
Pour certains, l’univers du football, c’est une chose très sérieuse, source des plus grandes émotions. Pour d’autres, c’est une occupation accessoire et futile, (« C’est juste des gens qui courent après un ballon après tout »).
Pour certains, l’univers de la Data, c’est un domaine très compliqué, réservé à quelques « geeks » initiés. Pour d’autres, c’est un moyen d’apporter de la clarté et un éclairage sur les sujets du quotidien.
Pour nous, Gayelord et Julien, fans de sport et motivés à l’idée de progresser dans la Data en débutant notre parcours de formation de Data Analyst avec DataScientest.com, c’était la perspective de nombreux challenges à surmonter.
CONTEXTE DU PROJET
Cadre général
Dans le cadre de cette formation de 6 mois, nous avons travaillé sur un projet fil rouge afin de mettre en pratique les diverses notions vues pendant les cours. Avec le soutien de notre mentor projet Alban Thuet, nous choisissons de travailler sur les données de l’application Mon Petit Gazon (ou MPG pour les fans).
MPG, c’est une appli de « fantasy football » : plusieurs joueurs créent leur équipe de football et vont s’affronter chaque week-end, chacun avec son équipe, en fonction des prestations réelles des joueurs.
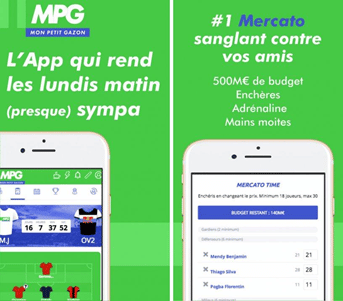
MPG, pour les nuls
Cette application de divertissement compétitif ancré dans l’univers du football comporte 2 grandes phases :
- MERCATO : les protagonistes créent une ligue dans laquelle ils vont s’affronter. Grâce à un budget (virtuel 😉) de 500 M€, chaque joueur constitue une équipe, en sélectionnant des joueurs d’un championnat majeur européen, via un principe d’enchères secrètes.
- CHAMPIONNAT : une fois les équipes constituées, les protagonistes s’affrontent dans des duels où se rencontrent leurs compositions respectives. Le résultat de cette confrontation est déterminé, en grande partie, par les prestations dans la « vraie vie » des joueurs qu’ils auront sélectionnés. Mais quelques bonus et règles spéciales pourront aussi avoir un impact : la tactique, les récompenses pour les joueurs méritants sur un plan statistique ou encore les coachs les plus stratèges.
En outre, MPG fait notamment appel à un principe de notation, ou note MPG, impactée, entre autres, par l’activité sur le terrain du joueur (via un grille de notation et lié à son poste sur le terrain). Mais également au principe de but virtuel, ou but MPG, impacté par la comparaison d’une note d’un joueur à celles des notes adverses.
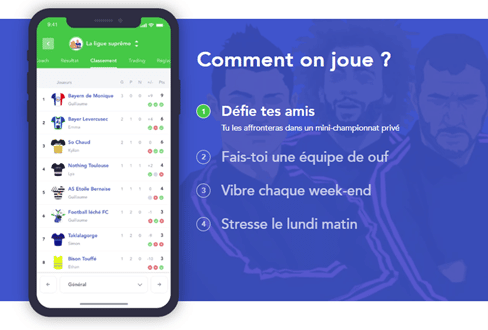
Notre ambition
D’un côté, même si un championnat MPG se conçoit comme un moment ludique et convivial, cela n’en reste pas moins une compétition. Beaucoup de joueurs seront au taquet sur leur composition d’équipe et sur l’appli afin de performer et d’éviter la honte du lundi matin, si leur équipe n’a pas été au top pendant les matchs du week-end !
D’un autre côté, en tant qu’apprenants, le projet avait pour but d’appliquer nos cours théoriques, et par la même occasion d’apprendre de nouvelles choses.
