L’univers des modèles de langage pour le codage continue de s’étoffer avec l’arrivée de Qwen2.5-Coder, un modèle open source ambitieux lancé récemment. Avec des performances équivalentes ou supérieures à celles de GPT-4o et Claude 3.5 dans des contextes de génération de code, réparation de bugs et traitement multilingue, Qwen2.5-Coder semble prêt à transformer l’écosystème de l’intelligence artificielle appliquée au développement.
Plus qu’un simple LLM
Qwen2.5-Coder n’est pas seulement un modèle de langage, c’est une suite d’outils open source mise à disposition par une communauté de chercheurs et d’ingénieurs motivés par l’accessibilité des technologies avancées de génération de code. Proposé en plusieurs tailles (de 0,5B à 32B), Qwen2.5-Coder couvre une large gamme de besoins, de ceux des amateurs aux experts en IA et en Data Science. Chaque modèle est conçu pour offrir un équilibre optimal entre la capacité de traitement et l’utilisation de ressources, et pour s’adapter à diverses configurations matérielles.
Grâce à des bases de données de formation enrichies et optimisées, Qwen2.5-Coder a développé une spécialisation unique dans plus de 40 langages de programmation, dont des langages complexes et moins utilisés comme le Haskell et le Racket. Son architecture permet également une adaptation aux préférences des utilisateurs, rendant ce modèle plus intuitif et accessible pour les interactions humaines en code.
En quoi concurrence-t-il GPT-4o et Claude 3.5 ?
