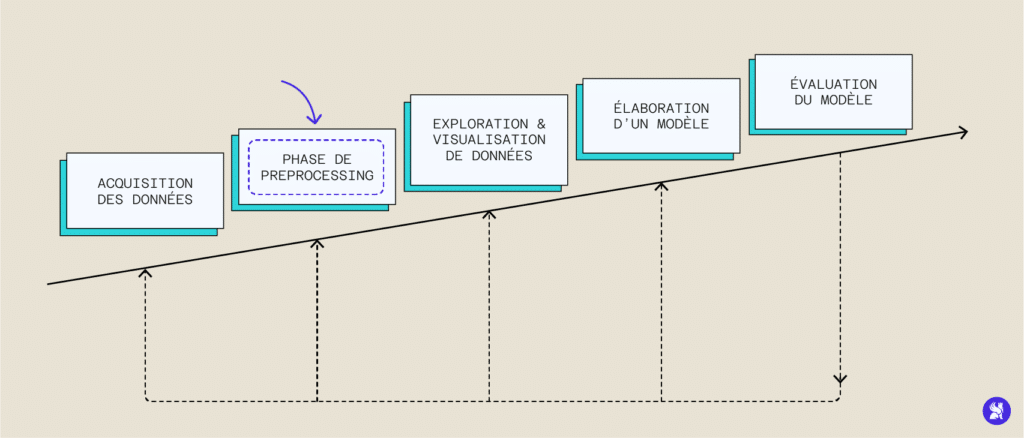
La multiplication de l’acquisition de données et leur traitement systématique a permis l’essor des méthodes de machine learning nécessitant de nombreuses données pour tourner et s’entraîner. Bien que l’on puisse naïvement penser qu’il suffit d’un grand nombre de données pour avoir un algorithme performant, les données dont nous disposons sont la plupart du temps non adaptées et il faut la plupart du temps les traiter préalablement pour pouvoir ensuite les utiliser : c’est l’étape de preprocessing.
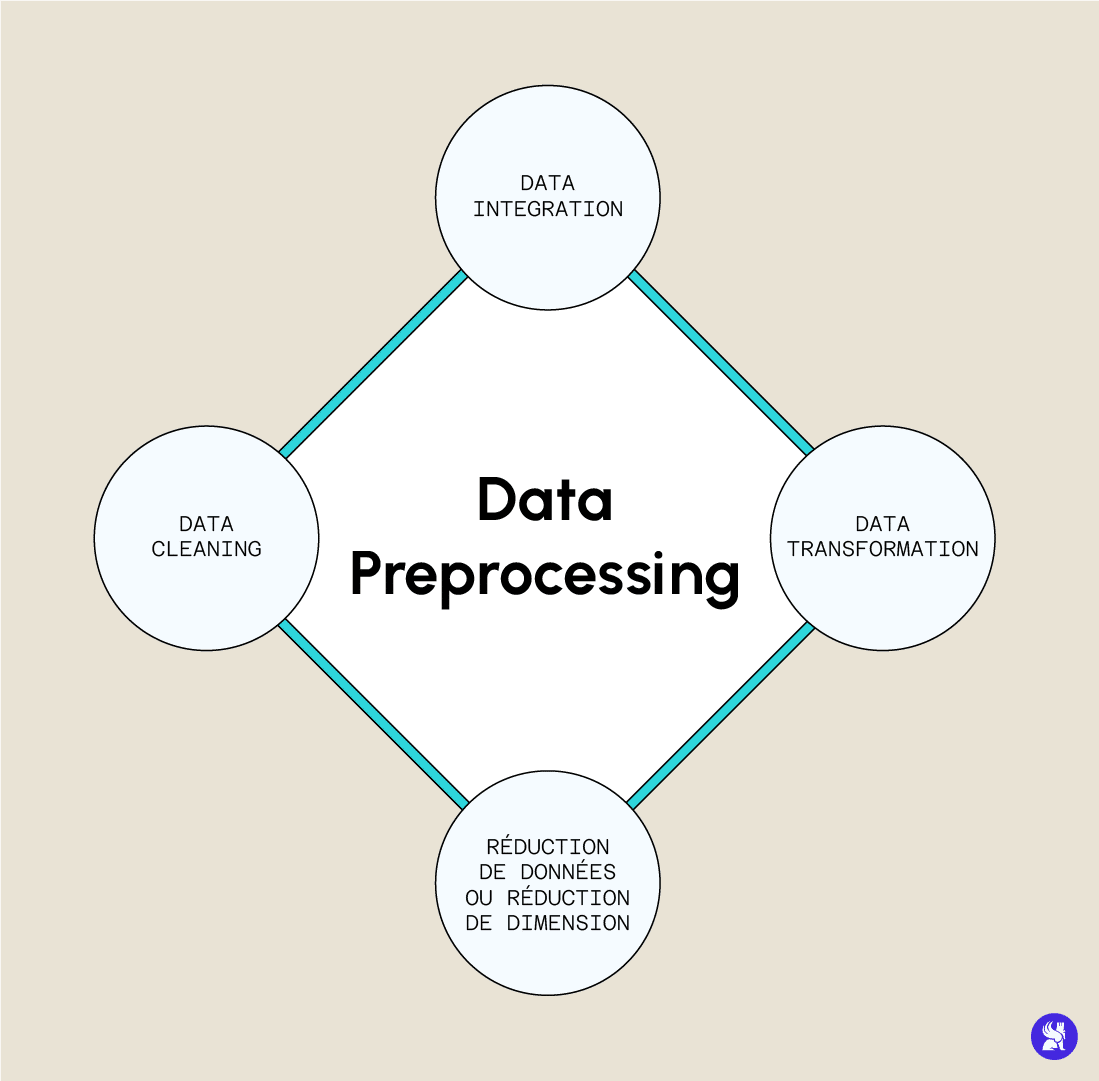
En effet, des erreurs d’acquisition liées à des fautes humaines ou techniques peuvent corrompre notre dataset et biaiser l’entraînement. Parmi ces erreurs, nous pouvons citer des informations incomplètes, des valeurs manquantes ou erronées ou encore des bruits parasites liés à l’acquisition de la donnée. Il est donc souvent indispensable d’établir une stratégie de prétraitement des données – autrement appelé Data Preprocessing – à partir de nos données brutes pour arriver à des données exploitables et qui nous donneront un modèle plus performant. Nous allons explorer les étapes les plus importantes de ce preprocessing, leur importance et leur implémentation en Python pour certaines.