Au regard de ces deux constats, nous avions de grandes ambitions et comptions faire davantage que simplement valider le projet (en mode compétiteur, pour se surpasser) : notre objectif allait être de proposer des outils pour tous les joueurs MPG, afin de les aider à aligner la meilleure équipe pour affronter ses adversaires et enchaîner les victoires (« Droit au But », comme on dit !). Nous souhaitions montrer que la data pouvait se mettre au service d’une app de jeu de foot (si, c’est possible).
Nous avons principalement eu recours à Python et ses packages les plus fréquents en data visualisation (Pandas, Seaborn, Matplotlib, Plotly) et Machine Learning (Numpy, Scikit-Learn), ainsi qu’à Streamlit pour la restitution et la création des outils. D’un point de vue data analyse pur, l’objectif du projet était de créer un modèle de Machine Learning qui permette de prédire la note d’un joueur lors de la prochaine rencontre, à l’instar de l’Almanach des Sports de Marty McFly.
Comme vous allez le voir, ce projet nous a permis d’utiliser quasiment tous les outils vus pendant les différents cours, donc hyper intéressant d’un point de vue pédagogique. Et si en plus, on peut joindre l’utile à l’agréable et battre tous ses potes à MPG, ça fait plaisir !
LE PROJET
Si nous avions notre sujet et une ambition pour le résultat final, afin de partir du bon pied, nous devions d’abord répondre à quelques questions légitimes et classiques que se posent souvent (toujours ?) un Data Analyst.
D’où viennent mes données ? à quoi ressemblent-elles ? Quelles informations et conclusions je souhaite et je peux en retirer ? Quelle « logistique » mettre en place pour collecter, compléter, traiter et exploiter ces données au fil de l’avancement du projet ?
La pêche aux infos
Première étape de ce projet : étudier le sujet pour trouver ce qui existe déjà sur la toile, comprendre le fonctionnement de l’appli en elle-même. Ces recherches nous ont permis d’appréhender les liens éventuels entre MPG et le monde de la data. En parallèle, nous avons cherché des personnes qui pourraient également nous aider à mieux cerner les problématiques des joueurs et comment la data pouvait les aider. C’est comme ça que nous avons récolté de précieuses informations d’anciens alumni du programme Datascientest, mais également de la part de professionnels du métier, comme l’équipe MPG Stats.
Construire un jeu de données initial
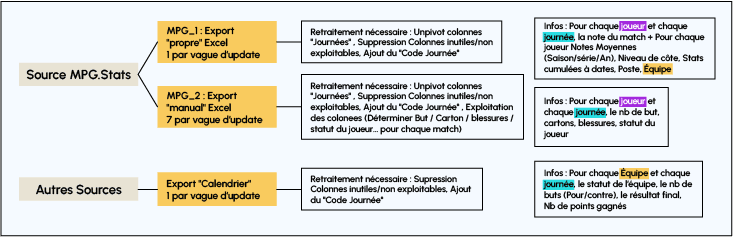
Contrairement à d’autres projets, nous n’avions pas vraiment de jeu de données pré-établi, juste un site où récupérer des statistiques issues du jeu (toujours les mêmes chez MPG.Stats). Plutôt sympa, sauf quand tu découvres que les buts inscrits ne sont pas disponibles via le bouton « Exporter ». Mini-drame.
Un Data analyst se doit d’être flexible et malin, alors on creuse un peu, on bricole une méthodologie pour extraire une information un peu plus « brute » et on va chercher ailleurs des éléments qui nous semblent pertinents (le calendrier des matchs). Avant même de l’aborder en cours, on faisait du Data Scraping rudimentaire.
Établir un modèle de données
Des données brutes ne suffisent pas. Un retraitement est souvent (toujours ?) nécessaire, car il y a des valeurs manquantes, des mises en forme hétérogènes, des informations à déduire, des concepts à définir pour liées nos sources entre elles. En un mot, bâtir un modèle de données.
Dans notre cas, à partir de données facilement accessibles à un utilisateur de MPG, et grâce aux notions de Joueur, Journée et d’Équipe, nous avions de quoi déterminer le contexte des notes MPG au niveau de l’équipe et du joueur, ainsi que des métriques MPG (nombre de buts, côte du joueur, notation MPG à l’issue d’un match).
