Wenn das Lernen eines einzelnen Modells Schwierigkeiten hat, gute Vorhersagen zu liefern, erscheinen Ensemble-Learning-Methoden oft als die bevorzugte Lösung. Die bekanntesten Ensemble-Techniken, Bagging (Bootstrap Aggregating) und Boosting, haben beide das Ziel, die Genauigkeit von Vorhersagen im Machine Learning zu verbessern, indem sie die Ergebnisse einzelner Modelle kombinieren, um robustere und präzisere endgültige Vorhersagen zu extrahieren.
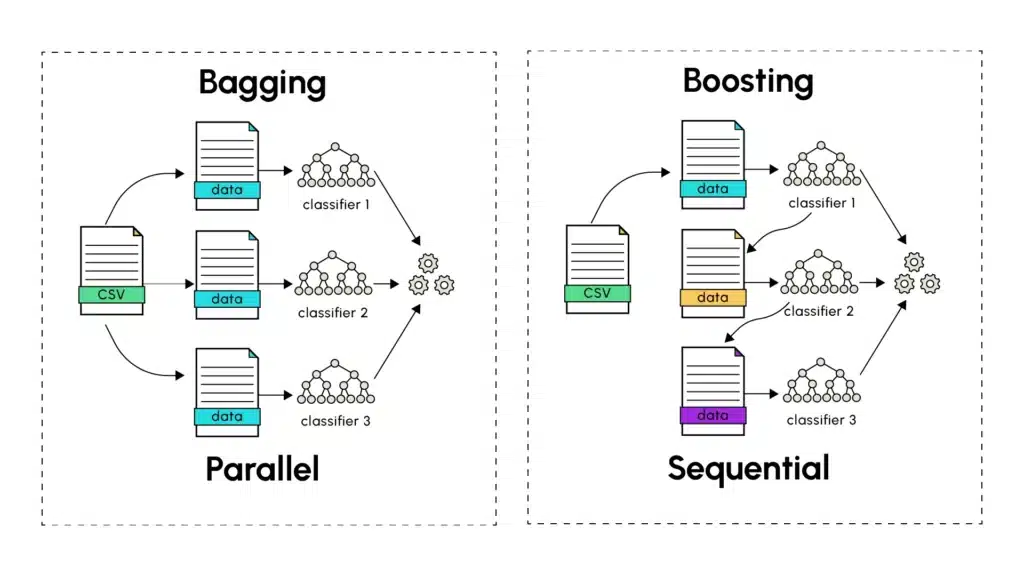
Bagging: Die Kraft des Parallelen Lernens
Das Bagging, eingeführt von Leo Breiman im Jahr 1994, basiert auf dem Training mehrerer Versionen eines Prädiktors wie eines Entscheidungsbaums, der auf parallele und unabhängige Weise trainiert wird. Der erste Schritt des Bagging besteht darin, eine zufällige Stichprobenziehung mit Zurücklegen (als Bootstrapping bezeichnet) aus dem gesamten Trainingsdatensatz durchzuführen. Jedem Prädiktor wird ein Trainingsstichproben zugewiesen, auf dem er Vorhersagen trifft. Diese werden dann mit denen aller anderen unterschiedlichen Prädiktoren kombiniert. Dieser letzte Schritt erfolgt durch die Berechnung des Durchschnitts der Vorhersagen, die von den verschiedenen Modellen gemacht wurden (für quantitative Vorhersagen) oder durch eine Abstimmungsmethode (für kategoriale Vorhersagen), bei der die Vorhersage mit der höchsten Anzahl an Vorkommen oder Wahrscheinlichkeit gewählt wird.
Die Hauptstärke des Bagging liegt in seiner Fähigkeit, die Varianz zu reduzieren, ohne die Verzerrung zu erhöhen. Durch das Training von Modellen auf verschiedenen Teilmengen mit einem bestimmten Prozentsatz gemeinsamer Daten erfasst jedes Modell die Diversität in den zufälligen Datensätzen und erzielt gleichzeitig finale Ergebnisse, die gut auf dem Testdatensatz generalisieren. Eine Analogie zur realen Welt ist folgende: Fragen Sie mehrere Experten nach ihrer Meinung zu einem komplexen Problem. Jeder Experte, obwohl kompetent, kann leicht unterschiedliche Erfahrungen und Perspektiven haben. Das Mittel der Meinungen führt oft zu besseren Entscheidungen als auf einen einzigen Experten zu vertrauen.
