MeanShift est un algorithme de clustering très utilisé pour la vision par ordinateur (Computer Vision) et l’analyse de données. Découvrez tout ce que vous devez savoir sur son histoire, son fonctionnement et ses secteurs d’application !
Au début des années 1990, les chercheurs en traitement de l’image et vision par ordinateur Dorin Comaniciu et Peter Meer cherchaient à relever les défis liés à la segmentation d’images et au suivi d’objets.
À l’époque, les méthodes traditionnelles basées sur des seuils ou des modèles statistiques étaient limitées dans leur capacité à gérer des objets aux formes et textures complexes ou des variations d’éclairage et de fond.
Pour remédier à ce problème, les deux chercheurs ont inventé une puissante méthode qui est encore aujourd’hui très utilisée pour la Computer Vision et l’analyse de données : l’algorithme Mean Shift.
Qu’est-ce que MeanShift ?
Dans le cadre de leurs travaux, Comaniciu et Meer ont compris que le décalage moyen (Mean Shift) pouvait être utilisé pour la recherche de régions d’intérêt dans une image.
Cette technique consiste à déplacer itérativement les points de données vers les régions de densité maximale, en utilisant une fenêtre de recherche et un noyau.
Le but est de déterminer à la fois l’étendue de la recherche et la manière dont les points sont déplacés. La densité des points est évaluée dans une région autour d’un point défini par la fenêtre de recherche.
De son côté, le noyau spécifie la forme de la distribution de densité utilisée pour évaluer la proximité des points. Ce sont ces deux éléments qui permettent à l’algorithme Mean Shift de trouver les modes locaux dans une distribution de données.
Une technique essentielle de vision par ordinateur
Les deux chercheurs ont donc décidé d’utiliser ce principe pour la vision par ordinateur, afin de regrouper les points similaires d’une image ensemble pour détecter les régions distinctes.
Cette approche s’est avérée très efficace, puisqu’elle permet d’identifier automatiquement les zones d’intérêt sans avoir besoin de seuils ou de modèles préalables.
De nos jours, Mean Shift est toujours utilisé pour la segmentation d’images en se basant sur les niveaux de couleur ou de texture. On l’exploite aussi pour la détection d’objets par le regroupement de régions similaires dans une scène.
Cet algorithme est aussi appliqué dans le traitement d’images pour améliorer les images en réduisant le bruit et en améliorant la netteté des contours. Il peut également être exploité pour le suivi d’objets en mouvement dans une séquence d’images.

MeanShift et l’analyse de données
Outre la computer vision, cette technique est aussi très utilisée pour l’analyse de données. Par exemple, elle permet de segmenter les cartes et les images satellites ou de détecter les clusters d’activité humaine pour les données géospatiales.
Le secteur du marketing utilise aussi Mean Shift pour segmenter les clients en fonction de leurs comportements d’achat et de leurs préférences. Ceci permet de mieux cibler les campagnes et personnaliser les offres.
Dans le domaine des réseaux sociaux, Mean Shift permet d’identifier les communautés ou les groupes d’individus ayant des interactions similaires. Ceci peut aider à comprendre les structures et les dynamiques sociales au sein de ces plateformes.
Plusieurs secteurs comme la cybersécurité, la finance ou la vidéo-surveillance appliquent aussi cet algorithme afin de détecter les comportements anormaux comme une fraude ou une intrusion.
Pour l’analyse de données biomédicales, Mean Shift permet la segmentation d’images médicales en vue d’une détection de pathologies ou pour l’analyse de signaux électroencéphalographiques.
Il est même possible de se servir de cette technique pour regrouper des documents textuels en fonction de leur sémantique, notamment pour organiser de grandes collections ou recommander des contenus similaires.
Comment utiliser MeanShift ?
L’algorithme Mean Shift repose sur plusieurs étapes clés. Tout d’abord, les données doivent être formatées et pré-traitées pour sélectionner les caractéristiques appropriées et éviter tout biais dans les résultats.
On sélectionne ensuite les centroïdes initiaux à partir des données elles-mêmes ou de manière aléatoire. Ils servent de points de départ pour les itérations de l’algorithme.
Vient ensuite l’étape d’itération, au cours de laquelle les points sont déplacés en fonction de la densité des points environnants. Les centroïdes sont à mis à jour à chaque fois et les points sont déplacés en direction des régions de densité maximale.
Cette itération continue jusqu’à ce que les points convergent vers les modes locaux et que les centroïdes ne se déplacent plus de manière significative.
Différents critères de convergence peuvent être utilisés, tels que la distance entre les centroïdes successifs ou la diminution de la variation totale.