Exploration et visualisation
Vu notre objectif, le choix de la variable cible a été assez simple : il s’agissait de la Note du joueur au prochain match. Avec plus de 90 variables, l’exploration de données était vraiment nécessaire pour trier et ne retenir que les variables intéressantes. Grâce aux packages Matplotlib et Seaborn, nous avons pu créer de nombreux graphiques, toujours en essayant au maximum d’utiliser les éléments vus en cours.
Pour la visualisation, nous avons choisi deux axes :
1. Histogramme concernant cette variable « Note »
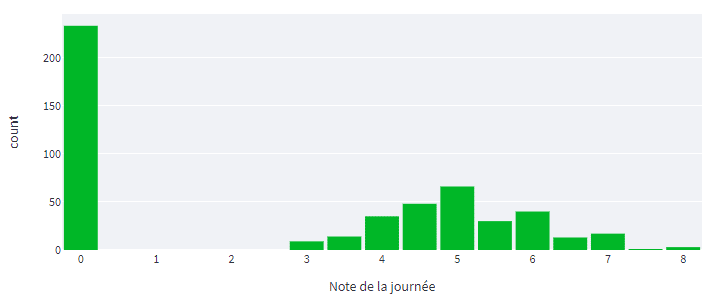
À ce stade, on identifie déjà 2 groupes distincts, les joueurs avec une note MPG et ceux sans note (ceux qui sont restés sur le banc ou dans les tribunes).
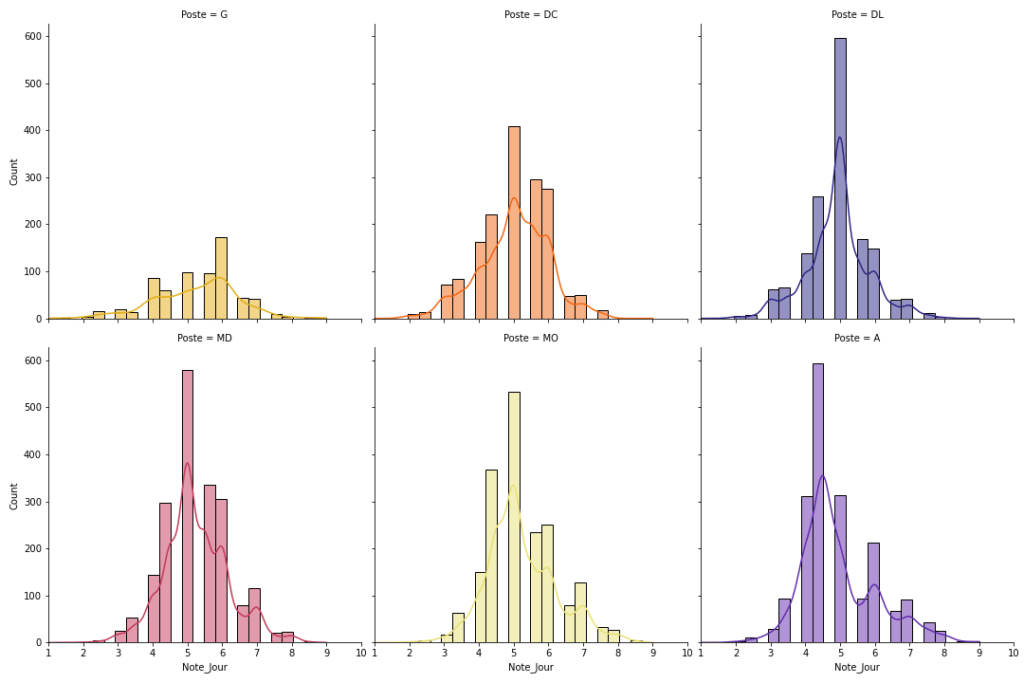
Pour tous les postes, on observe une distribution gaussienne « en cloche », l’objectif de notre modèle prédictif étant d’identifier les valeurs extrêmes supérieures (notations les plus élevées).