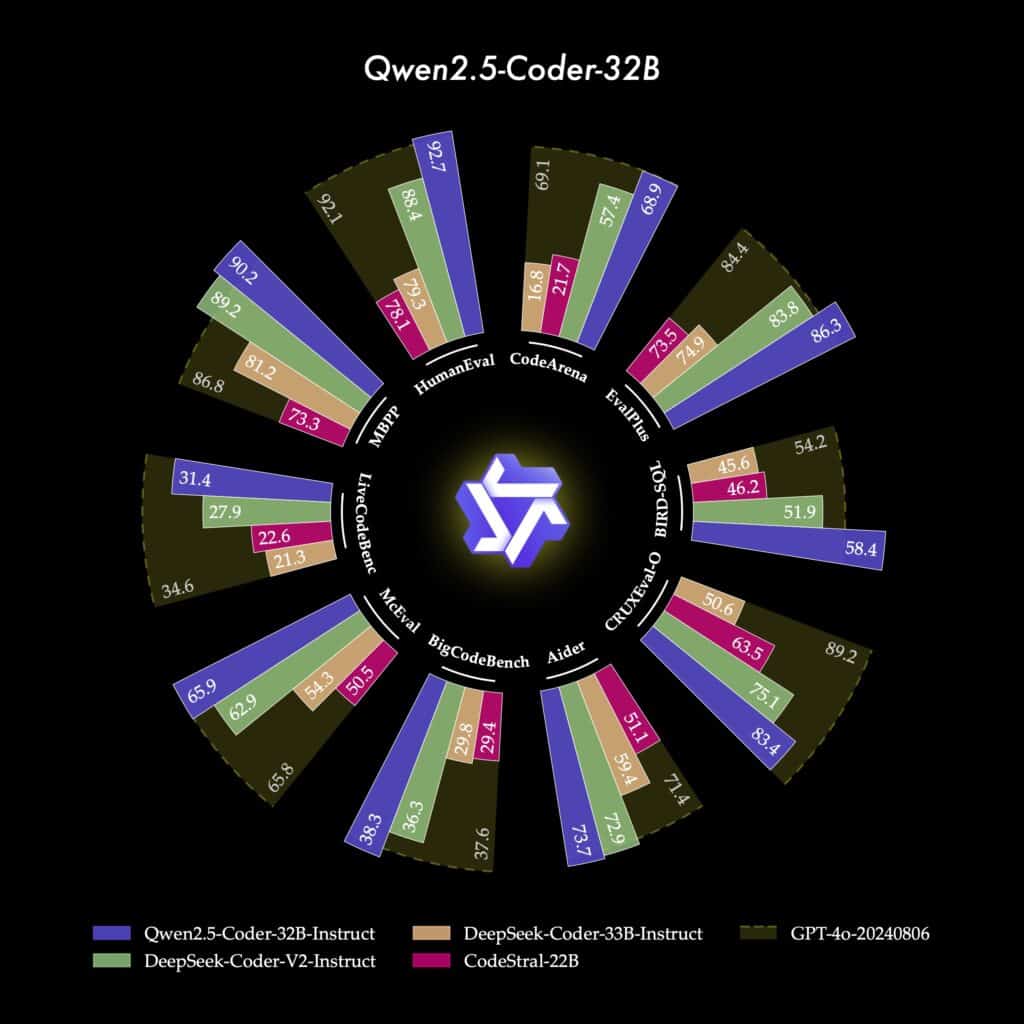
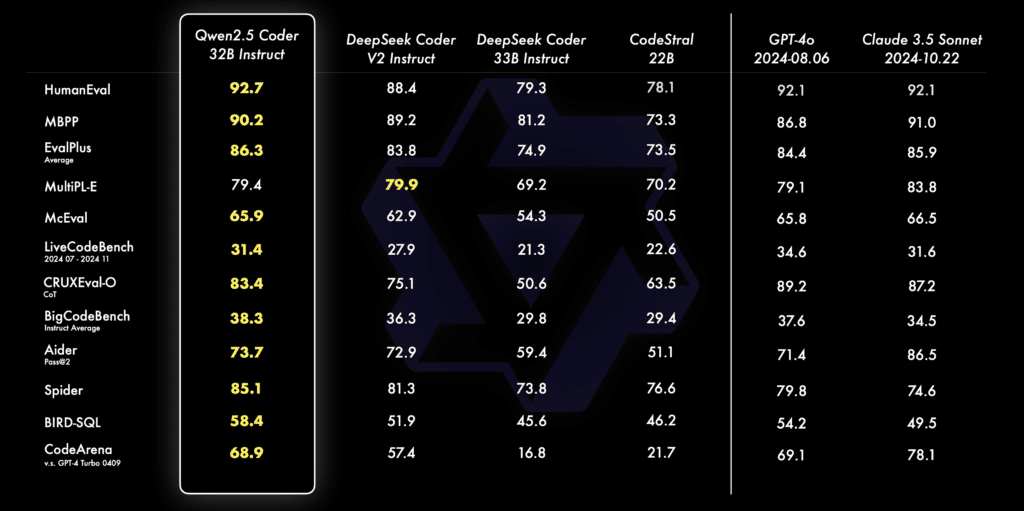
Qwen2.5-Coder se positionne comme une alternative plus abordable et personnalisable que GPT-4o et de Claude 3.5 pour les développeurs et les entreprises. Sur plusieurs benchmarks réputés comme EvalPlus, LiveCodeBench et BigCodeBench, il rivalise avec ces géants fermés, en atteignant des résultats de pointe dans la génération de code et la réparation automatique de code.
En matière de raisonnement, Qwen2.5-Coder excelle aussi avec des capacités avancées en prédiction des entrées et sorties de code, surpassant GPT-4o dans certains contextes de calculs et de logique. Son modèle 32B-Instruct, conçu pour offrir une interaction directe avec l’utilisateur, s’aligne particulièrement bien avec les préférences humaines grâce à son benchmark interne, Code Arena, et une méthode d’évaluation qualitative inspirée des pratiques de l’IA conversationnelle.
Enfin, le modèle apporte une capacité de génération visuelle via des applications comme Open WebUI, permettant la création d’artéfacts visuels tels que des simulations et des mini-jeux, où la fluidité et la qualité de Qwen surpassent les standards open source actuels.
Si cet article vous a plu et si vous envisagez une carrière dans la Data Science ou tout simplement une montée en compétences dans votre domaine, n’hésitez pas à découvrir nos offres de formations ou nos articles de blog sur DataScientest.
Source : qwenlm.github.io