Zusammenfassend wird die Aggregation mehrerer Modelle mit hoher Varianz verwendet, um die in jedem Trainingsdatensatz vorhandenen Variationen bestmöglich aufzufangen. Dieser Ansatz ermöglicht es, die Fehler einzelner Vorhersagen der verschiedenen Modelle zu glätten, um ein globales Modell mit geringer Varianz zu konstruieren, indem die Vorhersagen mehrerer Modelle mit hoher Varianz (Overfitting) kombiniert werden. Das Bagging wurde insbesondere durch Random Forests (zufällige Wälder) populär gemacht, die das Ergebnis des parallelen Trainings von Entscheidungsbäumen sind, einer Modellart, die für ihre hohe Varianz bekannt ist.
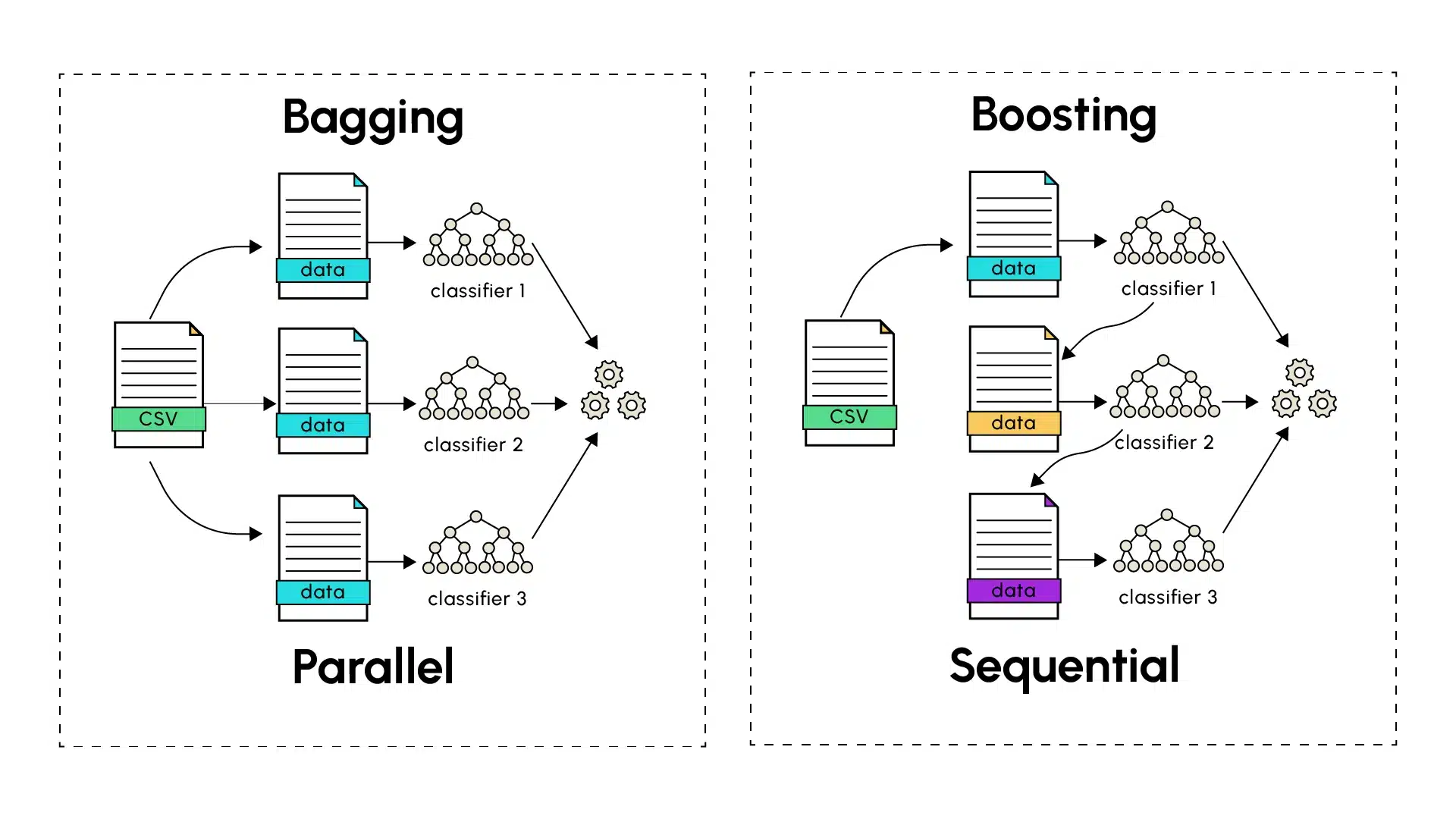
Boosting: Sequentielles Lernen zur Fehlerreduktion
Im Gegensatz zum Bagging folgt das Boosting einer sequentiellen Methode beim Aufbau des endgültigen Modells. Die einzelnen Prädiktoren werden als schwach (Underfitting) bezeichnet und in Reihe gebaut, einer nach dem anderen. Jedes Modell zielt darauf ab, die Fehler des vorherigen zu korrigieren, um die durch jedes schwache Modell eingeführte Verzerrung zu verringern. Die Boosting-Algorithmen umfassen insbesondere AdaBoost (Adaptive Boosting), das Gradient Boosting und seine Varianten XGBoost, LightGBM.