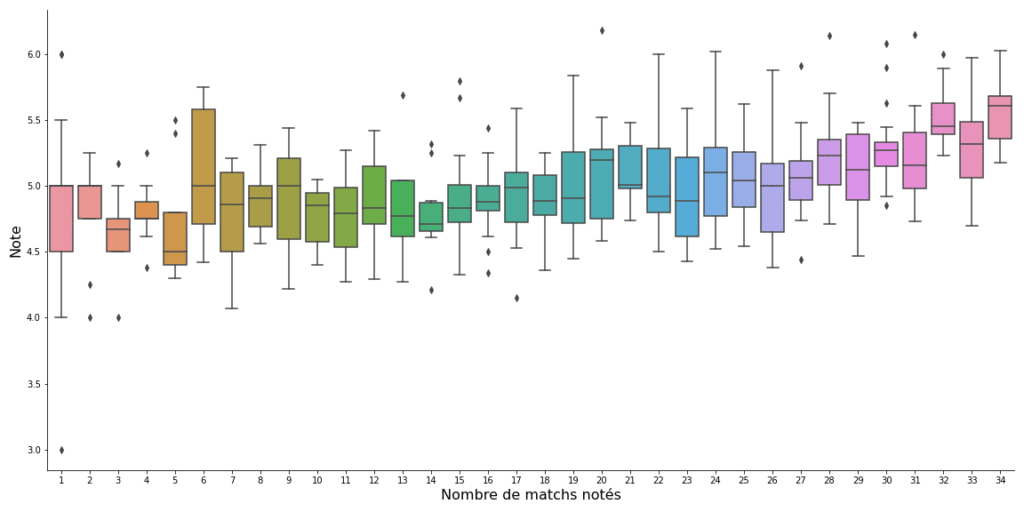
Une compétition MPG s’inscrit sur une durée de plusieurs journées, il est intéressant d’observer que les joueurs jouant beaucoup obtiennent des notes en moyenne légèrement supérieures, ce qui traduit une certaine constance de leur niveau de jeu.
2. DataViz sur des éléments qui pourraient avoir un impact sur cette variable
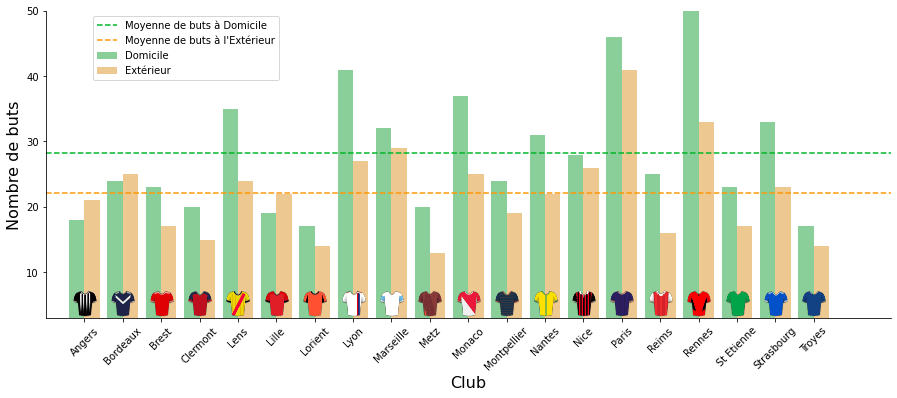
Avec ce graphique, on a cherché à repérer les clubs qui marquent le plus de buts (et donc avec un vivier de joueurs à même de scorer dans MPG). Et on cherchait aussi à comparer l’incidence du lieu du match (jouer à domicile ou à l’extérieur).