L’un des paramètres clés de cet algorithme est la taille de la fenêtre de recherche. Elle influence la distance maximale sur laquelle les points sont déplacés, et peut avoir un impact significatif sur les résultats du clustering.
Choisir une taille de fenêtre optimale est donc essentiel. Il est possible d’utiliser la méthode du coudé ou des techniques de validation croisée pour évaluer la qualité du clustering pour différentes tailles et identifier celle qui maximise la cohérence des clusters.
Le type de noyau doit aussi être sélectionné en fonction des caractéristiques des données et des résultats souhaités. Les plus couramment utilisés sont gaussien et uniforme. Ce choix affecte la manière dont la densité est estimée, et donc la forme et la taille des clusters obtenus.
Cet ajustement des paramètres est essentiel. Vous pouvez procéder à des expérimentations en évaluant les performances du clustering à l’aide de mesures d’évaluation comme l’indice de silhouette ou l’inertie intra-cluster.
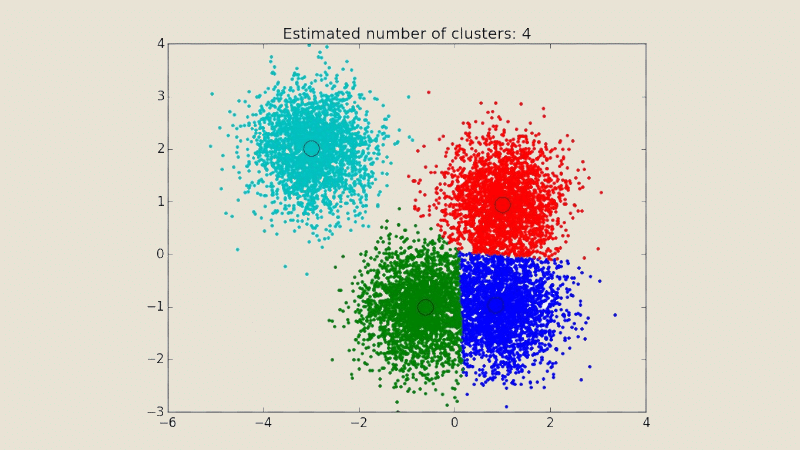
Quels sont les autres algorithmes de clustering ?
Il existe plusieurs autres algorithmes de clustering. Par rapport à K-Means, MeanShift est plus adapté aux données avec des formes de clusters non convexes et de tailles variables.
Pour cause, il n’est pas nécessaire de spécifier le nombre de clusters à l’avance puisqu’il peut être identifié automatiquement en trouvant les modes locaux dans les données. C’est ce qui rend MeanShift plus flexible et adaptatif aux données réelles.
De même, en comparaison avec DBSCAN, cet algorithme ne nécessite pas de paramètres tels que le rayon de voisinage ou le nombre minimum de points pour former un cluster.
Il est capable de trouver les clusters en se basant uniquement sur la densité des points et en utilisant la fenêtre de recherche adaptative. Toutefois, DBSCAN peut être plus approprié pour des ensembles de données à densité variable et pour détecter les valeurs aberrantes.
Autre différence importante de Mean Shift : sa nature non paramétrique. Il peut s’adapter à différents types de données sans hypothèses préalables.
Il n’a donc pas besoin de supposer de formes de clusters spécifiques ou de densité uniformes. Là encore, ceci permet une meilleure adaptation aux structures complexes et aux données non linéaires.
Conclusion : MeanShift, un algorithme incontournable en vision par ordinateur et analyse de données
Le clustering est une technique essentielle de l’analyse de données, afin de regrouper ensemble des observations similaires.
Or, l’algorithme Mean Shift est une méthode populaire en raison de son approche non paramétrique et sa capacité à identifier les modes locaux.
Il s’agit d’une approche puissante et flexible, pouvant être appliquée dans une large variété de domaines.
Afin d’apprendre à maîtriser tous les techniques et outils d’analyse de données, vous pouvez choisir DataScientest.
Nos différentes formations permettent d’acquérir toutes les compétences requises pour exercer les métiers Data Analyst, Data Scientist, Data Engineer, ML Engineer ou Data Product Manager.
Vous découvrirez le langage de programmation Python, les logiciels de DataViz, les outils d’analyse et manipulation de bases de données, la Business Intelligence ou encore le Machine Learning.
Nos cursus se complètent intégralement à distance et sont éligibles au CPF pour le financement. Vous pourrez aussi obtenir une certification décernée par MINES ParisTech PSL Education ou nos partenaires AWS et Microsoft Azure. Découvrez DataScientest !
Vous savez tout sur MeanShift. Pour plus d’informations, découvrez notre dossier complet sur la vision par ordinateur et notre dossier sur K-Means.