Data Cleaning : Les différentes étapes
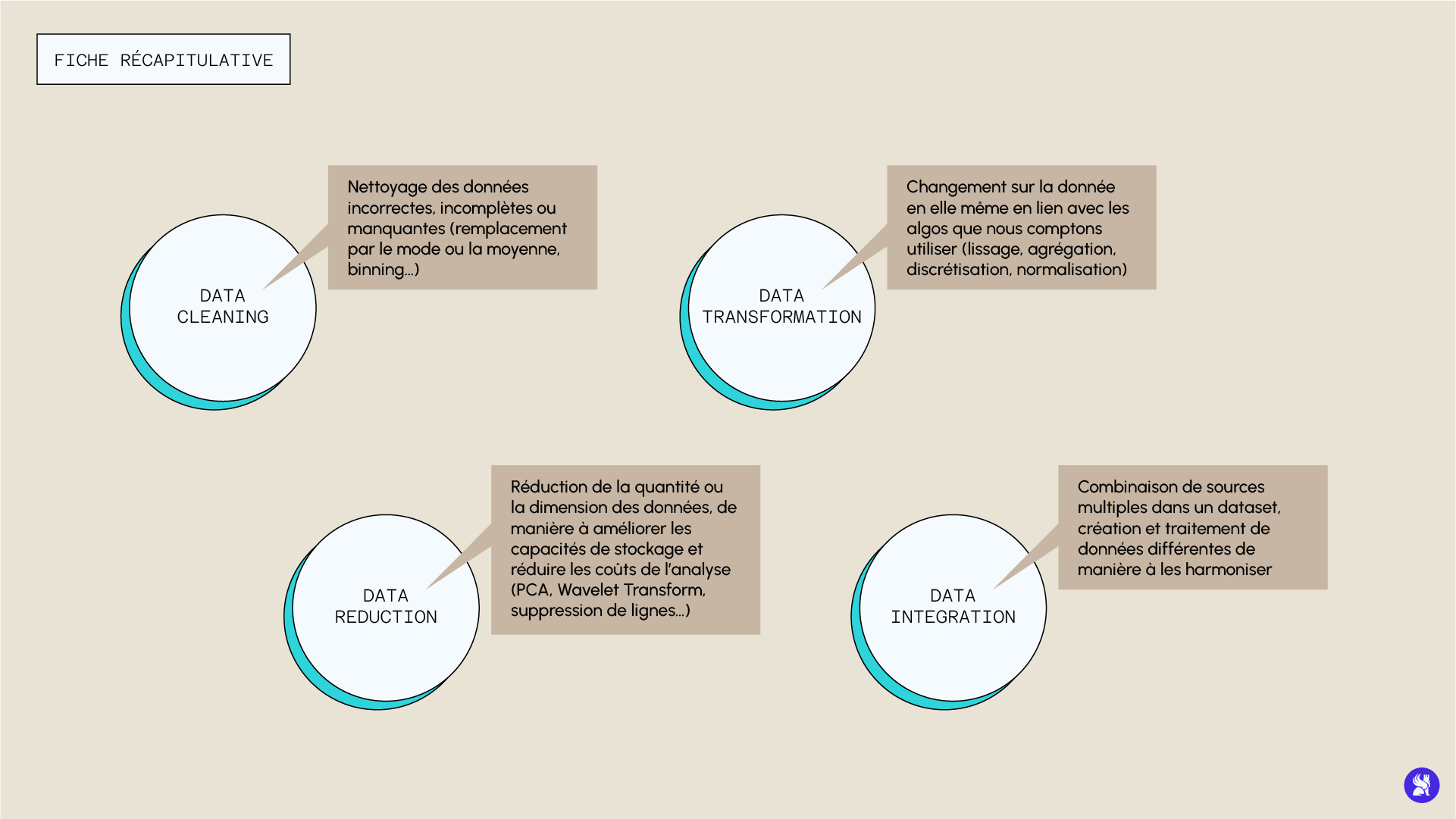
La première étape consiste en un nettoyage des données incorrectes, incomplètes ou manquantes. Il existe plusieurs manières de gérer ces problèmes que nous allons passer en revue.