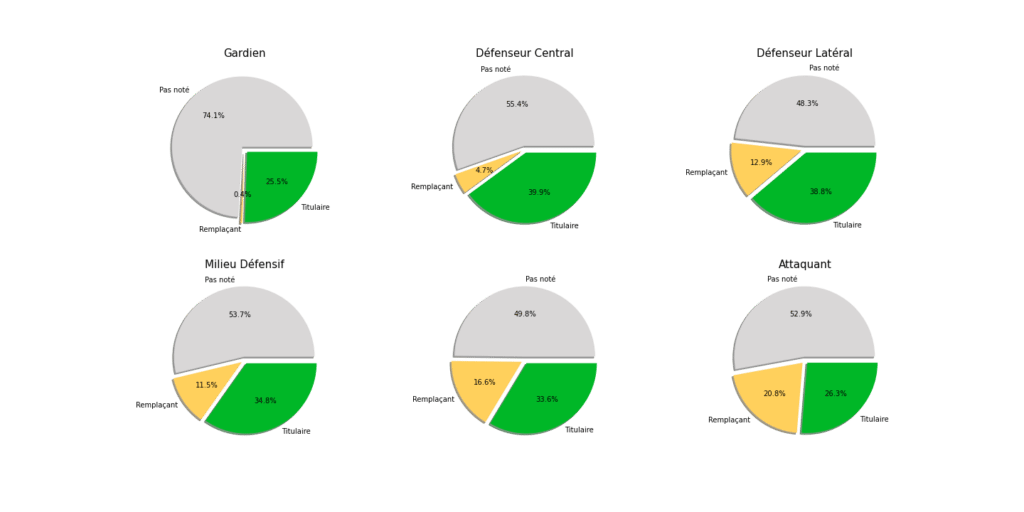

Le but de ce graphique est de comparer les notes des joueurs selon leur poste et voir si le déplacement de l’équipe a un impact sur la qualité des notes obtenues.
Machine Learning
À ce stade du projet, on rentre vraiment dans le dur en essayant de trouver un modèle de machine learning qui nous donne les meilleurs résultats. C’est une étape complexe, mais assez grisante lorsque l’on fait tourner les modèles et qu’on attend (avec impatience) les résultats des tests après les différentes itérations.
Les 4 grandes phases de cette étape :
1/ Choix des variables
Suite à l’étape de DataViz, nous avons utilisé les matrices de corrélation pour encore réduire le nombre de variables à utiliser pour la phase de Machine Learning.

Cela peut faire un peu mal aux yeux de prime abord, mais en réalité, c’est un outil très utile ! Suivront quelques ajustements au niveau du dataframe, pour au final disposer de 49 variables (au lieu des 96 du début).
Ultime étape de préparation des variables : nous avons créé les différentes classes de notre variable cible en la discrétisant en 4 classes, selon la note obtenue à l’issue d’un match :

Cela nous donne un jeu quelque peu déséquilibré, ce qui peut conduire les modèles de Machine Learning à avoir des difficultés pour identifier correctement la (ou les) classe(s) minoritaire(s) (ici la classe 3, soit les meilleures notes obtenues).
Cette situation nous a conduit à mener les tests expliqués dans les parties suivantes.
