
Wenn wir es mit großen Datenbeständen mit enorm vielen Beobachtungen und komplexen Machine-Learning-Modellen mit vielen Hyperparametern zu tun haben, kann der Trainingsschritt mehrere Stunden dauern. In diesem Fall entsteht eine inverse Beziehung zwischen der Anzahl der Daten und der Leistung des Modells. Um also diese verlorene Zeit, die durch das Warten auf die Ausführung der Algorithmen verloren geht, zu reduzieren und diesen Leistungsabfall zu vermeiden, scheint cuML die Lösung zu sein!
💡Auch interessant:
| Bagging im Machine Learning – Was ist das ? |
| Deep Learning vs. Machine Learning |
| Data Poisoning |
| Machine Learning Data Sets Top 5 |
Was ist cuML ?
cuML ist eine OpenSource-API für Algorithmen. Sie ist Teil der RAPIDS-Pakete, deren Hauptmerkmal die Verwendung von Grafikprozessoren (GPUs) für alle Algorithmenstrukturen ist, nicht nur für neuronale Netze, wie es normalerweise der Fall ist. Genauer gesagt verwendet cuML einen beschleunigten Grafikprozessor, der die Leistung einer herkömmlichen CPU (Central Processing Unit) bei einfachen Machine-Learning-Algorithmen um das Vierfache und bei komplexeren Algorithmen um das Tausendfache steigern kann.
Dadurch ist es eine echte Alternative zu Scikit-Learn. Scikit-Learn ist eine Python-Bibliothek, die zwar vollständig ist und häufig in der Datenwissenschaft eingesetzt wird, aber für Big Data nicht sehr schnell ist.
Nehmen wir ein Beispiel, um die Ausführungszeit der beiden Bibliotheken zu vergleichen. Wir haben den Titanic-Datensatz, der auf Kaggle verfügbar ist, mit 8000 multipliziert, um einen Datensatz mit mehr als sieben Millionen Beobachtungen zu erhalten. Wir möchten eine binäre Klassifikation durchführen, um vorherzusagen, ob ein Passagier der Titanic überlebt oder nicht.
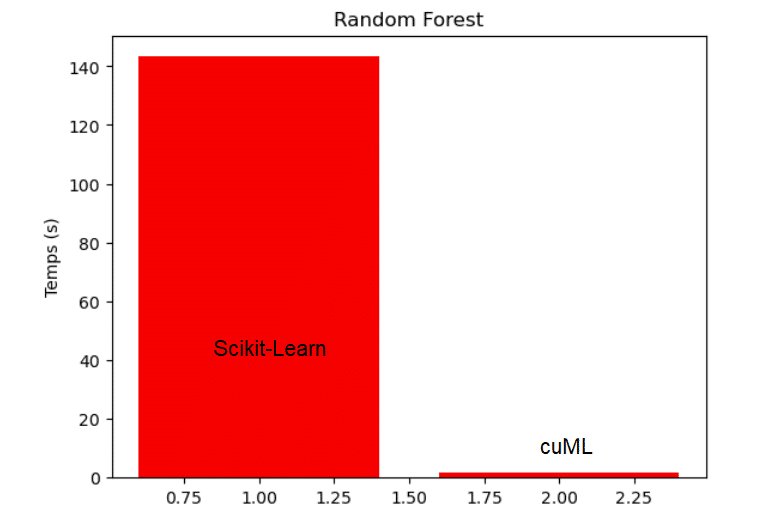
Mit Scikit-Learn dauert es 143 Sekunden, bis ein Random-Forest-Modell auf dem vergrößerten Datenframe trainiert ist. Mit cuML beträgt die Trainingszeit für ein Random-Forest-Modell auf demselben Datenrahmen nur 1,6 Sekunden. Dies beweist, wie viel effizienter und schneller cuML bei einem Data-Science-Projekt arbeitet!
Wie verwendet man cuML ?
- Installation: cuML ist Teil der RAPIDS API Suite. Du musst es über den RAPIDS Release Selector installieren, der über diesen Link aufgerufen werden kann, und cuML und die Optionen, die mit dem verwendeten Rechner kompatibel sind, ankreuzen.
- Benutzung: Die API von cuML ist der von Scikit-Learn sehr ähnlich, was sie einfach zu benutzen macht. Sie enthält statistische Werkzeuge, Preprocessing Scaler und Methoden zum Tuning von Hyperparametern, die auf die gleiche Weise definiert sind.
- Für die Modellierung nimmst du einfach das Modell aus der cuML-Bibliothek, übergibst ihm die Hyperparameter als Argument und benutzt die Methode .fit(), um es zu trainieren.
- Weiter geht es mit dem Titanic-Problem. Um das Modell Random Forest mit 200 Bäumen zu trainieren, verwenden wir den folgenden Code:
Dieser Code sieht gut aus wie der, den wir mit Scikit-Learn geschrieben hätten:
Wie gut sind die Vorhersagen?
cuML ist daher für Kenner von Scikit-Learn einfach zu benutzen und übertrifft diese Bibliothek sogar in Bezug auf die Geschwindigkeit.
In Bezug auf die Leistung scheint sie ebenso effizient zu sein.
Ob Regression, Klassifizierung oder Clustering, es wurde nachgewiesen, dass die Modelle von cuML in der Regel genauso gute Vorhersageergebnisse erzielen wie die von Scikit-Learn. Es ist sogar möglich, eine Reihe von Hyperparametern zu testen, um ein optimales Modell zu erhalten, Feature Selection zu betreiben und die Modelle zu interpretieren.
Somit scheint cuML die ideale Lösung für die Verarbeitung großer Datenbanken oder sich ständig ändernder Daten zu sein. Im Gegensatz zu Scikit-Learn, das zeitlich nicht konkurrenzfähig ist, und Spark, das auf einer herkömmlichen CPU basiert, nutzt cuML die Funktionen eines beschleunigten Grafikprozessors. Dies ermöglicht es, komplexe Modelle in kürzerer Zeit zu optimieren!
Jetzt, da du alles über cuML weißt, möchtest du es vielleicht in deinen Datenprojekten anwenden. DataScientest lädt dich dazu ein, unsere Datenschulungen zu besuchen.