S’il manque des données dans le dataset, vous pouvez choisir de les ignorer dans le cas où la base de données est assez fournie et si de nombreuses données sont manquantes au sein de la même ligne. Vous pouvez également décider de remplir ces données manquantes de différentes manières : vous pouvez les remplacer par la valeur moyenne, par la médiane, ou par exemple par la modalité la plus fréquente dans le cas de variables catégorielles (autrement appelé le mode). Pandas nous fournit des méthodes qui nous permettent d’effectuer ces traitements de la manière suivante :
Il peut arriver que des données souffrent d’un bruit parasite d’acquisition, auquel cas, elles ne pourront pas être correctement traitées par un ordinateur. Une manière de traiter ce problème est d’effectuer un binning des données (préalablement triées). Ces dernières sont séparées en groupe de même taille et chaque groupe est traité indépendamment. Au sein d’un même groupement, toutes les données peuvent être remplacées par leur moyenne, leur médiane ou par les valeurs extrêmes.
Une autre façon de traiter des données bruitées, et d’utiliser une régression ou un clustering, créant automatiquement des groupes de données et qui pourront nous permettre de détecter les outliers et de les supprimer de la base de donnée.

Data Transformation : Dans quel but ?
Cette étape de prétraitement regroupe les changements effectués sur la structure même de la donnée. Ces transformations sont liées aux définitions mathématiques des algorithmes et à la manière dont ceux-ci traitent les données, de manière à optimiser les performances. Parmis ces techniques, nous pouvons citer par exemple :
- Le lissage des données si elles sont bruitées.
- L’agrégation de données venant de plusieurs sources différentes.
- La discrétisation de variables continus (à l’aide du découpage en intervalles) qui permet d’abaisser le nombre de modalités d’un descripteur, et enfin.
- La normalisation et la standardisation des données qui ramènent les données numériques à une échelle plus petite (par exemple entre -1 et 1), qui peuvent également centrer la moyenne et réduire la variance.
Voici en exemple une manière d’effectuer une normalisation, étape la plus souvent nécessaire dans cette partie de transformation des données :
Data Reduction : Qu'est ce que c'est ?
Bien qu’il paraisse intuitif d’imaginer qu’une très grande quantité de données améliore la performance d’un modèle, il se peut qu’une masse de données trop importante puisse rendre l’analyse plus compliquée. Il peut donc parfois être intéressant de réduire la quantité ou la dimension des données, de manière à améliorer les capacités de stockage et réduire les coûts de l’analyse, sans pour autant perdre en performance (voire dans certains cas en gagner). Il existe plusieurs techniques de réduction de données, nous pouvons par exemple choisir un certain nombre de variables que nous préférons garder et en laisser tomber d’autres. Le choix des variables pertinentes peut se faire par l’analyse de la p-valeur de la variable, ou par des techniques d’arbres de décisions qui nous donne une estimation de l’importance des différents descripteurs.
Une autre technique très utilisée dans l’idée de réduction de la donnée est la réduction de sa dimension. Cette méthode réduit la dimension de la donnée par des mécanismes d’encodage bien définis. Il en existe deux types, avec ou sans perte. Si l’on peut reconstruire les données exactes à partir des réduites, on parle de réduction sans perte. Sinon, la réduction se fait à perte. Il existe deux méthodes privilégiées pour agir de cette manière sur les données, une transformation wavelet ou un PCA (Principal Component Analysis).
Data Integration : Une étape importante dans le préprocessing
Cette étape de la stratégie de preprocessing consiste à combiner des sources multiples dans un seul dataset. Elle est effectuée dans un cadre de management des données pour la création de bases exploitables (comme la création de bases d’images, de coupes transversales de l’abdomen, d’IRM ou de radios pour des problèmes d’aide au diagnostic). Il y a tout de même certains problèmes qui pourraient apparaître, par exemple l’incompatibilité de certains formats ou la redondance de certaines données.
L’étape du traitement préliminaire des données est donc l’une des plus importantes dans le traitement et l’analyse de données. Il n’existe pas de méthode parfaite à appliquer à chaque création d’un modèle, mais nous avons vu ensemble les bonnes pratiques à mettre en place dans une stratégie de traitement préalable des données. Les méthodes présentées ici sont explorées plus en profondeur dans nos différentes formations : les concepts mathématiques fondamentaux ainsi que les bonnes pratiques du prétraitement des données en fonction du contexte et de la situation y sont expliquées.
Pour découvrir nos cursus en détail et apprendre toutes les bonnes pratiques du data preprocessing, rendez-vous sur la page dédiée.