2/ Entraînements des modèles
Nous avons alors décidé de tester plusieurs algorithmes afin de trouver le plus performant :
- Régression logistique
- K plus proches voisins
- Random Forest
- Balanced Random Forest
- Decision Tree
- SVC
- GradientBoosting
Après avoir effectué les premiers tests « bruts », c’est-à-dire sans modifier aucun paramètre, nous avons observé que le modèle SVC générait les résultats les plus encourageants au niveau du score d’accuracy :
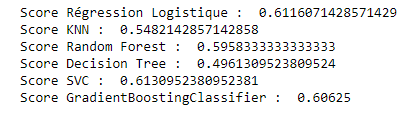
3/ Features engineering sur le modèle retenu
Il s’agit d’un procédé itératif, pas piqué des hannetons, que nous avons mené pour affiner la sélection de données et l’évaluation du modèle. L’idée est de tester le modèle sur de nouvelles données à l’aide des caractéristiques choisies et d’identifier d’éventuelles améliorations des indicateurs de performance :
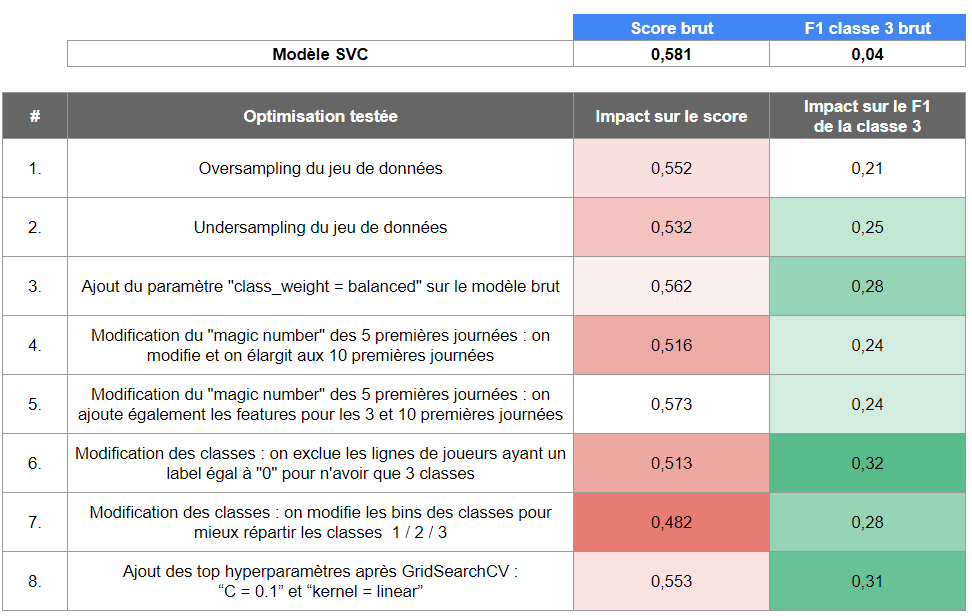
Constats :
- Le modèle ‘brut’ conserve le meilleur score d’accuracy
- Tous les tests ont permis d’améliorer nettement le F1 de la classe 3
- L’ajout des 3 hyperparamètres permet de conserver un score correct et d’améliorer fortement le F1
- Les tests de feature engineering ont donné de bons résultats, mais qui restaient moins significatifs
Les meilleures performances sont obtenues grâce à l’ajout des 3 hyperparamètres, sans besoin de modifier le jeu de données initial. Nous avons pu mener de nombreux tests sur plusieurs items et nous obtenons, in fine, un modèle qui va nous permettre de proposer de nouveaux outils aux joueurs de MPG. À découvrir dans la section suivante !
Création d’outils
Le but d’un Data analyst est de fournir des livrables tangibles et actionnables.
Forts de notre compréhension des données et de notre capacité à prédire les résultats futurs, il s’agissait pour nous de fournir les outils à même de répondre à notre problématique initiale : Comment être en mesure d’aligner la meilleure équipe possible ?
Pour cela, il a fallu reproduire et automatiser le processus de réflexion des joueurs, se mettre à la place de l’utilisateur et fournir de quoi répondre à ses attentes.
À l’issue de notre projet, nous étions en mesure de proposer
- Un outil de constitution d’équipe automatisé (utile quand tu n’y connais rien au foot)
- Un suivi des notes des joueurs, journée après journée (pratique quand tu veux frimer à la pause café)
- Un débriefing des performances du week-end (pertinent, quand tu veux comprendre ce qui à bien ou mal fonctionné lors de ton dernier match)
- Une prédiction des notes à venir pour aligner son 11 optimal (avantageux, si tu veux gagner ton prochain match)
Travailler en équipe
Un aspect important du projet a été de trouver une méthode de fonctionnement efficace, à même de concilier les contraintes de résultats, d’agendas et de connaissances.
Nous avons opté pour une approche « Divide and conquer », en partitionnant le projet en plusieurs étapes distinctes. Et nous avons convenu de certaines « passerelles », le résultat de l’une devant nécessairement être le point de départ de l’autre.
