proposer des offres personnalisées.
II. Open Data: Cas d’utilisation des solutions namR
Marc Stéfanon et Sylvain Gavoille ont choisi de s’intéresser à la rénovation énergétique pour illustrer l’activité de namR. En effet, les données collectées et produites sur l’ensemble du territoire français permettent de mieux identifier les 7 millions de logements énergivores en France et intervenir efficacement pour atteindre les objectifs fixés par le gouvernement. : réduire de 40% les émissions de Gaz à effet de serre et la neutralité carbone d’ici 2050. La rénovation énergétique est un enjeu prioritaire puisque les logements les plus énergivores (ou passoires thermiques) seront interdits à la location à partir de 2023.
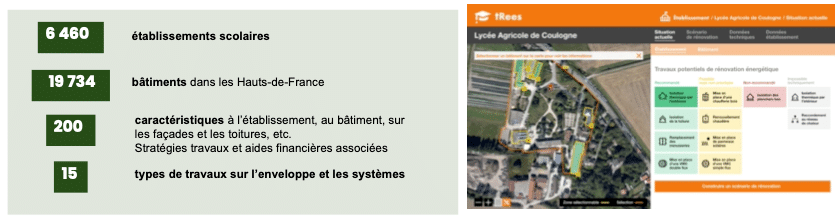
NamR a créé une plateforme tRees (transition de rénovation énergétique des bâtiments éducatifs et scolaires) pour permettre aux gestionnaires d’actifs d’avoir une meilleure connaissance de leur par cet identifier les bâtiments sur lesquels intervenir pour réduire leurs factures et leur empreinte carbone en réduisant leur consommation.
Pour proposer des données pertinentes à chaque adresse, namR se base sur l’open data. Cependant les informations collectées ne sont pas suffisantes pour répondre à l’ensemble des besoins des clients. C’est ainsi qu’intervient la massification des données : grâce à des algorithmes prédictifs (Machine Learning et Deep Learning) et à des règles métier, namR identifie les caractéristiques des bâtiments. Cette massification permet alors de trouver les types de toit utilisés à chaque adresse pour éventuellement proposer des panneaux photovoltaïques ou identifier les toits vétustes à rénover.
III. Les 5 étapes de la technologie namR
1. GeocodR
Cette étape consiste à trouver les coordonnées GPS des adresses. Les données d’entrées sont sous forme de texte et un programme appelé parseur, découpe le texte en segments logiques (numéro de rue, nom de la rue, coode postal, etc.) qui alimentent le geocodR qui donne à l’adresse un identifiant unique et des coordonnées (latitude et longitude).
2. Référentiels adresse et bâtiment
Le système s’appuie sur une base publique de l’institut national de l’information géographique et forestière (IGN). La base de données BDTOPO contient l’empreinte au sol des bâtiments et leur géométrie en 2D.
La base contient beaucoup d’informations de tout type qui nécessitent d’être nettoyées.
Dans cette étape, un lien est créé entre les adresses et les bâtiments. Ce lien est compliqué à réaliser, car une adresse peut être reliée à plusieurs bâtiments et un bâtiment à plusieurs adresses.
Dans un tiers des adresses, ces questions se posent et l’expertise de namR permet d’établir ce lien.
3. Attributs
Les données collectées viennent de plusieurs sources ainsi l’étape de normalisation et standardisation est cruciale pour pouvoir en tirer des informations correspondant à la réalité. La multiplicité des sources créent également une problématique : plusieurs sources donnent des informations contradictoires sur le même objet, un travail est donc nécessaire pour fournir une donnée cohérente aux algorithmes.
À partir des données d’entrée, les modèles de computer vision classifient et segmentent les adresses.
Différentes images sont traitées :
- des images aériennes d’une résolution de 20cm par pixel
- des images de façades
- des images satellites d’une résolution de 20m par pixel
- des images de Airbus (partenaire namR) ayant une bonne résolution
Algorithmes de Deep Learning sont appliqués sur ces images :
- Resnet50 pour la classification par exemple l’identification du type de toit
- UNET pour segmentation par exemple les pixels correspondant aux surfaces vitrées des façades pour calculer des perditions thermiques
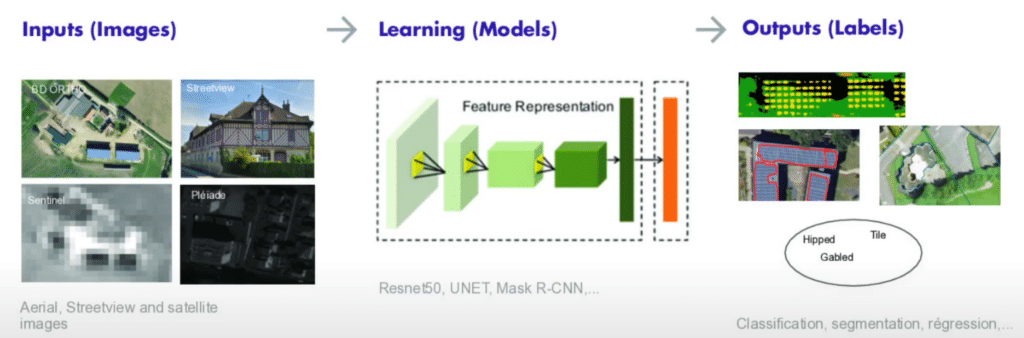
Sur l’exmple ci-dessus, on voit par exemple que les algorithmes ont identifié des panneaux solaires en rouge sur un bâtiment et des espaces végétalisés en vert.
En plus de la computer vision, namR fait appel à des algorithmes de natural language processing (NLP) pour analyser les plans locaux d’urbanisme (PLU) ou des permis de construire pour les lier à des adresses et des bâtiments et ainsi en déduire des données sur des adresses.

4. Évaluation des valeurs
Tout le processus de création des données décrit ci-dessus est standardisé et normalisé pour rendre traçables les données de sortie et évaluer la qualité des données produites. Chaque attribut est documenté que ce soit sur les sources ou sur les algorithmes utilisés pour l’obtenir. De plus, un indice de confiance de 1 à 5 a été mis en place, si une étape contient des incertitude, l’indice des datas qui en sont déduites baisse.
5. Architecture optimisée
namR possède une quarantaine de millions d’images sur la France entière, ce volume nécessite une infrastructure dédiée.
En effet, l’utilisation de Deep Learning en computer vision necessite l’utilisation de GPU (Graphics Processing Units) ou processeur graphique pour être performants et avoir des temps de calcul acceptables.
Pour supporter ces besoins, namR a créé une infrastructure Kubernetes pour contrôler les ressources mises à disposition pour les calculs et contrôler les coûts.
Conclusion
Depuis 2017, namR collecte des données géographiques provenant des sources publiques ou de ses partenaires. Après avoir relié toutes les données à des adresses, un lien est établi entre les adresses et les bâtiments. Enfin, namR est en mesure de fournir plus de 200 caractéristiques à ses clients sur leurs adresses et ainsi leur permettre de mieux cibler leurs consommateurs ou d’intervenir sur leurs locaux pour les entreprises ayant une multitude d’adresses. Tout ce process nécessite une expertise dans la reconnaissance d’images ou computer vision ainsi qu’en compréhension du langage (NLP).
DataScientest remercie vivement Marc Stéfanon et Sylvain Gavoille pour ce webinar qui nous a permis de découvrir une application des datas pour résoudre une problématique environnementale, en identifiant les bâtiments français les plus énergivores et ainsi intervenir en priorité pour réduire leur consommation et leurs émissions de gaz à effet de serre.







