Gaußsche Kurve: Definition und Bedeutung in der Datenwissenschaft

Eine Gaußsche Kurve ist eine visuelle Darstellung von Daten, die dem Gaußschen Gesetz folgen. Hier findest du die vollständige Definition und erfährst, warum dieses Wahrscheinlichkeitsgesetz in der Data Science und im Machine Learning von entscheidender Bedeutung ist. In der Statistik ist eine Verteilung eine Sammlung von Werten und Häufigkeiten einer Beobachtung. Diese Beobachtung kann z. […]
Q-learning – Machine Learning mit Reinforcement Learning
Reinforcement Learning ist eine Methode des Machine Learning, mit der komplexe Aufgaben selbstständig gelöst werden können. Erst kürzlich machte diese Algorithmusfamilie im E-Sport von sich reden, als AlphaStar veröffentlicht wurde, ein Algorithmus, der entwickelt wurde, um die besten Spieler der Welt in StarCarft herauszufordern. Diese Algorithmen haben ein großes Potenzial, erweisen sich aber manchmal als […]
Dijkstra-Algorithmus: Wie findet man den kürzesten Weg?

Die Graphentheorie ist ein Zweig der Mathematik und Informatik, bei dem verschiedene Probleme aus dem wirklichen Leben in Form von Graphen modelliert werden. Eine der klassischsten Anwendungen ist die Modellierung eines Straßennetzes zwischen verschiedenen Städten. Eines der Hauptprobleme ist die Optimierung der Entfernungen zwischen zwei Punkten. Um die kürzeste Strecke zu finden, wird oft der […]
Azure Data Factory: Was ist das und wozu dient es?

Im Zeitalter von Big Data sind die Rohdaten oft unorganisiert und in unterschiedlichen Systemen gespeichert. Wenn diese Daten isoliert sind, können Unternehmen und Datenteams sie nicht optimal nutzen und daraus Entscheidungen ableiten. Die Microsoft Azure Data Factory soll diese Probleme lösen, indem sie Rohdaten aus verschiedenen Quellen zu verwertbaren Daten für Unternehmen macht. Was ist […]
K-means: Fokus auf diesen Clustering & Machine Learning Algorithmus
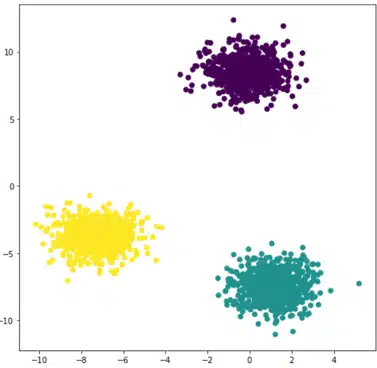
Clustering ist eine spezielle Disziplin von Machine Learning, mit dem Ziel, deine Daten in homogene Gruppen mit gemeinsamen Merkmalen aufzuteilen. Dies ist z. B. ein beliebtes Gebiet im Marketing, wo oft versucht wird, Kundenstämme zu segmentieren, um bestimmte Verhaltensweisen zu erkennen. Der K-Mittelwert-Algorithmus (K-means) ist ein sehr bekannter unüberwachter Algorithmus für das Clustering. In diesem […]
Boosting-Algorithmen – AdaBoost, Gradient Boosting, XGBoost
Wenn du dich für Machine-Learning-Algorithmen interessierst, hast du bestimmt schon einmal irgendwo die Wörter „Boosting“ oder „Boost“ gesehen. Man findet sie in einer Vielzahl von Algorithmus-Wettbewerben und sie erzielen oft sehr gute Ergebnisse. Aber was genau ist Boosting? In diesem Artikel lernst du den Unterschied zwischen einem Boosting- und einem Bagging-Algorithmus kennen. Danach wirst du […]
API: Was genau ist das und wozu dient es?

Application Programming Interfaces (APIs) sind in allen Branchen unumgänglich geworden. Ob Bankwesen, Marketing oder digitale Welt – die Zahl der APIs steigt stetig, genau wie die Zahl der zu verarbeitenden Daten. Aber was genau ist damit gemeint und wozu dienen sie? Eine API (Application Programming Interface) ist ein Programm, das es zwei verschiedenen Anwendungen ermöglicht, […]
Wie wird man Data Scientist?

Laut der Harvard Business School gilt der Beruf des Data Scientist als der“ heißeste Beruf des 21. Jahrhunderts“ und bietet großartige Karriereaussichten. Hast Du Dich schon immer gefragt, wie Du Data Scientist werden kannst? Wir zeigen Dir, welche Kompetenzen Du für Deine Weiterbildung brauchst! Um Data Scientist zu werden, solltest Du eine Weiterbildung als Data […]
Was genau ist ein Solutions Architect ?

Welche Rolle hat ein Solutions Architect ? Der Solutions Architect (SA) hat die Aufgabe, die technischen Probleme des Unternehmens, in dem er arbeitet, zu verstehen, Lösungen zu finden und die Umsetzung von Lösungen zu integrieren. Im Rahmen der beschleunigten Entwicklung von Informationssystemen (IS) ist der Lösungsarchitekt für die Erstellung eines problemgerechten Vorschlags sowie eines realisierbaren […]
Random Forest: Zufallswald, Definition und Funktionsweise
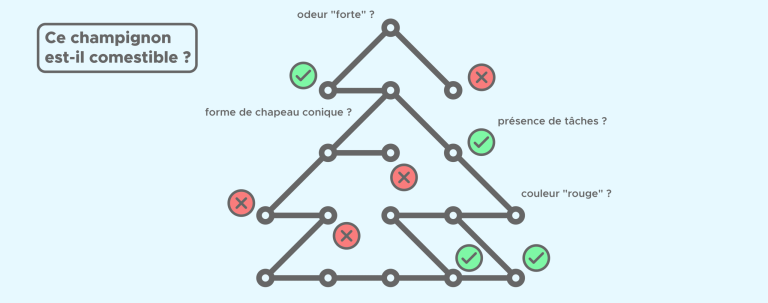
Ein Random Forest ist eine Machine-Learning-Technik, die bei Data Scientists sehr beliebt ist, und das aus gutem Grund: Sie hat im Vergleich zu anderen Data-Algorithmen viele Vorteile. Es ist eine einfach zu interpretierende, stabile Technik, die im Allgemeinen gute Akkuratesse aufweist und für Regressions- oder Klassifikationsaufgaben verwendet werden kann. Sie deckt daher einen Großteil der […]
Was ist ein Dataset? Wie wird es manipuliert?

Datasets (oder Datensätze) werden häufig im Machine Learning verwendet. Sie umfassen einen zusammenhängenden Datensatz, der in verschiedenen Formaten vorliegen kann (Texte, Zahlen, Bilder, Videos usw.). Datasets können in verschiedenen Arten dargestellt werden, seien es Tabellen, Graphen, Bäume oder andere. In Machine-Learning-Algorithmen wird oft mit Array-Strukturen gearbeitet. Jeder in einem Dataset vorhandene Wert ist mit einem […]
5 Schritte, um einen statistischen Test durchzuführen

Möchtest du wissen, ob der Notendurchschnitt zwischen zwei Klassen sich voneinander unterscheidet? Oder wissen, ob die Umweltverschmutzung in einer Stadt über einem zulässigen Wert liegt? Wie können Sie die Wirksamkeit einer neuen Behandlung in einer Population testen? Hier setzen wir statistische Tests ein! Datascientest zeigt dir die Methode, um einen statistischen Test in 5 Schritten […]