Nous avons essayé de maintenir une certaine lisibilité et documentation dans la rédaction de nos lignes de code et de ne pas modifier un code existant sans en avoir informé son créateur.
À l’instar des joueurs de Ligue 1, nos week-ends étaient ponctués de session de travail et nos agendas, rythmés par nos visios avec notre tuteur.
Télétravail oblige, nous avons opté pour des solutions collaboratives où les ressources et les réalisations de chacun sont accessibles.
Enfin, une bonne coordination a été requise au moment de fusionner les différents blocs de code, notamment lors du travail dans Streamlit. Déclaration de variables, packages à charger pour assurer le bon fonctionnement de l’ensemble, mise en forme et signalement des bouts de code à ajouter/modifier, sont quelques exemples concrets de situation à gérer pour toute future équipe-projet.
Restituer et mettre en valeur le travail
Nous avons fait le choix, assez tôt dans le projet, de créer une app sur Streamlit. Nous trouvions cela plus ludique pour nous, mais également plus « user friendly » pour la restitution et le partage. Il nous a fallu nous former à l’outil via de nombreux sites et tuto trouvés sur YouTube, pour compléter les acquis vus pendant la formation DataScientest (toujours cet amour du défi !). Grâce à cela, nous avons pu vraiment peaufiner l’app créée pour en faire un véritable support de partage. Après avoir créé un repository sur Github, nous avons pu utiliser le Community Cloud de Streamlit, ce qui nous a permis d’obtenir un lien pour notre app, partageable avec le monde entier !
LIMITES ET AXES D'AMÉLIORATION
Si nous avons effectivement pu atteindre les objectifs que nous nous étions fixés, certaines idées et pistes d’amélioration ont pu apparaître en cours de projet et seraient intéressantes à creuser.
- Nous avons abordé l’exercice de prédiction des notes MPG et de son exploitation du point de vue d’un seul joueur. Hors, MPG est une expérience multijoueurs, considérer le contexte ambiant de l’utilisateur, via d’autres variables explicatives, pourrait être intéressant.
- L’apport des bonus disponibles dans le jeu a été partiellement intégré, or, tout l’intérêt d’un match MPG réside dans la capacité à choisir le bon moment pour activer ou non son bonus, d’autant qu’ils sont limités en nombre.
- Le jeu de données a été constitué via les sources les plus facilement accessibles à un utilisateur MPG. Cependant, il pourrait être intéressant de s’appuyer sur l’intégralité des statistiques prises en compte par MPG pour établir ses notations. La réouverture d’une version web de MPG et davantage de data scraping pourraient permettre d’enrichir le jeu de données.
- Notre restitution finale via Streamlit constitue une « proof of concept » mais pas une application fonctionnelle. Un projet plus ambitieux serait donc d’aboutir à une solution facilement utilisable et accessible à tout utilisateur de MPG.
Si l’aventure vous intéresse, n’hésitez pas à vous rendre sur notre repo Github pour en savoir plus.
CONCLUSION
Après des semaines la tête dans le guidon (et les lignes de Python), et ayant démarré avec peu de bagage technique, on peut raisonnablement dire que nous avons musclé notre jeu et gagné en confiance. Nous avons eu la chance de mettre en pratique quasiment toute la panoplie de notions et théories vues pendant les cours de la formation.
Ces nouvelles compétences acquises ne seront peut-être pas toutes mises en application ou maintenues dans l’avenir. Cependant, nous avons la conviction que la Data est, certes, un sujet sérieux, mais est aussi un sujet qui peut s’appliquer partout, même sur les terrains plus ludiques (voire carrément fun), pour peu qu’on soit motivé et déterminé.
Progresser par étapes et avec méthode, chercher à se documenter et à s’appuyer sur les réalisations des prédécesseurs, sont quelques conseils de bon sens adressés aux futurs apprenants de DataScientest et d’ailleurs.
Aux data analysts à venir, gardez pour vos projets, ces quelques mots d’encouragement :
"Tout est possible à qui ose, travaille et n'abandonne jamais"
Xavier Dolan