Der Prozess beginnt mit einem schwachen Lerner, der Vorhersagen auf dem Trainingsdatensatz macht. Die schlecht vorhergesagten Instanzen werden dann vom Boosting-Algorithmus identifiziert, der ihnen höhere Gewichte zuweist. Das folgende Modell konzentriert sich während seines Trainings mehr auf diese zuvor schwer zu identifizierenden Fälle, um seine Vorhersagen robuster zu machen. Der Prozess wird fortgesetzt, und jedes nachfolgende Modell zielt darauf ab, die Fehler der vorherigen schwachen Lerner zu korrigieren, bis das letzte Modell der Serie trainiert ist. Genau wie beim Bagging kann die Anzahl der Modelle, die für finale Vorhersagen trainiert werden, empirisch bestimmt werden, unter Berücksichtigung von Komplexität, Trainingszeit und Genauigkeit der finalen Vorhersagen.
Das Gradient Boosting treibt das Konzept des Boosting weiter, indem es einen auf der Minimierung von Gradienten basierenden Ansatz zur Anpassung von Vorhersagen verwendet. Jedes neue Modell wird trainiert, um die Reste der vorherigen Vorhersagen zu korrigieren, indem es der Richtung des Gradienten der Verlustfunktion folgt, was eine genauere und effizientere Optimierung ermöglicht.
Wichtige Unterschiede und Kompromisse
1. Trainingsansatz:
- Bagging: Die Modelle werden unabhängig und parallel trainiert.
- Boosting: Die Modelle werden sequentiell trainiert, jedes Modell lernt aus den Fehlern des vorherigen.
2. Fehlerbehandlung:
- Bagging: Reduziert die Varianz durch Mittelwertbildung.
- Boosting: Reduziert sowohl die Verzerrung als auch die Varianz durch sequentielles Lernen.

3. Risiko des Overfittings:
- Bagging: In der Regel widerstandsfähiger gegen Overfitting.
- Boosting: Empfänglicher für Overfitting, insbesondere wenn es versucht, verrauschte Daten korrekt zu klassifizieren.
4. Trainingsgeschwindigkeit:
- Bagging: Schneller, da die Modelle parallel trainiert werden können.
- Boosting: Langsamer aufgrund seiner sequentiellen Natur.
Praktische Anwendungen
Beide Techniken glänzen in unterschiedlichen Szenarien. Das Bagging performt oft gut, wenn:
- Basismodelle komplex sind (hohe Varianz).
- Der Datensatz viel Rauschen enthält.
- Parallele Verarbeitungsmöglichkeiten vorhanden sind.
- Interpretierbarkeit wichtig ist.
Das Boosting brilliert typischerweise, wenn:
- Basismodelle einfach sind (hohe Verzerrung).
- Die Daten relativ wenig verrauscht sind.
- Die höchstmögliche Vorhersagegenauigkeit entscheidend ist.
- Die Computerressourcen eine sequentielle Verarbeitung ermöglichen.

Überlegungen zur Implementierung
Bei der Implementierung dieser Techniken verdienen mehrere Faktoren Aufmerksamkeit:
- Größe des Datasets: Große Datensätze profitieren für gewöhnlich mehr vom Bagging
- Computerressourcen: Das Bagging kann die parallele Verarbeitung nutzen
- Parameteranpassung: Das Boosting erfordert in der Regel eine feinere Abstimmung
- Interpretierbarkeit: Die gebaggten Modelle neigen dazu, leichter interpretierbar zu sein
Fazit
Das Bagging und das Boosting sind inzwischen grundlegende Techniken im Machine Learning. Während das Bagging Robustheit und Einfachheit durch parallelles Lernen bietet, liefert das Boosting starke sequentielle Verbesserungskapazitäten. Das Verständnis ihrer jeweiligen Stärken und Schwächen ermöglicht es Praktikern, den richtigen Ansatz für ihren spezifischen Anwendungsfall zu wählen.







